 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJoakim Bruslund Haurum
BarcodeBERT: Transformers for Biodiversity Analysis
Nov 04, 2023
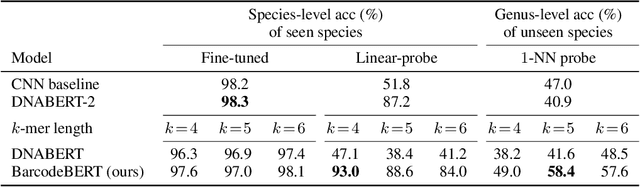
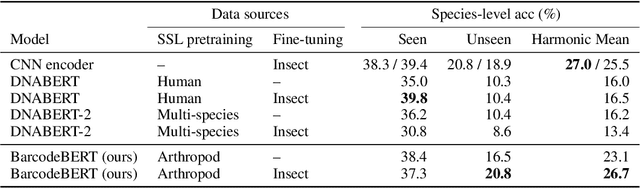
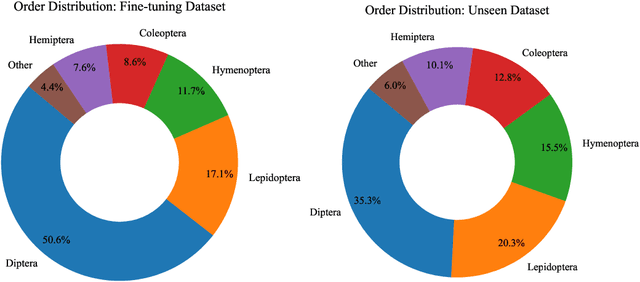
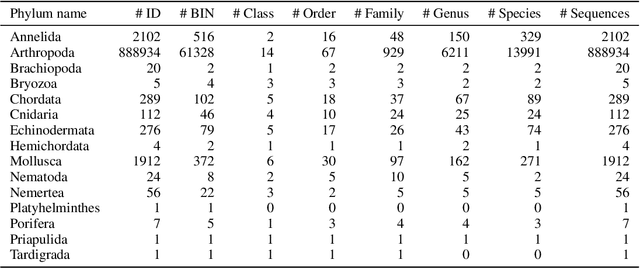
Understanding biodiversity is a global challenge, in which DNA barcodes - short snippets of DNA that cluster by species - play a pivotal role. In particular, invertebrates, a highly diverse and under-explored group, pose unique taxonomic complexities. We explore machine learning approaches, comparing supervised CNNs, fine-tuned foundation models, and a DNA barcode-specific masking strategy across datasets of varying complexity. While simpler datasets and tasks favor supervised CNNs or fine-tuned transformers, challenging species-level identification demands a paradigm shift towards self-supervised pretraining. We propose BarcodeBERT, the first self-supervised method for general biodiversity analysis, leveraging a 1.5 M invertebrate DNA barcode reference library. This work highlights how dataset specifics and coverage impact model selection, and underscores the role of self-supervised pretraining in achieving high-accuracy DNA barcode-based identification at the species and genus level. Indeed, without the fine-tuning step, BarcodeBERT pretrained on a large DNA barcode dataset outperforms DNABERT and DNABERT-2 on multiple downstream classification tasks. The code repository is available at https://github.com/Kari-Genomics-Lab/BarcodeBERT
Which Tokens to Use? Investigating Token Reduction in Vision Transformers
Aug 09, 2023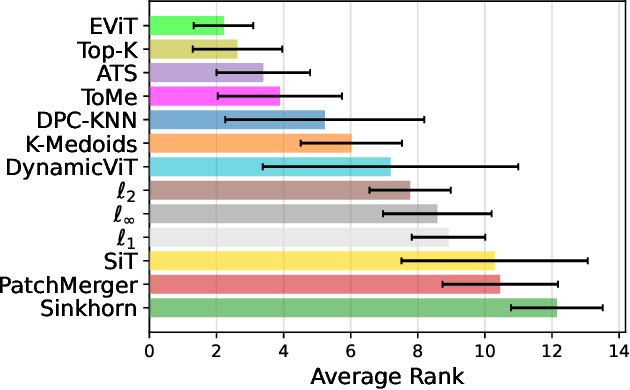
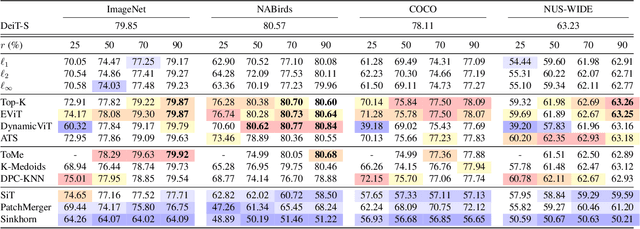


Since the introduction of the Vision Transformer (ViT), researchers have sought to make ViTs more efficient by removing redundant information in the processed tokens. While different methods have been explored to achieve this goal, we still lack understanding of the resulting reduction patterns and how those patterns differ across token reduction methods and datasets. To close this gap, we set out to understand the reduction patterns of 10 different token reduction methods using four image classification datasets. By systematically comparing these methods on the different classification tasks, we find that the Top-K pruning method is a surprisingly strong baseline. Through in-depth analysis of the different methods, we determine that: the reduction patterns are generally not consistent when varying the capacity of the backbone model, the reduction patterns of pruning-based methods significantly differ from fixed radial patterns, and the reduction patterns of pruning-based methods are correlated across classification datasets. Finally we report that the similarity of reduction patterns is a moderate-to-strong proxy for model performance. Project page at https://vap.aau.dk/tokens.
A Step Towards Worldwide Biodiversity Assessment: The BIOSCAN-1M Insect Dataset
Jul 19, 2023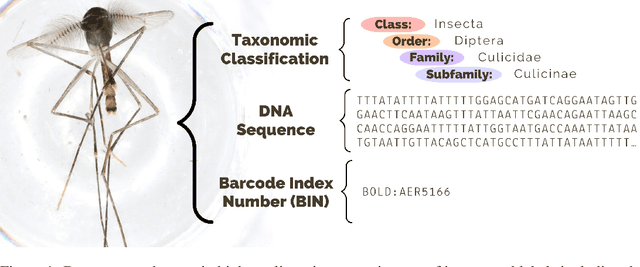

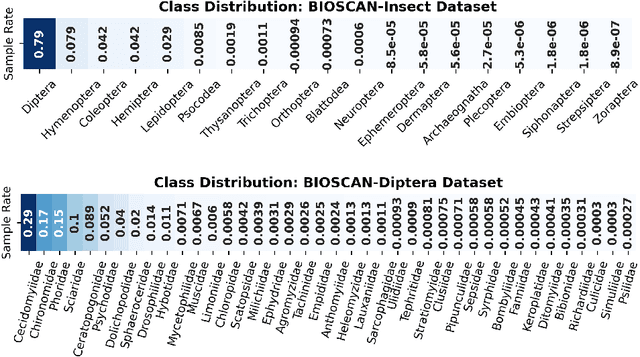

In an effort to catalog insect biodiversity, we propose a new large dataset of hand-labelled insect images, the BIOSCAN-Insect Dataset. Each record is taxonomically classified by an expert, and also has associated genetic information including raw nucleotide barcode sequences and assigned barcode index numbers, which are genetically-based proxies for species classification. This paper presents a curated million-image dataset, primarily to train computer-vision models capable of providing image-based taxonomic assessment, however, the dataset also presents compelling characteristics, the study of which would be of interest to the broader machine learning community. Driven by the biological nature inherent to the dataset, a characteristic long-tailed class-imbalance distribution is exhibited. Furthermore, taxonomic labelling is a hierarchical classification scheme, presenting a highly fine-grained classification problem at lower levels. Beyond spurring interest in biodiversity research within the machine learning community, progress on creating an image-based taxonomic classifier will also further the ultimate goal of all BIOSCAN research: to lay the foundation for a comprehensive survey of global biodiversity. This paper introduces the dataset and explores the classification task through the implementation and analysis of a baseline classifier.
MOTCOM: The Multi-Object Tracking Dataset Complexity Metric
Jul 20, 2022



There exists no comprehensive metric for describing the complexity of Multi-Object Tracking (MOT) sequences. This lack of metrics decreases explainability, complicates comparison of datasets, and reduces the conversation on tracker performance to a matter of leader board position. As a remedy, we present the novel MOT dataset complexity metric (MOTCOM), which is a combination of three sub-metrics inspired by key problems in MOT: occlusion, erratic motion, and visual similarity. The insights of MOTCOM can open nuanced discussions on tracker performance and may lead to a wider acknowledgement of novel contributions developed for either less known datasets or those aimed at solving sub-problems. We evaluate MOTCOM on the comprehensive MOT17, MOT20, and MOTSynth datasets and show that MOTCOM is far better at describing the complexity of MOT sequences compared to the conventional density and number of tracks. Project page at https://vap.aau.dk/motcom
Multi-Task Classification of Sewer Pipe Defects and Properties using a Cross-Task Graph Neural Network Decoder
Nov 15, 2021
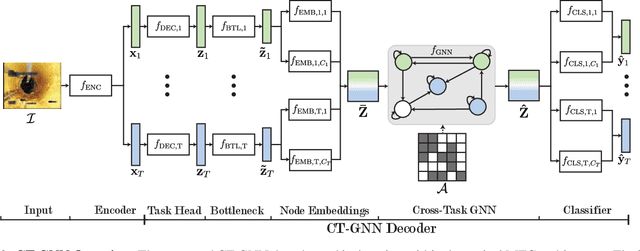


The sewerage infrastructure is one of the most important and expensive infrastructures in modern society. In order to efficiently manage the sewerage infrastructure, automated sewer inspection has to be utilized. However, while sewer defect classification has been investigated for decades, little attention has been given to classifying sewer pipe properties such as water level, pipe material, and pipe shape, which are needed to evaluate the level of sewer pipe deterioration. In this work we classify sewer pipe defects and properties concurrently and present a novel decoder-focused multi-task classification architecture Cross-Task Graph Neural Network (CT-GNN), which refines the disjointed per-task predictions using cross-task information. The CT-GNN architecture extends the traditional disjointed task-heads decoder, by utilizing a cross-task graph and unique class node embeddings. The cross-task graph can either be determined a priori based on the conditional probability between the task classes or determined dynamically using self-attention. CT-GNN can be added to any backbone and trained end-to-end at a small increase in the parameter count. We achieve state-of-the-art performance on all four classification tasks in the Sewer-ML dataset, improving defect classification and water level classification by 5.3 and 8.0 percentage points, respectively. We also outperform the single task methods as well as other multi-task classification approaches while introducing 50 times fewer parameters than previous model-focused approaches. The code and models are available at the project page http://vap.aau.dk/ctgnn
Sewer-ML: A Multi-Label Sewer Defect Classification Dataset and Benchmark
Mar 19, 2021



Perhaps surprisingly sewerage infrastructure is one of the most costly infrastructures in modern society. Sewer pipes are manually inspected to determine whether the pipes are defective. However, this process is limited by the number of qualified inspectors and the time it takes to inspect a pipe. Automatization of this process is therefore of high interest. So far, the success of computer vision approaches for sewer defect classification has been limited when compared to the success in other fields mainly due to the lack of public datasets. To this end, in this work we present a large novel and publicly available multi-label classification dataset for image-based sewer defect classification called Sewer-ML. The Sewer-ML dataset consists of 1.3 million images annotated by professional sewer inspectors from three different utility companies across nine years. Together with the dataset, we also present a benchmark algorithm and a novel metric for assessing performance. The benchmark algorithm is a result of evaluating 12 state-of-the-art algorithms, six from the sewer defect classification domain and six from the multi-label classification domain, and combining the best performing algorithms. The novel metric is a class-importance weighted F2 score, $\text{F}2_{\text{CIW}}$, reflecting the economic impact of each class, used together with the normal pipe F1 score, $\text{F}1_{\text{Normal}}$. The benchmark algorithm achieves an $\text{F}2_{\text{CIW}}$ score of 55.11% and $\text{F}1_{\text{Normal}}$ score of 90.94%, leaving ample room for improvement on the Sewer-ML dataset. The code, models, and dataset are available at the project page https://vap.aau.dk/sewer-ml/
3D-ZeF: A 3D Zebrafish Tracking Benchmark Dataset
Jun 15, 2020



In this work we present a novel publicly available stereo based 3D RGB dataset for multi-object zebrafish tracking, called 3D-ZeF. Zebrafish is an increasingly popular model organism used for studying neurological disorders, drug addiction, and more. Behavioral analysis is often a critical part of such research. However, visual similarity, occlusion, and erratic movement of the zebrafish makes robust 3D tracking a challenging and unsolved problem. The proposed dataset consists of eight sequences with a duration between 15-120 seconds and 1-10 free moving zebrafish. The videos have been annotated with a total of 86,400 points and bounding boxes. Furthermore, we present a complexity score and a novel open-source modular baseline system for 3D tracking of zebrafish. The performance of the system is measured with respect to two detectors: a naive approach and a Faster R-CNN based fish head detector. The system reaches a MOTA of up to 77.6%. Links to the code and dataset is available at the project page https://vap.aau.dk/3d-zef
Is it Raining Outside? Detection of Rainfall using General-Purpose Surveillance Cameras
Aug 12, 2019



In integrated surveillance systems based on visual cameras, the mitigation of adverse weather conditions is an active research topic. Within this field, rain removal algorithms have been developed that artificially remove rain streaks from images or video. In order to deploy such rain removal algorithms in a surveillance setting, one must detect if rain is present in the scene. In this paper, we design a system for the detection of rainfall by the use of surveillance cameras. We reimplement the former state-of-the-art method for rain detection and compare it against a modern CNN-based method by utilizing 3D convolutions. The two methods are evaluated on our new AAU Visual Rain Dataset (VIRADA) that consists of 215 hours of general-purpose surveillance video from two traffic crossings. The results show that the proposed 3D CNN outperforms the previous state-of-the-art method by a large margin on all metrics, for both of the traffic crossings. Finally, it is shown that the choice of region-of-interest has a large influence on performance when trying to generalize the investigated methods. The AAU VIRADA dataset and our implementation of the two rain detection algorithms are publicly available at https://bitbucket.org/aauvap/aau-virada.