 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJiuniu Wang
AesopAgent: Agent-driven Evolutionary System on Story-to-Video Production
Mar 12, 2024
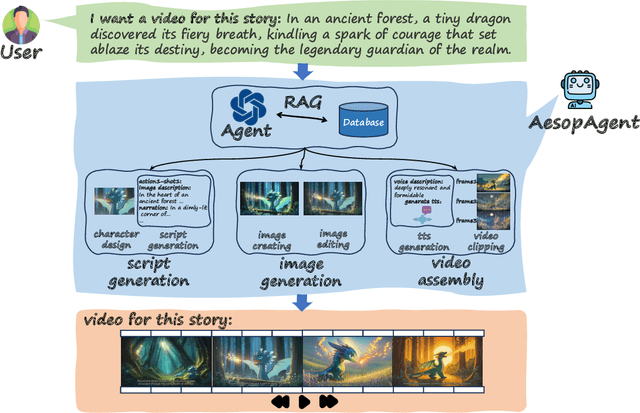

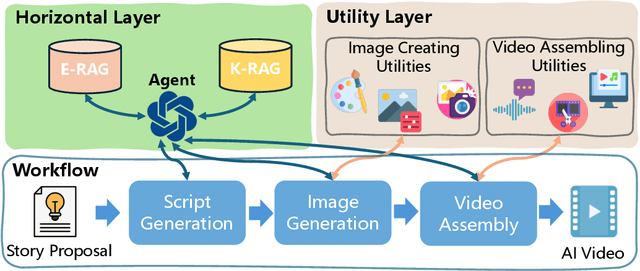
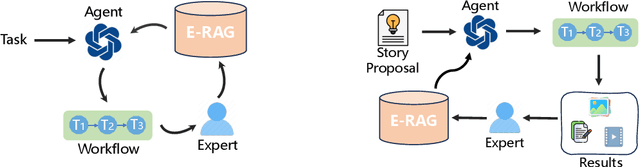
The Agent and AIGC (Artificial Intelligence Generated Content) technologies have recently made significant progress. We propose AesopAgent, an Agent-driven Evolutionary System on Story-to-Video Production. AesopAgent is a practical application of agent technology for multimodal content generation. The system integrates multiple generative capabilities within a unified framework, so that individual users can leverage these modules easily. This innovative system would convert user story proposals into scripts, images, and audio, and then integrate these multimodal contents into videos. Additionally, the animating units (e.g., Gen-2 and Sora) could make the videos more infectious. The AesopAgent system could orchestrate task workflow for video generation, ensuring that the generated video is both rich in content and coherent. This system mainly contains two layers, i.e., the Horizontal Layer and the Utility Layer. In the Horizontal Layer, we introduce a novel RAG-based evolutionary system that optimizes the whole video generation workflow and the steps within the workflow. It continuously evolves and iteratively optimizes workflow by accumulating expert experience and professional knowledge, including optimizing the LLM prompts and utilities usage. The Utility Layer provides multiple utilities, leading to consistent image generation that is visually coherent in terms of composition, characters, and style. Meanwhile, it provides audio and special effects, integrating them into expressive and logically arranged videos. Overall, our AesopAgent achieves state-of-the-art performance compared with many previous works in visual storytelling. Our AesopAgent is designed for convenient service for individual users, which is available on the following page: https://aesopai.github.io/.
Deep Semantic-Visual Alignment for Zero-Shot Remote Sensing Image Scene Classification
Feb 03, 2024Deep neural networks have achieved promising progress in remote sensing (RS) image classification, for which the training process requires abundant samples for each class. However, it is time-consuming and unrealistic to annotate labels for each RS category, given the fact that the RS target database is increasing dynamically. Zero-shot learning (ZSL) allows for identifying novel classes that are not seen during training, which provides a promising solution for the aforementioned problem. However, previous ZSL models mainly depend on manually-labeled attributes or word embeddings extracted from language models to transfer knowledge from seen classes to novel classes. Besides, pioneer ZSL models use convolutional neural networks pre-trained on ImageNet, which focus on the main objects appearing in each image, neglecting the background context that also matters in RS scene classification. To address the above problems, we propose to collect visually detectable attributes automatically. We predict attributes for each class by depicting the semantic-visual similarity between attributes and images. In this way, the attribute annotation process is accomplished by machine instead of human as in other methods. Moreover, we propose a Deep Semantic-Visual Alignment (DSVA) that take advantage of the self-attention mechanism in the transformer to associate local image regions together, integrating the background context information for prediction. The DSVA model further utilizes the attribute attention maps to focus on the informative image regions that are essential for knowledge transfer in ZSL, and maps the visual images into attribute space to perform ZSL classification. With extensive experiments, we show that our model outperforms other state-of-the-art models by a large margin on a challenging large-scale RS scene classification benchmark.
* Published in ISPRS P&RS. The code is available at https://github.com/wenjiaXu/RS_Scene_ZSL
Jointly Optimized Global-Local Visual Localization of UAVs
Oct 12, 2023Navigation and localization of UAVs present a challenge when global navigation satellite systems (GNSS) are disrupted and unreliable. Traditional techniques, such as simultaneous localization and mapping (SLAM) and visual odometry (VO), exhibit certain limitations in furnishing absolute coordinates and mitigating error accumulation. Existing visual localization methods achieve autonomous visual localization without error accumulation by matching with ortho satellite images. However, doing so cannot guarantee real-time performance due to the complex matching process. To address these challenges, we propose a novel Global-Local Visual Localization (GLVL) network. Our GLVL network is a two-stage visual localization approach, combining a large-scale retrieval module that finds similar regions with the UAV flight scene, and a fine-grained matching module that localizes the precise UAV coordinate, enabling real-time and precise localization. The training process is jointly optimized in an end-to-end manner to further enhance the model capability. Experiments on six UAV flight scenes encompassing both texture-rich and texture-sparse regions demonstrate the ability of our model to achieve the real-time precise localization requirements of UAVs. Particularly, our method achieves a localization error of only 2.39 meters in 0.48 seconds in a village scene with sparse texture features.
ModelScope Text-to-Video Technical Report
Aug 12, 2023



This paper introduces ModelScopeT2V, a text-to-video synthesis model that evolves from a text-to-image synthesis model (i.e., Stable Diffusion). ModelScopeT2V incorporates spatio-temporal blocks to ensure consistent frame generation and smooth movement transitions. The model could adapt to varying frame numbers during training and inference, rendering it suitable for both image-text and video-text datasets. ModelScopeT2V brings together three components (i.e., VQGAN, a text encoder, and a denoising UNet), totally comprising 1.7 billion parameters, in which 0.5 billion parameters are dedicated to temporal capabilities. The model demonstrates superior performance over state-of-the-art methods across three evaluation metrics. The code and an online demo are available at \url{https://modelscope.cn/models/damo/text-to-video-synthesis/summary}.
VideoComposer: Compositional Video Synthesis with Motion Controllability
Jun 06, 2023



The pursuit of controllability as a higher standard of visual content creation has yielded remarkable progress in customizable image synthesis. However, achieving controllable video synthesis remains challenging due to the large variation of temporal dynamics and the requirement of cross-frame temporal consistency. Based on the paradigm of compositional generation, this work presents VideoComposer that allows users to flexibly compose a video with textual conditions, spatial conditions, and more importantly temporal conditions. Specifically, considering the characteristic of video data, we introduce the motion vector from compressed videos as an explicit control signal to provide guidance regarding temporal dynamics. In addition, we develop a Spatio-Temporal Condition encoder (STC-encoder) that serves as a unified interface to effectively incorporate the spatial and temporal relations of sequential inputs, with which the model could make better use of temporal conditions and hence achieve higher inter-frame consistency. Extensive experimental results suggest that VideoComposer is able to control the spatial and temporal patterns simultaneously within a synthesized video in various forms, such as text description, sketch sequence, reference video, or even simply hand-crafted motions. The code and models will be publicly available at https://videocomposer.github.io.
Distinctive Image Captioning via CLIP Guided Group Optimization
Aug 14, 2022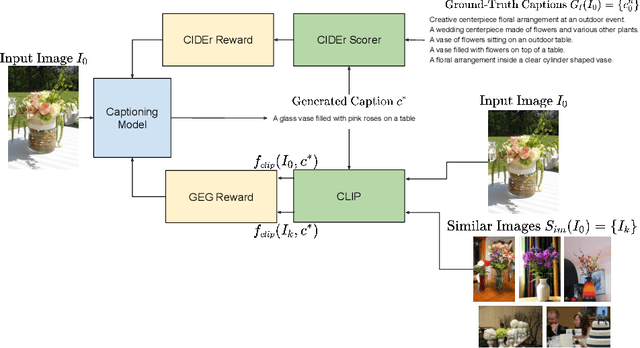
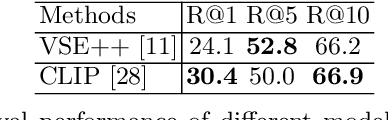
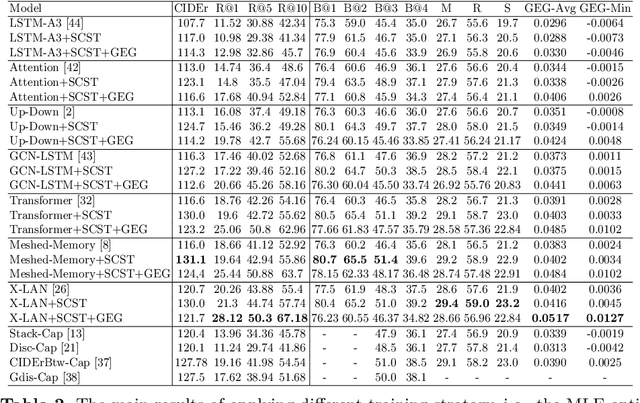

Image captioning models are usually trained according to human annotated ground-truth captions, which could generate accurate but generic captions. In this paper, we focus on generating the distinctive captions that can distinguish the target image from other similar images. To evaluate the distinctiveness of captions, we introduce a series of metrics that use large-scale vision-language pre-training model CLIP to quantify the distinctiveness. To further improve the distinctiveness of captioning models, we propose a simple and effective training strategy which trains the model by comparing target image with similar image group and optimizing the group embedding gap. Extensive experiments are conducted on various baseline models to demonstrate the wide applicability of our strategy and the consistency of metric results with human evaluation. By comparing the performance of our best model with existing state-of-the-art models, we claim that our model achieves new state-of-the-art towards distinctiveness objective.
Multi-dimension Geospatial feature learning for urban region function recognition
Jul 18, 2022



Urban region function recognition plays a vital character in monitoring and managing the limited urban areas. Since urban functions are complex and full of social-economic properties, simply using remote sensing~(RS) images equipped with physical and optical information cannot completely solve the classification task. On the other hand, with the development of mobile communication and the internet, the acquisition of geospatial big data~(GBD) becomes possible. In this paper, we propose a Multi-dimension Feature Learning Model~(MDFL) using high-dimensional GBD data in conjunction with RS images for urban region function recognition. When extracting multi-dimension features, our model considers the user-related information modeled by their activity, as well as the region-based information abstracted from the region graph. Furthermore, we propose a decision fusion network that integrates the decisions from several neural networks and machine learning classifiers, and the final decision is made considering both the visual cue from the RS images and the social information from the GBD data. Through quantitative evaluation, we demonstrate that our model achieves overall accuracy at 92.75, outperforming the state-of-the-art by 10 percent.
On Distinctive Image Captioning via Comparing and Reweighting
Apr 08, 2022
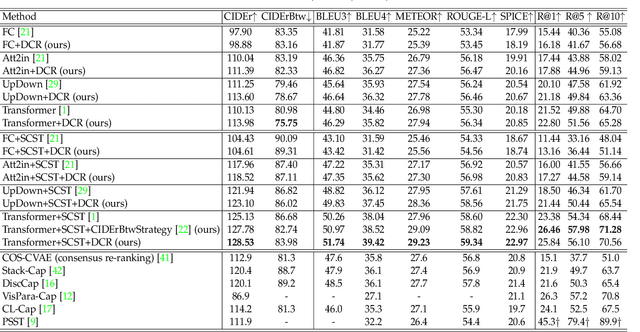
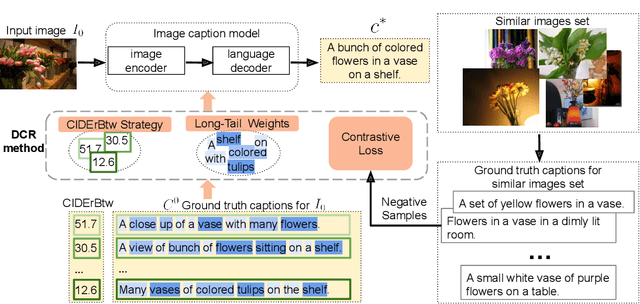
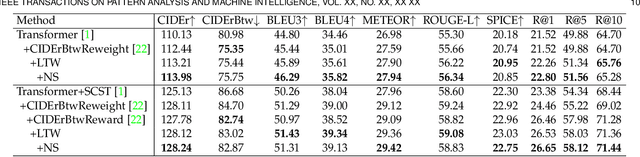
Recent image captioning models are achieving impressive results based on popular metrics, i.e., BLEU, CIDEr, and SPICE. However, focusing on the most popular metrics that only consider the overlap between the generated captions and human annotation could result in using common words and phrases, which lacks distinctiveness, i.e., many similar images have the same caption. In this paper, we aim to improve the distinctiveness of image captions via comparing and reweighting with a set of similar images. First, we propose a distinctiveness metric -- between-set CIDEr (CIDErBtw) to evaluate the distinctiveness of a caption with respect to those of similar images. Our metric reveals that the human annotations of each image in the MSCOCO dataset are not equivalent based on distinctiveness; however, previous works normally treat the human annotations equally during training, which could be a reason for generating less distinctive captions. In contrast, we reweight each ground-truth caption according to its distinctiveness during training. We further integrate a long-tailed weight strategy to highlight the rare words that contain more information, and captions from the similar image set are sampled as negative examples to encourage the generated sentence to be unique. Finally, extensive experiments are conducted, showing that our proposed approach significantly improves both distinctiveness (as measured by CIDErBtw and retrieval metrics) and accuracy (e.g., as measured by CIDEr) for a wide variety of image captioning baselines. These results are further confirmed through a user study.
* 20 pages. arXiv admin note: substantial text overlap with arXiv:2007.06877
Attribute Prototype Network for Any-Shot Learning
Apr 04, 2022



Any-shot image classification allows to recognize novel classes with only a few or even zero samples. For the task of zero-shot learning, visual attributes have been shown to play an important role, while in the few-shot regime, the effect of attributes is under-explored. To better transfer attribute-based knowledge from seen to unseen classes, we argue that an image representation with integrated attribute localization ability would be beneficial for any-shot, i.e. zero-shot and few-shot, image classification tasks. To this end, we propose a novel representation learning framework that jointly learns discriminative global and local features using only class-level attributes. While a visual-semantic embedding layer learns global features, local features are learned through an attribute prototype network that simultaneously regresses and decorrelates attributes from intermediate features. Furthermore, we introduce a zoom-in module that localizes and crops the informative regions to encourage the network to learn informative features explicitly. We show that our locality augmented image representations achieve a new state-of-the-art on challenging benchmarks, i.e. CUB, AWA2, and SUN. As an additional benefit, our model points to the visual evidence of the attributes in an image, confirming the improved attribute localization ability of our image representation. The attribute localization is evaluated quantitatively with ground truth part annotations, qualitatively with visualizations, and through well-designed user studies.
VGSE: Visually-Grounded Semantic Embeddings for Zero-Shot Learning
Mar 20, 2022



Human-annotated attributes serve as powerful semantic embeddings in zero-shot learning. However, their annotation process is labor-intensive and needs expert supervision. Current unsupervised semantic embeddings, i.e., word embeddings, enable knowledge transfer between classes. However, word embeddings do not always reflect visual similarities and result in inferior zero-shot performance. We propose to discover semantic embeddings containing discriminative visual properties for zero-shot learning, without requiring any human annotation. Our model visually divides a set of images from seen classes into clusters of local image regions according to their visual similarity, and further imposes their class discrimination and semantic relatedness. To associate these clusters with previously unseen classes, we use external knowledge, e.g., word embeddings and propose a novel class relation discovery module. Through quantitative and qualitative evaluation, we demonstrate that our model discovers semantic embeddings that model the visual properties of both seen and unseen classes. Furthermore, we demonstrate on three benchmarks that our visually-grounded semantic embeddings further improve performance over word embeddings across various ZSL models by a large margin.