 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChangxin Gao
REPAIR: Rank Correlation and Noisy Pair Half-replacing with Memory for Noisy Correspondence
Mar 13, 2024
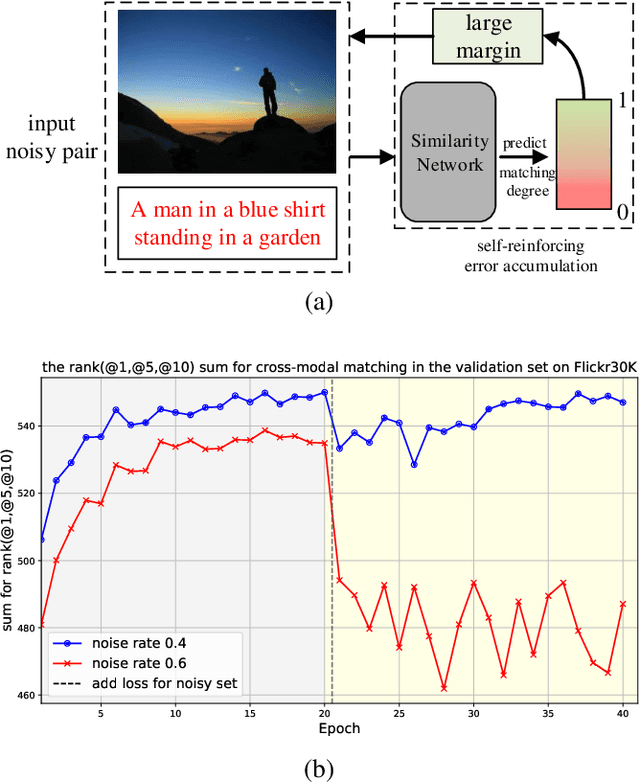
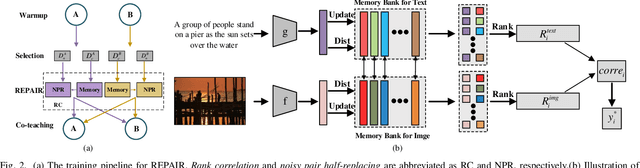
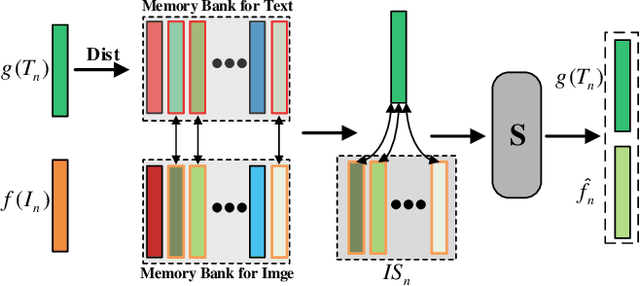
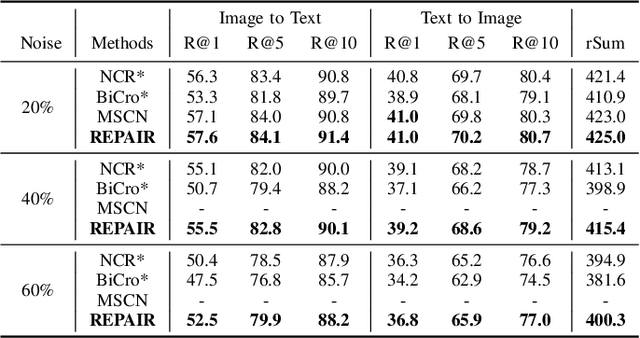
The presence of noise in acquired data invariably leads to performance degradation in cross-modal matching. Unfortunately, obtaining precise annotations in the multimodal field is expensive, which has prompted some methods to tackle the mismatched data pair issue in cross-modal matching contexts, termed as noisy correspondence. However, most of these existing noisy correspondence methods exhibit the following limitations: a) the problem of self-reinforcing error accumulation, and b) improper handling of noisy data pair. To tackle the two problems, we propose a generalized framework termed as Rank corrElation and noisy Pair hAlf-replacing wIth memoRy (REPAIR), which benefits from maintaining a memory bank for features of matched pairs. Specifically, we calculate the distances between the features in the memory bank and those of the target pair for each respective modality, and use the rank correlation of these two sets of distances to estimate the soft correspondence label of the target pair. Estimating soft correspondence based on memory bank features rather than using a similarity network can avoid the accumulation of errors due to incorrect network identifications. For pairs that are completely mismatched, REPAIR searches the memory bank for the most matching feature to replace one feature of one modality, instead of using the original pair directly or merely discarding the mismatched pair. We conduct experiments on three cross-modal datasets, i.e., Flickr30K, MSCOCO, and CC152K, proving the effectiveness and robustness of our REPAIR on synthetic and real-world noise.
GlanceVAD: Exploring Glance Supervision for Label-efficient Video Anomaly Detection
Mar 12, 2024
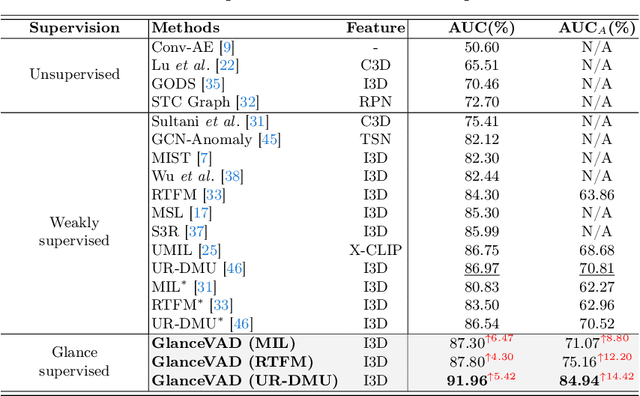
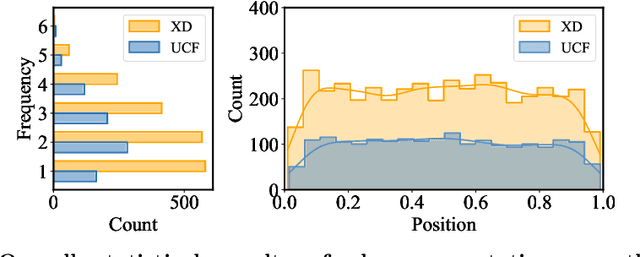
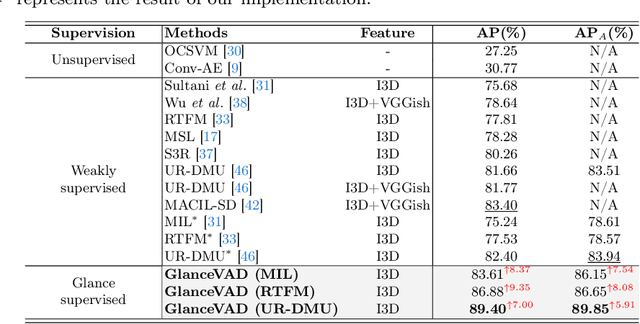
In recent years, video anomaly detection has been extensively investigated in both unsupervised and weakly supervised settings to alleviate costly temporal labeling. Despite significant progress, these methods still suffer from unsatisfactory results such as numerous false alarms, primarily due to the absence of precise temporal anomaly annotation. In this paper, we present a novel labeling paradigm, termed "glance annotation", to achieve a better balance between anomaly detection accuracy and annotation cost. Specifically, glance annotation is a random frame within each abnormal event, which can be easily accessed and is cost-effective. To assess its effectiveness, we manually annotate the glance annotations for two standard video anomaly detection datasets: UCF-Crime and XD-Violence. Additionally, we propose a customized GlanceVAD method, that leverages gaussian kernels as the basic unit to compose the temporal anomaly distribution, enabling the learning of diverse and robust anomaly representations from the glance annotations. Through comprehensive analysis and experiments, we verify that the proposed labeling paradigm can achieve an excellent trade-off between annotation cost and model performance. Extensive experimental results also demonstrate the effectiveness of our GlanceVAD approach, which significantly outperforms existing advanced unsupervised and weakly supervised methods. Code and annotations will be publicly available at https://github.com/pipixin321/GlanceVAD.
Spatial Cascaded Clustering and Weighted Memory for Unsupervised Person Re-identification
Mar 01, 2024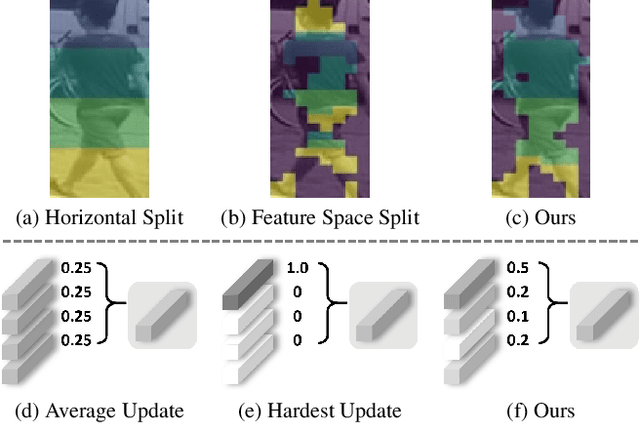
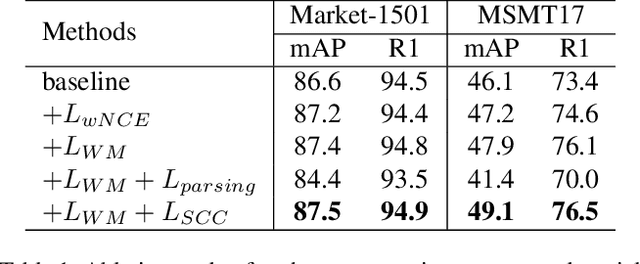
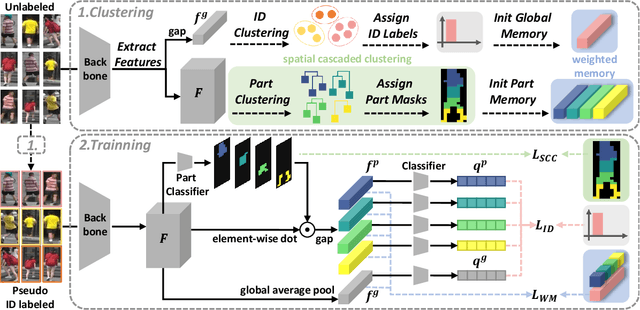
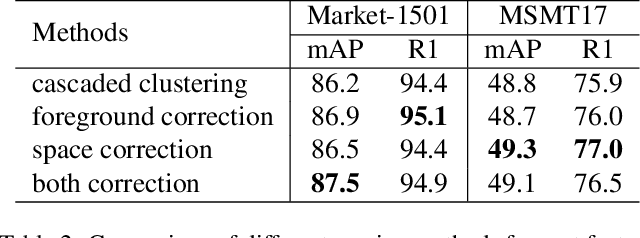
Recent unsupervised person re-identification (re-ID) methods achieve high performance by leveraging fine-grained local context. These methods are referred to as part-based methods. However, most part-based methods obtain local contexts through horizontal division, which suffer from misalignment due to various human poses. Additionally, the misalignment of semantic information in part features restricts the use of metric learning, thus affecting the effectiveness of part-based methods. The two issues mentioned above result in the under-utilization of part features in part-based methods. We introduce the Spatial Cascaded Clustering and Weighted Memory (SCWM) method to address these challenges. SCWM aims to parse and align more accurate local contexts for different human body parts while allowing the memory module to balance hard example mining and noise suppression. Specifically, we first analyze the foreground omissions and spatial confusions issues in the previous method. Then, we propose foreground and space corrections to enhance the completeness and reasonableness of the human parsing results. Next, we introduce a weighted memory and utilize two weighting strategies. These strategies address hard sample mining for global features and enhance noise resistance for part features, which enables better utilization of both global and part features. Extensive experiments on Market-1501 and MSMT17 validate the proposed method's effectiveness over many state-of-the-art methods.
Few-Shot Learning for Annotation-Efficient Nucleus Instance Segmentation
Feb 28, 2024Nucleus instance segmentation from histopathology images suffers from the extremely laborious and expert-dependent annotation of nucleus instances. As a promising solution to this task, annotation-efficient deep learning paradigms have recently attracted much research interest, such as weakly-/semi-supervised learning, generative adversarial learning, etc. In this paper, we propose to formulate annotation-efficient nucleus instance segmentation from the perspective of few-shot learning (FSL). Our work was motivated by that, with the prosperity of computational pathology, an increasing number of fully-annotated datasets are publicly accessible, and we hope to leverage these external datasets to assist nucleus instance segmentation on the target dataset which only has very limited annotation. To achieve this goal, we adopt the meta-learning based FSL paradigm, which however has to be tailored in two substantial aspects before adapting to our task. First, since the novel classes may be inconsistent with those of the external dataset, we extend the basic definition of few-shot instance segmentation (FSIS) to generalized few-shot instance segmentation (GFSIS). Second, to cope with the intrinsic challenges of nucleus segmentation, including touching between adjacent cells, cellular heterogeneity, etc., we further introduce a structural guidance mechanism into the GFSIS network, finally leading to a unified Structurally-Guided Generalized Few-Shot Instance Segmentation (SGFSIS) framework. Extensive experiments on a couple of publicly accessible datasets demonstrate that, SGFSIS can outperform other annotation-efficient learning baselines, including semi-supervised learning, simple transfer learning, etc., with comparable performance to fully supervised learning with less than 5% annotations.
SCTNet: Single-Branch CNN with Transformer Semantic Information for Real-Time Segmentation
Jan 15, 2024Recent real-time semantic segmentation methods usually adopt an additional semantic branch to pursue rich long-range context. However, the additional branch incurs undesirable computational overhead and slows inference speed. To eliminate this dilemma, we propose SCTNet, a single branch CNN with transformer semantic information for real-time segmentation. SCTNet enjoys the rich semantic representations of an inference-free semantic branch while retaining the high efficiency of lightweight single branch CNN. SCTNet utilizes a transformer as the training-only semantic branch considering its superb ability to extract long-range context. With the help of the proposed transformer-like CNN block CFBlock and the semantic information alignment module, SCTNet could capture the rich semantic information from the transformer branch in training. During the inference, only the single branch CNN needs to be deployed. We conduct extensive experiments on Cityscapes, ADE20K, and COCO-Stuff-10K, and the results show that our method achieves the new state-of-the-art performance. The code and model is available at https://github.com/xzz777/SCTNet
A Recipe for Scaling up Text-to-Video Generation with Text-free Videos
Dec 25, 2023Diffusion-based text-to-video generation has witnessed impressive progress in the past year yet still falls behind text-to-image generation. One of the key reasons is the limited scale of publicly available data (e.g., 10M video-text pairs in WebVid10M vs. 5B image-text pairs in LAION), considering the high cost of video captioning. Instead, it could be far easier to collect unlabeled clips from video platforms like YouTube. Motivated by this, we come up with a novel text-to-video generation framework, termed TF-T2V, which can directly learn with text-free videos. The rationale behind is to separate the process of text decoding from that of temporal modeling. To this end, we employ a content branch and a motion branch, which are jointly optimized with weights shared. Following such a pipeline, we study the effect of doubling the scale of training set (i.e., video-only WebVid10M) with some randomly collected text-free videos and are encouraged to observe the performance improvement (FID from 9.67 to 8.19 and FVD from 484 to 441), demonstrating the scalability of our approach. We also find that our model could enjoy sustainable performance gain (FID from 8.19 to 7.64 and FVD from 441 to 366) after reintroducing some text labels for training. Finally, we validate the effectiveness and generalizability of our ideology on both native text-to-video generation and compositional video synthesis paradigms. Code and models will be publicly available at https://tf-t2v.github.io/.
VideoLCM: Video Latent Consistency Model
Dec 14, 2023
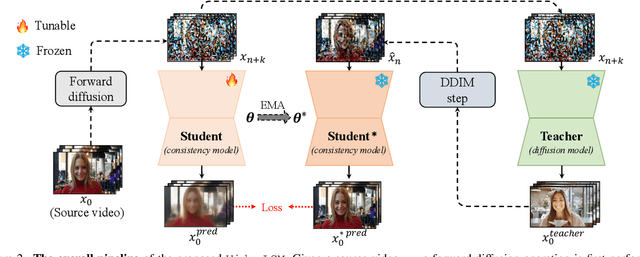

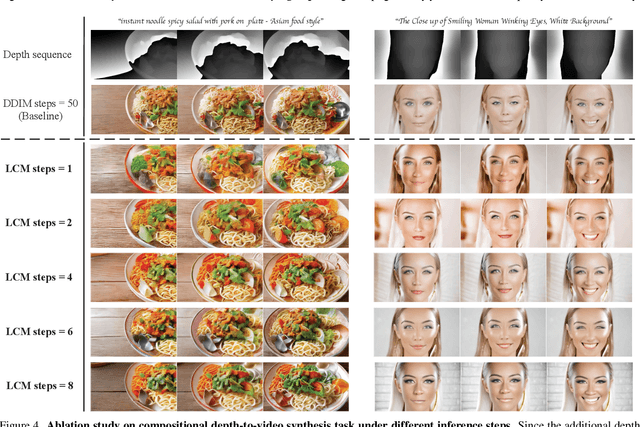
Consistency models have demonstrated powerful capability in efficient image generation and allowed synthesis within a few sampling steps, alleviating the high computational cost in diffusion models. However, the consistency model in the more challenging and resource-consuming video generation is still less explored. In this report, we present the VideoLCM framework to fill this gap, which leverages the concept of consistency models from image generation to efficiently synthesize videos with minimal steps while maintaining high quality. VideoLCM builds upon existing latent video diffusion models and incorporates consistency distillation techniques for training the latent consistency model. Experimental results reveal the effectiveness of our VideoLCM in terms of computational efficiency, fidelity and temporal consistency. Notably, VideoLCM achieves high-fidelity and smooth video synthesis with only four sampling steps, showcasing the potential for real-time synthesis. We hope that VideoLCM can serve as a simple yet effective baseline for subsequent research. The source code and models will be publicly available.
UFineBench: Towards Text-based Person Retrieval with Ultra-fine Granularity
Dec 11, 2023Existing text-based person retrieval datasets often have relatively coarse-grained text annotations. This hinders the model to comprehend the fine-grained semantics of query texts in real scenarios. To address this problem, we contribute a new benchmark named \textbf{UFineBench} for text-based person retrieval with ultra-fine granularity. Firstly, we construct a new \textbf{dataset} named UFine6926. We collect a large number of person images and manually annotate each image with two detailed textual descriptions, averaging 80.8 words each. The average word count is three to four times that of the previous datasets. In addition of standard in-domain evaluation, we also propose a special \textbf{evaluation paradigm} more representative of real scenarios. It contains a new evaluation set with cross domains, cross textual granularity and cross textual styles, named UFine3C, and a new evaluation metric for accurately measuring retrieval ability, named mean Similarity Distribution (mSD). Moreover, we propose CFAM, a more efficient \textbf{algorithm} especially designed for text-based person retrieval with ultra fine-grained texts. It achieves fine granularity mining by adopting a shared cross-modal granularity decoder and hard negative match mechanism. With standard in-domain evaluation, CFAM establishes competitive performance across various datasets, especially on our ultra fine-grained UFine6926. Furthermore, by evaluating on UFine3C, we demonstrate that training on our UFine6926 significantly improves generalization to real scenarios compared with other coarse-grained datasets. The dataset and code will be made publicly available at \url{https://github.com/Zplusdragon/UFineBench}.
Hierarchical Spatio-temporal Decoupling for Text-to-Video Generation
Dec 07, 2023
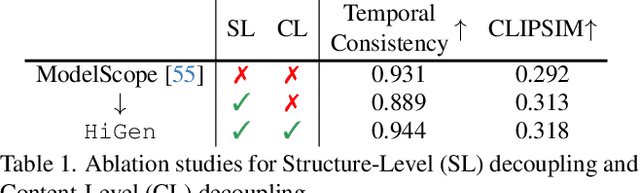
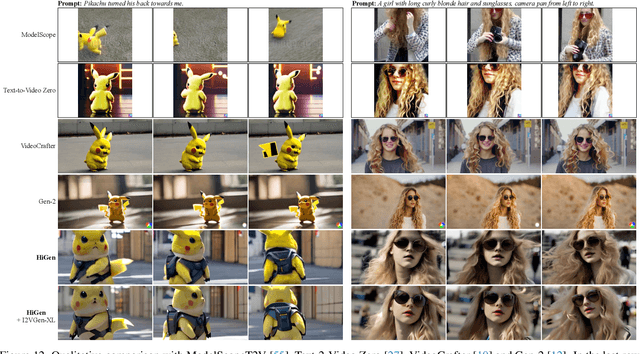

Despite diffusion models having shown powerful abilities to generate photorealistic images, generating videos that are realistic and diverse still remains in its infancy. One of the key reasons is that current methods intertwine spatial content and temporal dynamics together, leading to a notably increased complexity of text-to-video generation (T2V). In this work, we propose HiGen, a diffusion model-based method that improves performance by decoupling the spatial and temporal factors of videos from two perspectives, i.e., structure level and content level. At the structure level, we decompose the T2V task into two steps, including spatial reasoning and temporal reasoning, using a unified denoiser. Specifically, we generate spatially coherent priors using text during spatial reasoning and then generate temporally coherent motions from these priors during temporal reasoning. At the content level, we extract two subtle cues from the content of the input video that can express motion and appearance changes, respectively. These two cues then guide the model's training for generating videos, enabling flexible content variations and enhancing temporal stability. Through the decoupled paradigm, HiGen can effectively reduce the complexity of this task and generate realistic videos with semantics accuracy and motion stability. Extensive experiments demonstrate the superior performance of HiGen over the state-of-the-art T2V methods.
Lookup Table meets Local Laplacian Filter: Pyramid Reconstruction Network for Tone Mapping
Oct 26, 2023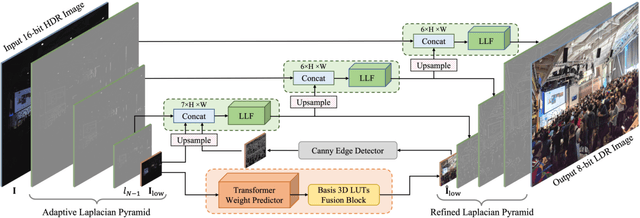
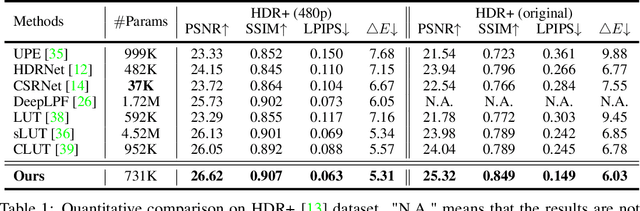
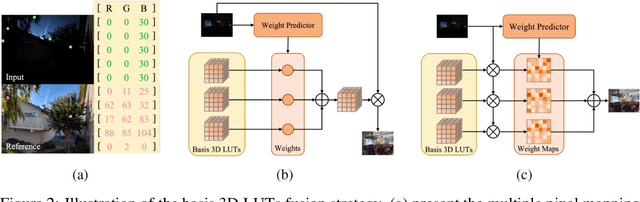
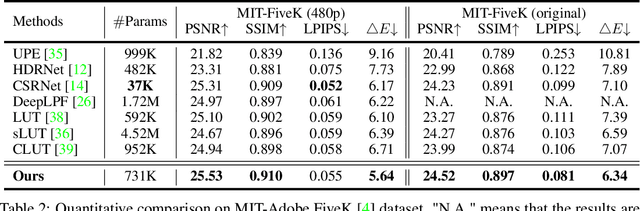
Tone mapping aims to convert high dynamic range (HDR) images to low dynamic range (LDR) representations, a critical task in the camera imaging pipeline. In recent years, 3-Dimensional LookUp Table (3D LUT) based methods have gained attention due to their ability to strike a favorable balance between enhancement performance and computational efficiency. However, these methods often fail to deliver satisfactory results in local areas since the look-up table is a global operator for tone mapping, which works based on pixel values and fails to incorporate crucial local information. To this end, this paper aims to address this issue by exploring a novel strategy that integrates global and local operators by utilizing closed-form Laplacian pyramid decomposition and reconstruction. Specifically, we employ image-adaptive 3D LUTs to manipulate the tone in the low-frequency image by leveraging the specific characteristics of the frequency information. Furthermore, we utilize local Laplacian filters to refine the edge details in the high-frequency components in an adaptive manner. Local Laplacian filters are widely used to preserve edge details in photographs, but their conventional usage involves manual tuning and fixed implementation within camera imaging pipelines or photo editing tools. We propose to learn parameter value maps progressively for local Laplacian filters from annotated data using a lightweight network. Our model achieves simultaneous global tone manipulation and local edge detail preservation in an end-to-end manner. Extensive experimental results on two benchmark datasets demonstrate that the proposed method performs favorably against state-of-the-art methods.