 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHangjie Yuan
Revisiting Neural Networks for Continual Learning: An Architectural Perspective
Apr 28, 2024
Efforts to overcome catastrophic forgetting have primarily centered around developing more effective Continual Learning (CL) methods. In contrast, less attention was devoted to analyzing the role of network architecture design (e.g., network depth, width, and components) in contributing to CL. This paper seeks to bridge this gap between network architecture design and CL, and to present a holistic study on the impact of network architectures on CL. This work considers architecture design at the network scaling level, i.e., width and depth, and also at the network components, i.e., skip connections, global pooling layers, and down-sampling. In both cases, we first derive insights through systematically exploring how architectural designs affect CL. Then, grounded in these insights, we craft a specialized search space for CL and further propose a simple yet effective ArchCraft method to steer a CL-friendly architecture, namely, this method recrafts AlexNet/ResNet into AlexAC/ResAC. Experimental validation across various CL settings and scenarios demonstrates that improved architectures are parameter-efficient, achieving state-of-the-art performance of CL while being 86%, 61%, and 97% more compact in terms of parameters than the naive CL architecture in Task IL and Class IL. Code is available at https://github.com/byyx666/ArchCraft.
Make Continual Learning Stronger via C-Flat
Apr 01, 2024Model generalization ability upon incrementally acquiring dynamically updating knowledge from sequentially arriving tasks is crucial to tackle the sensitivity-stability dilemma in Continual Learning (CL). Weight loss landscape sharpness minimization seeking for flat minima lying in neighborhoods with uniform low loss or smooth gradient is proven to be a strong training regime improving model generalization compared with loss minimization based optimizer like SGD. Yet only a few works have discussed this training regime for CL, proving that dedicated designed zeroth-order sharpness optimizer can improve CL performance. In this work, we propose a Continual Flatness (C-Flat) method featuring a flatter loss landscape tailored for CL. C-Flat could be easily called with only one line of code and is plug-and-play to any CL methods. A general framework of C-Flat applied to all CL categories and a thorough comparison with loss minima optimizer and flat minima based CL approaches is presented in this paper, showing that our method can boost CL performance in almost all cases. Code will be publicly available upon publication.
LUM-ViT: Learnable Under-sampling Mask Vision Transformer for Bandwidth Limited Optical Signal Acquisition
Mar 03, 2024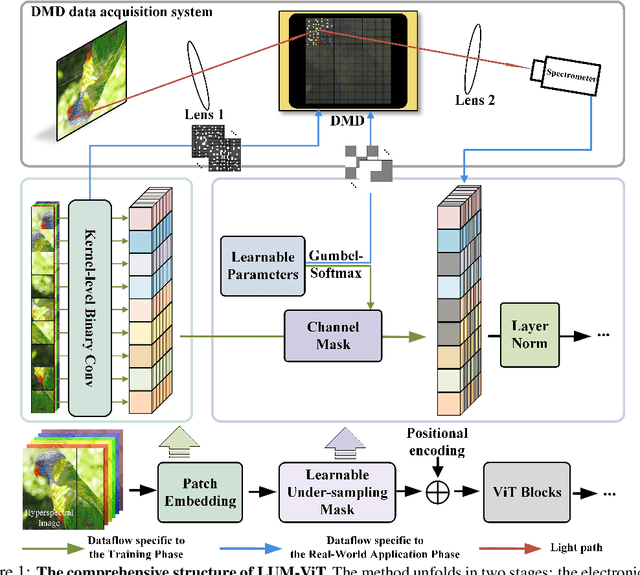

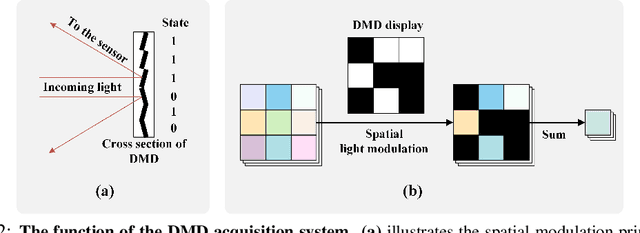
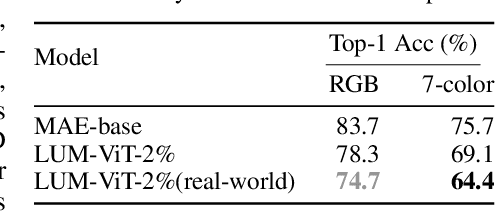
Bandwidth constraints during signal acquisition frequently impede real-time detection applications. Hyperspectral data is a notable example, whose vast volume compromises real-time hyperspectral detection. To tackle this hurdle, we introduce a novel approach leveraging pre-acquisition modulation to reduce the acquisition volume. This modulation process is governed by a deep learning model, utilizing prior information. Central to our approach is LUM-ViT, a Vision Transformer variant. Uniquely, LUM-ViT incorporates a learnable under-sampling mask tailored for pre-acquisition modulation. To further optimize for optical calculations, we propose a kernel-level weight binarization technique and a three-stage fine-tuning strategy. Our evaluations reveal that, by sampling a mere 10% of the original image pixels, LUM-ViT maintains the accuracy loss within 1.8% on the ImageNet classification task. The method sustains near-original accuracy when implemented on real-world optical hardware, demonstrating its practicality. Code will be available at https://github.com/MaxLLF/LUM-ViT.
A Recipe for Scaling up Text-to-Video Generation with Text-free Videos
Dec 25, 2023Diffusion-based text-to-video generation has witnessed impressive progress in the past year yet still falls behind text-to-image generation. One of the key reasons is the limited scale of publicly available data (e.g., 10M video-text pairs in WebVid10M vs. 5B image-text pairs in LAION), considering the high cost of video captioning. Instead, it could be far easier to collect unlabeled clips from video platforms like YouTube. Motivated by this, we come up with a novel text-to-video generation framework, termed TF-T2V, which can directly learn with text-free videos. The rationale behind is to separate the process of text decoding from that of temporal modeling. To this end, we employ a content branch and a motion branch, which are jointly optimized with weights shared. Following such a pipeline, we study the effect of doubling the scale of training set (i.e., video-only WebVid10M) with some randomly collected text-free videos and are encouraged to observe the performance improvement (FID from 9.67 to 8.19 and FVD from 484 to 441), demonstrating the scalability of our approach. We also find that our model could enjoy sustainable performance gain (FID from 8.19 to 7.64 and FVD from 441 to 366) after reintroducing some text labels for training. Finally, we validate the effectiveness and generalizability of our ideology on both native text-to-video generation and compositional video synthesis paradigms. Code and models will be publicly available at https://tf-t2v.github.io/.
InstructVideo: Instructing Video Diffusion Models with Human Feedback
Dec 19, 2023Diffusion models have emerged as the de facto paradigm for video generation. However, their reliance on web-scale data of varied quality often yields results that are visually unappealing and misaligned with the textual prompts. To tackle this problem, we propose InstructVideo to instruct text-to-video diffusion models with human feedback by reward fine-tuning. InstructVideo has two key ingredients: 1) To ameliorate the cost of reward fine-tuning induced by generating through the full DDIM sampling chain, we recast reward fine-tuning as editing. By leveraging the diffusion process to corrupt a sampled video, InstructVideo requires only partial inference of the DDIM sampling chain, reducing fine-tuning cost while improving fine-tuning efficiency. 2) To mitigate the absence of a dedicated video reward model for human preferences, we repurpose established image reward models, e.g., HPSv2. To this end, we propose Segmental Video Reward, a mechanism to provide reward signals based on segmental sparse sampling, and Temporally Attenuated Reward, a method that mitigates temporal modeling degradation during fine-tuning. Extensive experiments, both qualitative and quantitative, validate the practicality and efficacy of using image reward models in InstructVideo, significantly enhancing the visual quality of generated videos without compromising generalization capabilities. Code and models will be made publicly available.
DreamVideo: Composing Your Dream Videos with Customized Subject and Motion
Dec 07, 2023Customized generation using diffusion models has made impressive progress in image generation, but remains unsatisfactory in the challenging video generation task, as it requires the controllability of both subjects and motions. To that end, we present DreamVideo, a novel approach to generating personalized videos from a few static images of the desired subject and a few videos of target motion. DreamVideo decouples this task into two stages, subject learning and motion learning, by leveraging a pre-trained video diffusion model. The subject learning aims to accurately capture the fine appearance of the subject from provided images, which is achieved by combining textual inversion and fine-tuning of our carefully designed identity adapter. In motion learning, we architect a motion adapter and fine-tune it on the given videos to effectively model the target motion pattern. Combining these two lightweight and efficient adapters allows for flexible customization of any subject with any motion. Extensive experimental results demonstrate the superior performance of our DreamVideo over the state-of-the-art methods for customized video generation. Our project page is at https://dreamvideo-t2v.github.io.
I2VGen-XL: High-Quality Image-to-Video Synthesis via Cascaded Diffusion Models
Nov 07, 2023Video synthesis has recently made remarkable strides benefiting from the rapid development of diffusion models. However, it still encounters challenges in terms of semantic accuracy, clarity and spatio-temporal continuity. They primarily arise from the scarcity of well-aligned text-video data and the complex inherent structure of videos, making it difficult for the model to simultaneously ensure semantic and qualitative excellence. In this report, we propose a cascaded I2VGen-XL approach that enhances model performance by decoupling these two factors and ensures the alignment of the input data by utilizing static images as a form of crucial guidance. I2VGen-XL consists of two stages: i) the base stage guarantees coherent semantics and preserves content from input images by using two hierarchical encoders, and ii) the refinement stage enhances the video's details by incorporating an additional brief text and improves the resolution to 1280$\times$720. To improve the diversity, we collect around 35 million single-shot text-video pairs and 6 billion text-image pairs to optimize the model. By this means, I2VGen-XL can simultaneously enhance the semantic accuracy, continuity of details and clarity of generated videos. Through extensive experiments, we have investigated the underlying principles of I2VGen-XL and compared it with current top methods, which can demonstrate its effectiveness on diverse data. The source code and models will be publicly available at \url{https://i2vgen-xl.github.io}.
From Denoising Training to Test-Time Adaptation: Enhancing Domain Generalization for Medical Image Segmentation
Nov 03, 2023In medical image segmentation, domain generalization poses a significant challenge due to domain shifts caused by variations in data acquisition devices and other factors. These shifts are particularly pronounced in the most common scenario, which involves only single-source domain data due to privacy concerns. To address this, we draw inspiration from the self-supervised learning paradigm that effectively discourages overfitting to the source domain. We propose the Denoising Y-Net (DeY-Net), a novel approach incorporating an auxiliary denoising decoder into the basic U-Net architecture. The auxiliary decoder aims to perform denoising training, augmenting the domain-invariant representation that facilitates domain generalization. Furthermore, this paradigm provides the potential to utilize unlabeled data. Building upon denoising training, we propose Denoising Test Time Adaptation (DeTTA) that further: (i) adapts the model to the target domain in a sample-wise manner, and (ii) adapts to the noise-corrupted input. Extensive experiments conducted on widely-adopted liver segmentation benchmarks demonstrate significant domain generalization improvements over our baseline and state-of-the-art results compared to other methods. Code is available at https://github.com/WenRuxue/DeTTA.
Few-shot Action Recognition with Captioning Foundation Models
Oct 16, 2023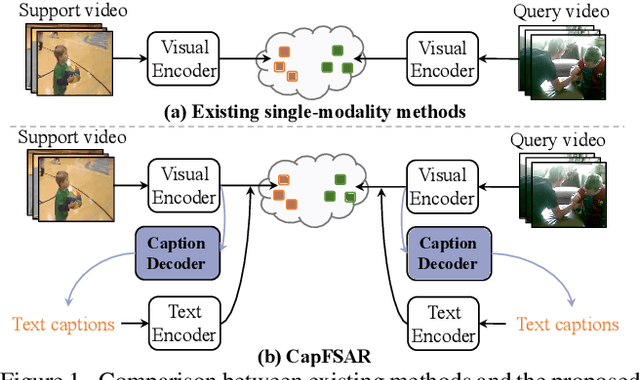
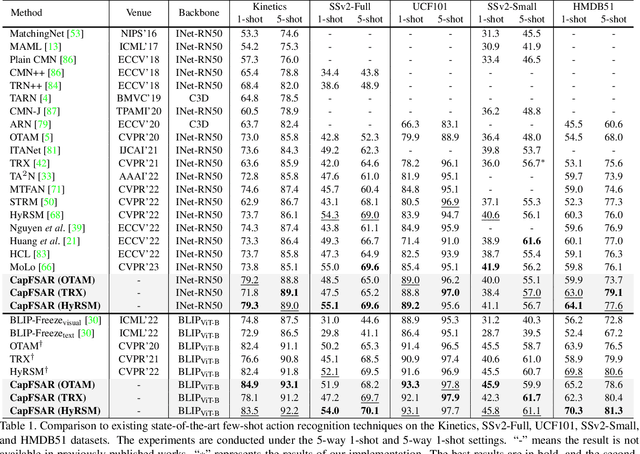
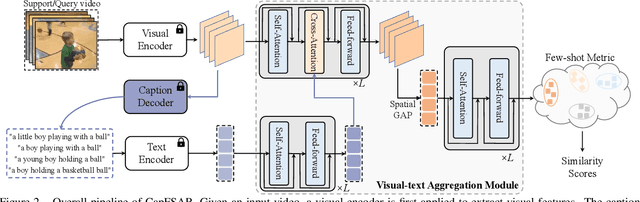
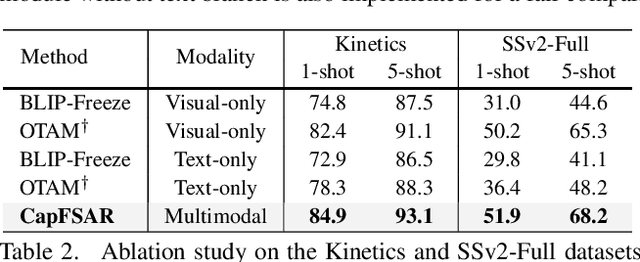
Transferring vision-language knowledge from pretrained multimodal foundation models to various downstream tasks is a promising direction. However, most current few-shot action recognition methods are still limited to a single visual modality input due to the high cost of annotating additional textual descriptions. In this paper, we develop an effective plug-and-play framework called CapFSAR to exploit the knowledge of multimodal models without manually annotating text. To be specific, we first utilize a captioning foundation model (i.e., BLIP) to extract visual features and automatically generate associated captions for input videos. Then, we apply a text encoder to the synthetic captions to obtain representative text embeddings. Finally, a visual-text aggregation module based on Transformer is further designed to incorporate cross-modal spatio-temporal complementary information for reliable few-shot matching. In this way, CapFSAR can benefit from powerful multimodal knowledge of pretrained foundation models, yielding more comprehensive classification in the low-shot regime. Extensive experiments on multiple standard few-shot benchmarks demonstrate that the proposed CapFSAR performs favorably against existing methods and achieves state-of-the-art performance. The code will be made publicly available.
RLIPv2: Fast Scaling of Relational Language-Image Pre-training
Aug 18, 2023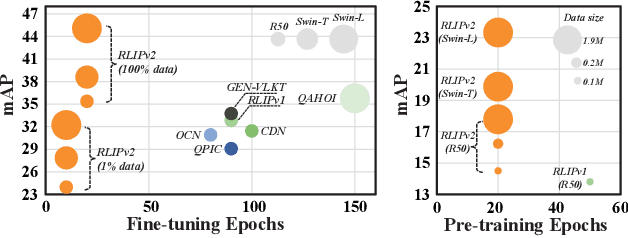
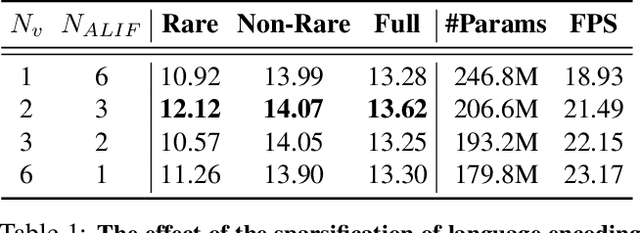
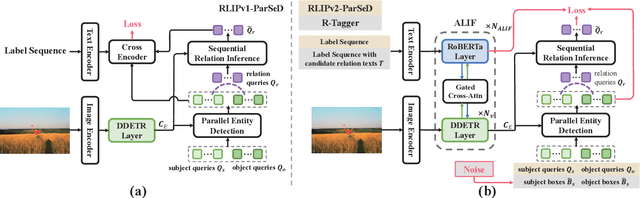
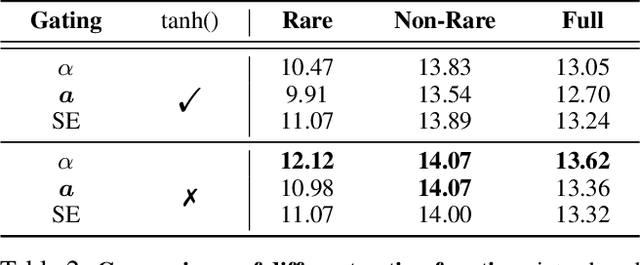
Relational Language-Image Pre-training (RLIP) aims to align vision representations with relational texts, thereby advancing the capability of relational reasoning in computer vision tasks. However, hindered by the slow convergence of RLIPv1 architecture and the limited availability of existing scene graph data, scaling RLIPv1 is challenging. In this paper, we propose RLIPv2, a fast converging model that enables the scaling of relational pre-training to large-scale pseudo-labelled scene graph data. To enable fast scaling, RLIPv2 introduces Asymmetric Language-Image Fusion (ALIF), a mechanism that facilitates earlier and deeper gated cross-modal fusion with sparsified language encoding layers. ALIF leads to comparable or better performance than RLIPv1 in a fraction of the time for pre-training and fine-tuning. To obtain scene graph data at scale, we extend object detection datasets with free-form relation labels by introducing a captioner (e.g., BLIP) and a designed Relation Tagger. The Relation Tagger assigns BLIP-generated relation texts to region pairs, thus enabling larger-scale relational pre-training. Through extensive experiments conducted on Human-Object Interaction Detection and Scene Graph Generation, RLIPv2 shows state-of-the-art performance on three benchmarks under fully-finetuning, few-shot and zero-shot settings. Notably, the largest RLIPv2 achieves 23.29mAP on HICO-DET without any fine-tuning, yields 32.22mAP with just 1% data and yields 45.09mAP with 100% data. Code and models are publicly available at https://github.com/JacobYuan7/RLIPv2.