 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJoachim Denzler
When Medical Imaging Met Self-Attention: A Love Story That Didn't Quite Work Out
Apr 18, 2024
A substantial body of research has focused on developing systems that assist medical professionals during labor-intensive early screening processes, many based on convolutional deep-learning architectures. Recently, multiple studies explored the application of so-called self-attention mechanisms in the vision domain. These studies often report empirical improvements over fully convolutional approaches on various datasets and tasks. To evaluate this trend for medical imaging, we extend two widely adopted convolutional architectures with different self-attention variants on two different medical datasets. With this, we aim to specifically evaluate the possible advantages of additional self-attention. We compare our models with similarly sized convolutional and attention-based baselines and evaluate performance gains statistically. Additionally, we investigate how including such layers changes the features learned by these models during the training. Following a hyperparameter search, and contrary to our expectations, we observe no significant improvement in balanced accuracy over fully convolutional models. We also find that important features, such as dermoscopic structures in skin lesion images, are still not learned by employing self-attention. Finally, analyzing local explanations, we confirm biased feature usage. We conclude that merely incorporating attention is insufficient to surpass the performance of existing fully convolutional methods.
* 10 pages, 2 figures, 5 tables, presented at VISAPP 2024
Reducing Bias in Pre-trained Models by Tuning while Penalizing Change
Apr 18, 2024Deep models trained on large amounts of data often incorporate implicit biases present during training time. If later such a bias is discovered during inference or deployment, it is often necessary to acquire new data and retrain the model. This behavior is especially problematic in critical areas such as autonomous driving or medical decision-making. In these scenarios, new data is often expensive and hard to come by. In this work, we present a method based on change penalization that takes a pre-trained model and adapts the weights to mitigate a previously detected bias. We achieve this by tuning a zero-initialized copy of a frozen pre-trained network. Our method needs very few, in extreme cases only a single, examples that contradict the bias to increase performance. Additionally, we propose an early stopping criterion to modify baselines and reduce overfitting. We evaluate our approach on a well-known bias in skin lesion classification and three other datasets from the domain shift literature. We find that our approach works especially well with very few images. Simple fine-tuning combined with our early stopping also leads to performance benefits for a larger number of tuning samples.
* 12 pages, 12 figures, presented at VISAPP 2024
The Power of Properties: Uncovering the Influential Factors in Emotion Classification
Apr 11, 2024Facial expression-based human emotion recognition is a critical research area in psychology and medicine. State-of-the-art classification performance is only reached by end-to-end trained neural networks. Nevertheless, such black-box models lack transparency in their decision-making processes, prompting efforts to ascertain the rules that underlie classifiers' decisions. Analyzing single inputs alone fails to expose systematic learned biases. These biases can be characterized as facial properties summarizing abstract information like age or medical conditions. Therefore, understanding a model's prediction behavior requires an analysis rooted in causality along such selected properties. We demonstrate that up to 91.25% of classifier output behavior changes are statistically significant concerning basic properties. Among those are age, gender, and facial symmetry. Furthermore, the medical usage of surface electromyography significantly influences emotion prediction. We introduce a workflow to evaluate explicit properties and their impact. These insights might help medical professionals select and apply classifiers regarding their specialized data and properties.
Embracing the black box: Heading towards foundation models for causal discovery from time series data
Feb 14, 2024Causal discovery from time series data encompasses many existing solutions, including those based on deep learning techniques. However, these methods typically do not endorse one of the most prevalent paradigms in deep learning: End-to-end learning. To address this gap, we explore what we call Causal Pretraining. A methodology that aims to learn a direct mapping from multivariate time series to the underlying causal graphs in a supervised manner. Our empirical findings suggest that causal discovery in a supervised manner is possible, assuming that the training and test time series samples share most of their dynamics. More importantly, we found evidence that the performance of Causal Pretraining can increase with data and model size, even if the additional data do not share the same dynamics. Further, we provide examples where causal discovery for real-world data with causally pretrained neural networks is possible within limits. We argue that this hints at the possibility of a foundation model for causal discovery.
JeFaPaTo -- A joint toolbox for blinking analysis and facial features extraction
Feb 13, 2024Analyzing facial features and expressions is a complex task in computer vision. The human face is intricate, with significant shape, texture, and appearance variations. In medical contexts, facial structures that differ from the norm, such as those affected by paralysis, are particularly important to study and require precise analysis. One area of interest is the subtle movements involved in blinking, a process that is not yet fully understood and needs high-resolution, time-specific analysis for detailed understanding. However, a significant challenge is that many advanced computer vision techniques demand programming skills, making them less accessible to medical professionals who may not have these skills. The Jena Facial Palsy Toolbox (JeFaPaTo) has been developed to bridge this gap. It utilizes cutting-edge computer vision algorithms and offers a user-friendly interface for those without programming expertise. This toolbox is designed to make advanced facial analysis more accessible to medical experts, simplifying integration into their workflow. The state of the eye closure is of high interest to medical experts, e.g., in the context of facial palsy or Parkinson's disease. Due to facial nerve damage, the eye-closing process might be impaired and could lead to many undesirable side effects. Hence, more than a simple distinction between open and closed eyes is required for a detailed analysis. Factors such as duration, synchronicity, velocity, complete closure, the time between blinks, and frequency over time are highly relevant. Such detailed analysis could help medical experts better understand the blinking process, its deviations, and possible treatments for better eye care.
Privacy-Preserving Face Recognition in Hybrid Frequency-Color Domain
Jan 24, 2024Face recognition technology has been deployed in various real-life applications. The most sophisticated deep learning-based face recognition systems rely on training millions of face images through complex deep neural networks to achieve high accuracy. It is quite common for clients to upload face images to the service provider in order to access the model inference. However, the face image is a type of sensitive biometric attribute tied to the identity information of each user. Directly exposing the raw face image to the service provider poses a threat to the user's privacy. Current privacy-preserving approaches to face recognition focus on either concealing visual information on model input or protecting model output face embedding. The noticeable drop in recognition accuracy is a pitfall for most methods. This paper proposes a hybrid frequency-color fusion approach to reduce the input dimensionality of face recognition in the frequency domain. Moreover, sparse color information is also introduced to alleviate significant accuracy degradation after adding differential privacy noise. Besides, an identity-specific embedding mapping scheme is applied to protect original face embedding by enlarging the distance among identities. Lastly, secure multiparty computation is implemented for safely computing the embedding distance during model inference. The proposed method performs well on multiple widely used verification datasets. Moreover, it has around 2.6% to 4.2% higher accuracy than the state-of-the-art in the 1:N verification scenario.
Deep Learning-based Group Causal Inference in Multivariate Time-series
Jan 16, 2024Causal inference in a nonlinear system of multivariate timeseries is instrumental in disentangling the intricate web of relationships among variables, enabling us to make more accurate predictions and gain deeper insights into real-world complex systems. Causality methods typically identify the causal structure of a multivariate system by considering the cause-effect relationship of each pair of variables while ignoring the collective effect of a group of variables or interactions involving more than two-time series variables. In this work, we test model invariance by group-level interventions on the trained deep networks to infer causal direction in groups of variables, such as climate and ecosystem, brain networks, etc. Extensive testing with synthetic and real-world time series data shows a significant improvement of our method over other applied group causality methods and provides us insights into real-world time series. The code for our method can be found at:https://github.com/wasimahmadpk/gCause.
Let's Get the FACS Straight -- Reconstructing Obstructed Facial Features
Nov 10, 2023The human face is one of the most crucial parts in interhuman communication. Even when parts of the face are hidden or obstructed the underlying facial movements can be understood. Machine learning approaches often fail in that regard due to the complexity of the facial structures. To alleviate this problem a common approach is to fine-tune a model for such a specific application. However, this is computational intensive and might have to be repeated for each desired analysis task. In this paper, we propose to reconstruct obstructed facial parts to avoid the task of repeated fine-tuning. As a result, existing facial analysis methods can be used without further changes with respect to the data. In our approach, the restoration of facial features is interpreted as a style transfer task between different recording setups. By using the CycleGAN architecture the requirement of matched pairs, which is often hard to fullfill, can be eliminated. To proof the viability of our approach, we compare our reconstructions with real unobstructed recordings. We created a novel data set in which 36 test subjects were recorded both with and without 62 surface electromyography sensors attached to their faces. In our evaluation, we feature typical facial analysis tasks, like the computation of Facial Action Units and the detection of emotions. To further assess the quality of the restoration, we also compare perceptional distances. We can show, that scores similar to the videos without obstructing sensors can be achieved.
Automated Visual Monitoring of Nocturnal Insects with Light-based Camera Traps
Jul 28, 2023



Automatic camera-assisted monitoring of insects for abundance estimations is crucial to understand and counteract ongoing insect decline. In this paper, we present two datasets of nocturnal insects, especially moths as a subset of Lepidoptera, photographed in Central Europe. One of the datasets, the EU-Moths dataset, was captured manually by citizen scientists and contains species annotations for 200 different species and bounding box annotations for those. We used this dataset to develop and evaluate a two-stage pipeline for insect detection and moth species classification in previous work. We further introduce a prototype for an automated visual monitoring system. This prototype produced the second dataset consisting of more than 27,000 images captured on 95 nights. For evaluation and bootstrapping purposes, we annotated a subset of the images with bounding boxes enframing nocturnal insects. Finally, we present first detection and classification baselines for these datasets and encourage other scientists to use this publicly available data.
Deep Learning Pipeline for Automated Visual Moth Monitoring: Insect Localization and Species Classification
Jul 28, 2023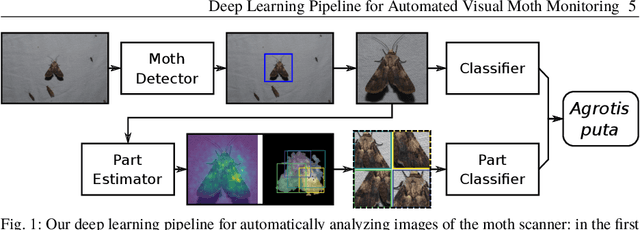
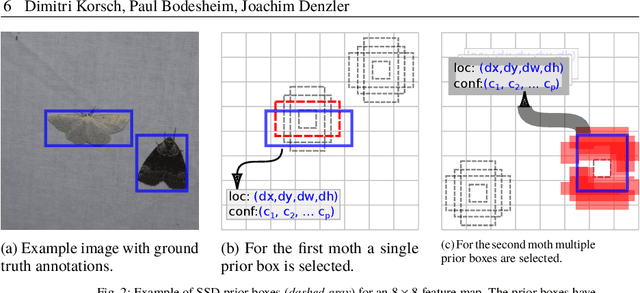
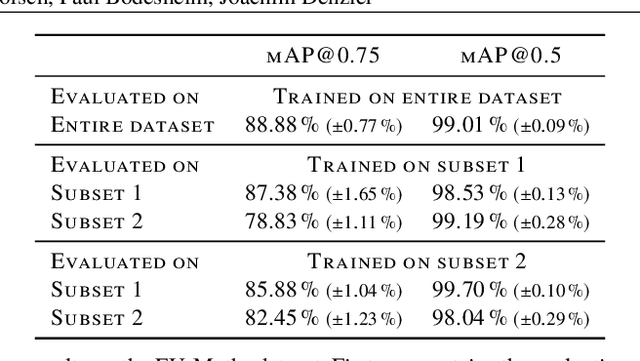

Biodiversity monitoring is crucial for tracking and counteracting adverse trends in population fluctuations. However, automatic recognition systems are rarely applied so far, and experts evaluate the generated data masses manually. Especially the support of deep learning methods for visual monitoring is not yet established in biodiversity research, compared to other areas like advertising or entertainment. In this paper, we present a deep learning pipeline for analyzing images captured by a moth scanner, an automated visual monitoring system of moth species developed within the AMMOD project. We first localize individuals with a moth detector and afterward determine the species of detected insects with a classifier. Our detector achieves up to 99.01% mean average precision and our classifier distinguishes 200 moth species with an accuracy of 93.13% on image cutouts depicting single insects. Combining both in our pipeline improves the accuracy for species identification in images of the moth scanner from 79.62% to 88.05%.