 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHongming Shan
Low-dose CT Denoising with Language-engaged Dual-space Alignment
Mar 10, 2024
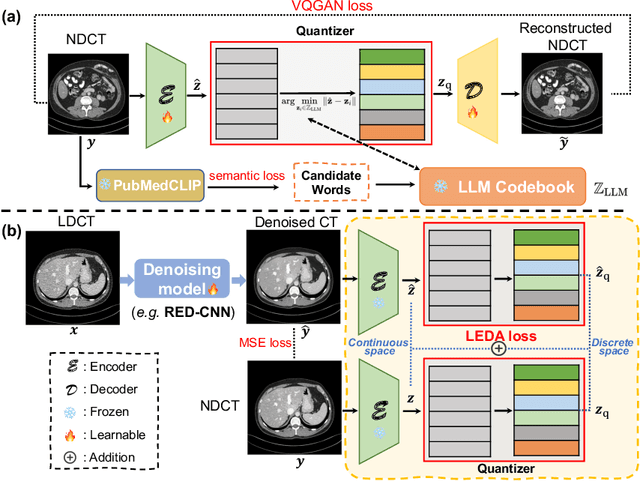
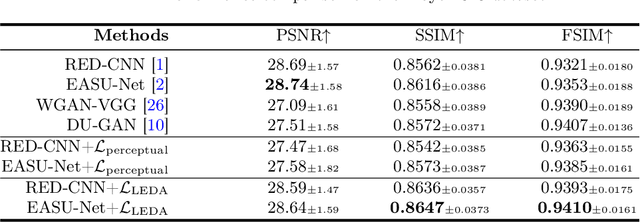
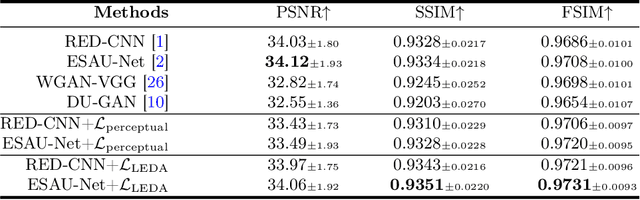
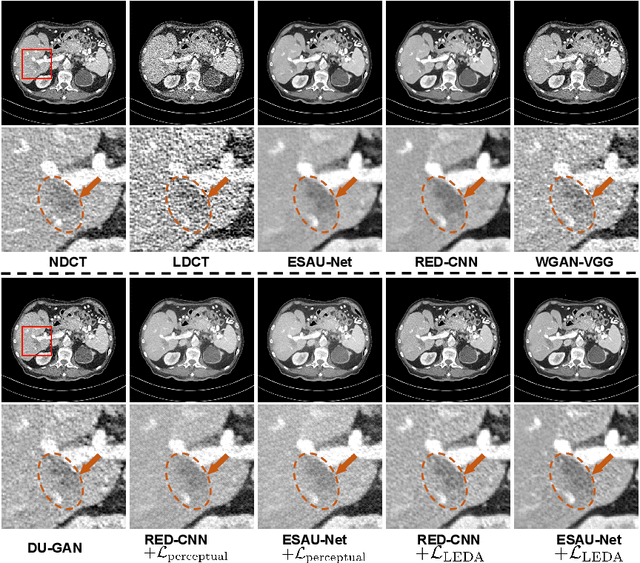
While various deep learning methods were proposed for low-dose computed tomography (CT) denoising, they often suffer from over-smoothing, blurring, and lack of explainability. To alleviate these issues, we propose a plug-and-play Language-Engaged Dual-space Alignment loss (LEDA) to optimize low-dose CT denoising models. Our idea is to leverage large language models (LLMs) to align denoised CT and normal dose CT images in both the continuous perceptual space and discrete semantic space, which is the first LLM-based scheme for low-dose CT denoising. LEDA involves two steps: the first is to pretrain an LLM-guided CT autoencoder, which can encode a CT image into continuous high-level features and quantize them into a token space to produce semantic tokens derived from the LLM's vocabulary; and the second is to minimize the discrepancy between the denoised CT images and normal dose CT in terms of both encoded high-level features and quantized token embeddings derived by the LLM-guided CT autoencoder. Extensive experimental results on two public LDCT denoising datasets demonstrate that our LEDA can enhance existing denoising models in terms of quantitative metrics and qualitative evaluation, and also provide explainability through language-level image understanding. Source code is available at https://github.com/hao1635/LEDA.
HOPE: Hybrid-granularity Ordinal Prototype Learning for Progression Prediction of Mild Cognitive Impairment
Jan 19, 2024Mild cognitive impairment (MCI) is often at high risk of progression to Alzheimer's disease (AD). Existing works to identify the progressive MCI (pMCI) typically require MCI subtype labels, pMCI vs. stable MCI (sMCI), determined by whether or not an MCI patient will progress to AD after a long follow-up. However, prospectively acquiring MCI subtype data is time-consuming and resource-intensive; the resultant small datasets could lead to severe overfitting and difficulty in extracting discriminative information. Inspired by that various longitudinal biomarkers and cognitive measurements present an ordinal pathway on AD progression, we propose a novel Hybrid-granularity Ordinal PrototypE learning (HOPE) method to characterize AD ordinal progression for MCI progression prediction. First, HOPE learns an ordinal metric space that enables progression prediction by prototype comparison. Second, HOPE leverages a novel hybrid-granularity ordinal loss to learn the ordinal nature of AD via effectively integrating instance-to-instance ordinality, instance-to-class compactness, and class-to-class separation. Third, to make the prototype learning more stable, HOPE employs an exponential moving average strategy to learn the global prototypes of NC and AD dynamically. Experimental results on the internal ADNI and the external NACC datasets demonstrate the superiority of the proposed HOPE over existing state-of-the-art methods as well as its interpretability. Source code is made available at https://github.com/thibault-wch/HOPE-for-mild-cognitive-impairment.
* IEEE Journal of Biomedical and Health Informatics, 2024
IQAGPT: Image Quality Assessment with Vision-language and ChatGPT Models
Dec 25, 2023Large language models (LLMs), such as ChatGPT, have demonstrated impressive capabilities in various tasks and attracted an increasing interest as a natural language interface across many domains. Recently, large vision-language models (VLMs) like BLIP-2 and GPT-4 have been intensively investigated, which learn rich vision-language correlation from image-text pairs. However, despite these developments, the application of LLMs and VLMs in image quality assessment (IQA), particularly in medical imaging, remains to be explored, which is valuable for objective performance evaluation and potential supplement or even replacement of radiologists' opinions. To this end, this paper introduces IQAGPT, an innovative image quality assessment system integrating an image quality captioning VLM with ChatGPT for generating quality scores and textual reports. First, we build a CT-IQA dataset for training and evaluation, comprising 1,000 CT slices with diverse quality levels professionally annotated. To better leverage the capabilities of LLMs, we convert annotated quality scores into semantically rich text descriptions using a prompt template. Second, we fine-tune the image quality captioning VLM on the CT-IQA dataset to generate quality descriptions. The captioning model fuses the image and text features through cross-modal attention. Third, based on the quality descriptions, users can talk with ChatGPT to rate image quality scores or produce a radiological quality report. Our preliminary results demonstrate the feasibility of assessing image quality with large models. Remarkably, our IQAGPT outperforms GPT-4 and CLIP-IQA, as well as the multi-task classification and regression models that solely rely on images.
Universal Incomplete-View CT Reconstruction with Prompted Contextual Transformer
Dec 13, 2023Despite the reduced radiation dose, suitability for objects with physical constraints, and accelerated scanning procedure, incomplete-view computed tomography (CT) images suffer from severe artifacts, hampering their value for clinical diagnosis. The incomplete-view CT can be divided into two scenarios depending on the sampling of projection, sparse-view CT and limited-angle CT, each encompassing various settings for different clinical requirements. Existing methods tackle with these settings separately and individually due to their significantly different artifact patterns; this, however, gives rise to high computational and storage costs, hindering its flexible adaptation to new settings. To address this challenge, we present the first-of-its-kind all-in-one incomplete-view CT reconstruction model with PROmpted Contextual Transformer, termed ProCT. More specifically, we first devise the projection view-aware prompting to provide setting-discriminative information, enabling a single model to handle diverse incomplete-view CT settings. Then, we propose artifact-aware contextual learning to provide the contextual guidance of image pairs from either CT phantom or publicly available datasets, making ProCT capable of accurately removing the complex artifacts from the incomplete-view CT images. Extensive experiments demonstrate that ProCT can achieve superior performance on a wide range of incomplete-view CT settings using a single model. Remarkably, our model with only image-domain information surpasses the state-of-the-art dual-domain methods that require the access to raw data. The code is available at: https://github.com/Masaaki-75/proct
Prompt-In-Prompt Learning for Universal Image Restoration
Dec 08, 2023Image restoration, which aims to retrieve and enhance degraded images, is fundamental across a wide range of applications. While conventional deep learning approaches have notably improved the image quality across various tasks, they still suffer from (i) the high storage cost needed for various task-specific models and (ii) the lack of interactivity and flexibility, hindering their wider application. Drawing inspiration from the pronounced success of prompts in both linguistic and visual domains, we propose novel Prompt-In-Prompt learning for universal image restoration, named PIP. First, we present two novel prompts, a degradation-aware prompt to encode high-level degradation knowledge and a basic restoration prompt to provide essential low-level information. Second, we devise a novel prompt-to-prompt interaction module to fuse these two prompts into a universal restoration prompt. Third, we introduce a selective prompt-to-feature interaction module to modulate the degradation-related feature. By doing so, the resultant PIP works as a plug-and-play module to enhance existing restoration models for universal image restoration. Extensive experimental results demonstrate the superior performance of PIP on multiple restoration tasks, including image denoising, deraining, dehazing, deblurring, and low-light enhancement. Remarkably, PIP is interpretable, flexible, efficient, and easy-to-use, showing promising potential for real-world applications. The code is available at https://github.com/longzilicart/pip_universal.
DreamVideo: Composing Your Dream Videos with Customized Subject and Motion
Dec 07, 2023Customized generation using diffusion models has made impressive progress in image generation, but remains unsatisfactory in the challenging video generation task, as it requires the controllability of both subjects and motions. To that end, we present DreamVideo, a novel approach to generating personalized videos from a few static images of the desired subject and a few videos of target motion. DreamVideo decouples this task into two stages, subject learning and motion learning, by leveraging a pre-trained video diffusion model. The subject learning aims to accurately capture the fine appearance of the subject from provided images, which is achieved by combining textual inversion and fine-tuning of our carefully designed identity adapter. In motion learning, we architect a motion adapter and fine-tune it on the given videos to effectively model the target motion pattern. Combining these two lightweight and efficient adapters allows for flexible customization of any subject with any motion. Extensive experimental results demonstrate the superior performance of our DreamVideo over the state-of-the-art methods for customized video generation. Our project page is at https://dreamvideo-t2v.github.io.
Point, Segment and Count: A Generalized Framework for Object Counting
Nov 27, 2023Class-agnostic object counting aims to count all objects in an image with respect to example boxes or class names, \emph{a.k.a} few-shot and zero-shot counting. Current state-of-the-art methods highly rely on density maps to predict object counts, which lacks model interpretability. In this paper, we propose a generalized framework for both few-shot and zero-shot object counting based on detection. Our framework combines the superior advantages of two foundation models without compromising their zero-shot capability: (\textbf{i}) SAM to segment all possible objects as mask proposals, and (\textbf{ii}) CLIP to classify proposals to obtain accurate object counts. However, this strategy meets the obstacles of efficiency overhead and the small crowded objects that cannot be localized and distinguished. To address these issues, our framework, termed PseCo, follows three steps: point, segment, and count. Specifically, we first propose a class-agnostic object localization to provide accurate but least point prompts for SAM, which consequently not only reduces computation costs but also avoids missing small objects. Furthermore, we propose a generalized object classification that leverages CLIP image/text embeddings as the classifier, following a hierarchical knowledge distillation to obtain discriminative classifications among hierarchical mask proposals. Extensive experimental results on FSC-147 dataset demonstrate that PseCo achieves state-of-the-art performance in both few-shot/zero-shot object counting/detection, with additional results on large-scale COCO and LVIS datasets. The source code is available at \url{https://github.com/Hzzone/PseCo}.
ViP-Mixer: A Convolutional Mixer for Video Prediction
Nov 20, 2023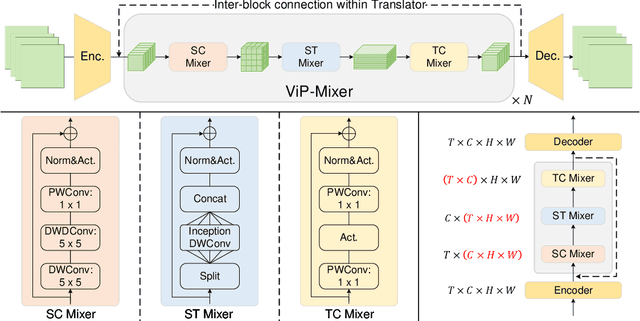
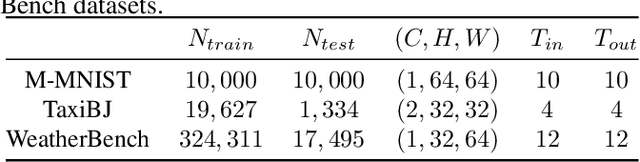
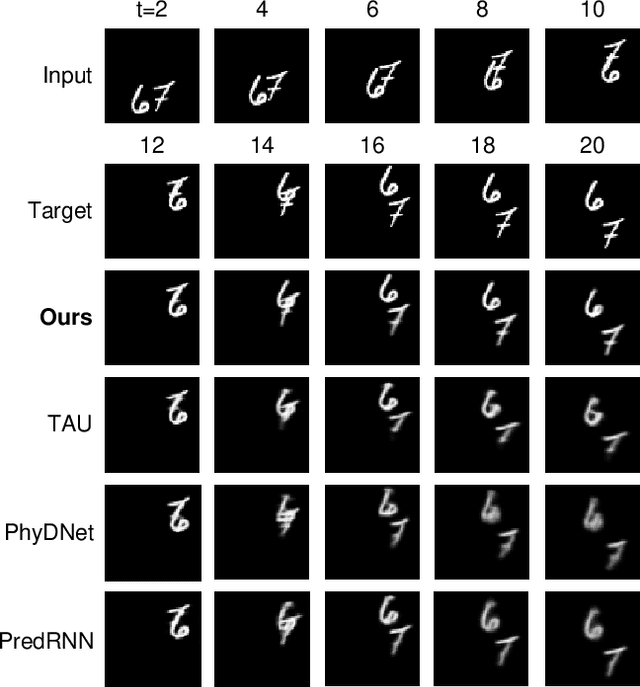
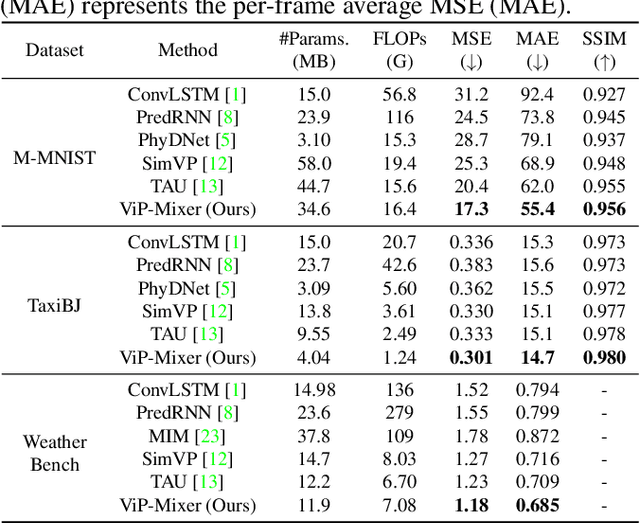
Video prediction aims to predict future frames from a video's previous content. Existing methods mainly process video data where the time dimension mingles with the space and channel dimensions from three distinct angles: as a sequence of individual frames, as a 3D volume in spatiotemporal coordinates, or as a stacked image where frames are treated as separate channels. Most of them generally focus on one of these perspectives and may fail to fully exploit the relationships across different dimensions. To address this issue, this paper introduces a convolutional mixer for video prediction, termed ViP-Mixer, to model the spatiotemporal evolution in the latent space of an autoencoder. The ViP-Mixers are stacked sequentially and interleave feature mixing at three levels: frames, channels, and locations. Extensive experiments demonstrate that our proposed method achieves new state-of-the-art prediction performance on three benchmark video datasets covering both synthetic and real-world scenarios.
Energizing Federated Learning via Filter-Aware Attention
Nov 18, 2023Federated learning (FL) is a promising distributed paradigm, eliminating the need for data sharing but facing challenges from data heterogeneity. Personalized parameter generation through a hypernetwork proves effective, yet existing methods fail to personalize local model structures. This leads to redundant parameters struggling to adapt to diverse data distributions. To address these limitations, we propose FedOFA, utilizing personalized orthogonal filter attention for parameter recalibration. The core is the Two-stream Filter-aware Attention (TFA) module, meticulously designed to extract personalized filter-aware attention maps, incorporating Intra-Filter Attention (IntraFa) and Inter-Filter Attention (InterFA) streams. These streams enhance representation capability and explore optimal implicit structures for local models. Orthogonal regularization minimizes redundancy by averting inter-correlation between filters. Furthermore, we introduce an Attention-Guided Pruning Strategy (AGPS) for communication efficiency. AGPS selectively retains crucial neurons while masking redundant ones, reducing communication costs without performance sacrifice. Importantly, FedOFA operates on the server side, incurring no additional computational cost on the client, making it advantageous in communication-constrained scenarios. Extensive experiments validate superior performance over state-of-the-art approaches, with code availability upon paper acceptance.
LICO: Explainable Models with Language-Image Consistency
Oct 15, 2023Interpreting the decisions of deep learning models has been actively studied since the explosion of deep neural networks. One of the most convincing interpretation approaches is salience-based visual interpretation, such as Grad-CAM, where the generation of attention maps depends merely on categorical labels. Although existing interpretation methods can provide explainable decision clues, they often yield partial correspondence between image and saliency maps due to the limited discriminative information from one-hot labels. This paper develops a Language-Image COnsistency model for explainable image classification, termed LICO, by correlating learnable linguistic prompts with corresponding visual features in a coarse-to-fine manner. Specifically, we first establish a coarse global manifold structure alignment by minimizing the distance between the distributions of image and language features. We then achieve fine-grained saliency maps by applying optimal transport (OT) theory to assign local feature maps with class-specific prompts. Extensive experimental results on eight benchmark datasets demonstrate that the proposed LICO achieves a significant improvement in generating more explainable attention maps in conjunction with existing interpretation methods such as Grad-CAM. Remarkably, LICO improves the classification performance of existing models without introducing any computational overhead during inference. Source code is made available at https://github.com/ymLeiFDU/LICO.