 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJoel Niklaus
FLawN-T5: An Empirical Examination of Effective Instruction-Tuning Data Mixtures for Legal Reasoning
Apr 02, 2024
Instruction tuning is an important step in making language models useful for direct user interaction. However, many legal tasks remain out of reach for most open LLMs and there do not yet exist any large scale instruction datasets for the domain. This critically limits research in this application area. In this work, we curate LawInstruct, a large legal instruction dataset, covering 17 jurisdictions, 24 languages and a total of 12M examples. We present evidence that domain-specific pretraining and instruction tuning improve performance on LegalBench, including improving Flan-T5 XL by 8 points or 16\% over the baseline. However, the effect does not generalize across all tasks, training regimes, model sizes, and other factors. LawInstruct is a resource for accelerating the development of models with stronger information processing and decision making capabilities in the legal domain.
Towards Explainability and Fairness in Swiss Judgement Prediction: Benchmarking on a Multilingual Dataset
Feb 26, 2024The assessment of explainability in Legal Judgement Prediction (LJP) systems is of paramount importance in building trustworthy and transparent systems, particularly considering the reliance of these systems on factors that may lack legal relevance or involve sensitive attributes. This study delves into the realm of explainability and fairness in LJP models, utilizing Swiss Judgement Prediction (SJP), the only available multilingual LJP dataset. We curate a comprehensive collection of rationales that `support' and `oppose' judgement from legal experts for 108 cases in German, French, and Italian. By employing an occlusion-based explainability approach, we evaluate the explainability performance of state-of-the-art monolingual and multilingual BERT-based LJP models, as well as models developed with techniques such as data augmentation and cross-lingual transfer, which demonstrated prediction performance improvement. Notably, our findings reveal that improved prediction performance does not necessarily correspond to enhanced explainability performance, underscoring the significance of evaluating models from an explainability perspective. Additionally, we introduce a novel evaluation framework, Lower Court Insertion (LCI), which allows us to quantify the influence of lower court information on model predictions, exposing current models' biases.
LegalLens: Leveraging LLMs for Legal Violation Identification in Unstructured Text
Feb 06, 2024In this study, we focus on two main tasks, the first for detecting legal violations within unstructured textual data, and the second for associating these violations with potentially affected individuals. We constructed two datasets using Large Language Models (LLMs) which were subsequently validated by domain expert annotators. Both tasks were designed specifically for the context of class-action cases. The experimental design incorporated fine-tuning models from the BERT family and open-source LLMs, and conducting few-shot experiments using closed-source LLMs. Our results, with an F1-score of 62.69\% (violation identification) and 81.02\% (associating victims), show that our datasets and setups can be used for both tasks. Finally, we publicly release the datasets and the code used for the experiments in order to advance further research in the area of legal natural language processing (NLP).
Automatic Anonymization of Swiss Federal Supreme Court Rulings
Oct 07, 2023Releasing court decisions to the public relies on proper anonymization to protect all involved parties, where necessary. The Swiss Federal Supreme Court relies on an existing system that combines different traditional computational methods with human experts. In this work, we enhance the existing anonymization software using a large dataset annotated with entities to be anonymized. We compared BERT-based models with models pre-trained on in-domain data. Our results show that using in-domain data to pre-train the models further improves the F1-score by more than 5\% compared to existing models. Our work demonstrates that combining existing anonymization methods, such as regular expressions, with machine learning can further reduce manual labor and enhance automatic suggestions.
Resolving Legalese: A Multilingual Exploration of Negation Scope Resolution in Legal Documents
Sep 15, 2023Resolving the scope of a negation within a sentence is a challenging NLP task. The complexity of legal texts and the lack of annotated in-domain negation corpora pose challenges for state-of-the-art (SotA) models when performing negation scope resolution on multilingual legal data. Our experiments demonstrate that models pre-trained without legal data underperform in the task of negation scope resolution. Our experiments, using language models exclusively fine-tuned on domains like literary texts and medical data, yield inferior results compared to the outcomes documented in prior cross-domain experiments. We release a new set of annotated court decisions in German, French, and Italian and use it to improve negation scope resolution in both zero-shot and multilingual settings. We achieve token-level F1-scores of up to 86.7% in our zero-shot cross-lingual experiments, where the models are trained on two languages of our legal datasets and evaluated on the third. Our multilingual experiments, where the models were trained on all available negation data and evaluated on our legal datasets, resulted in F1-scores of up to 91.1%.
Anonymity at Risk? Assessing Re-Identification Capabilities of Large Language Models
Aug 22, 2023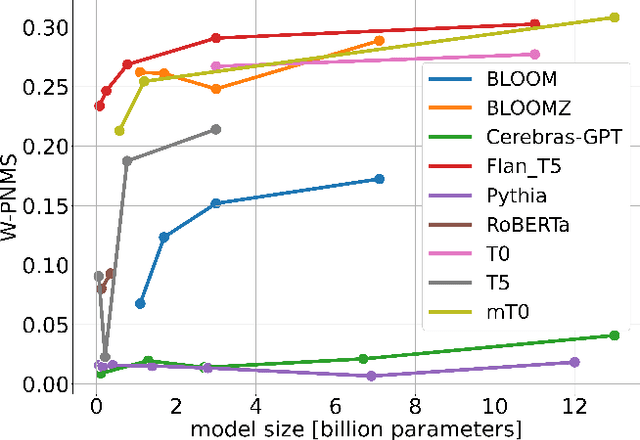
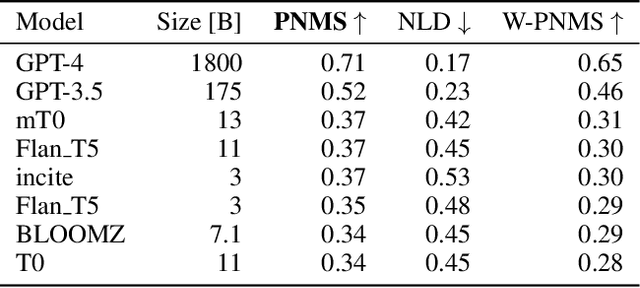
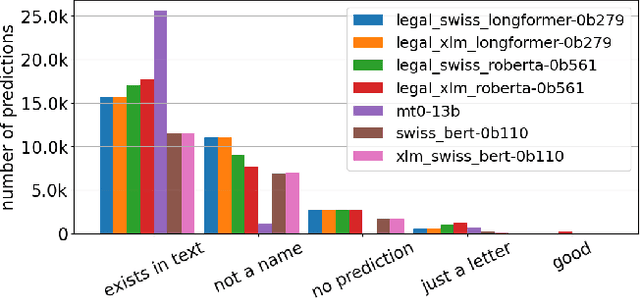
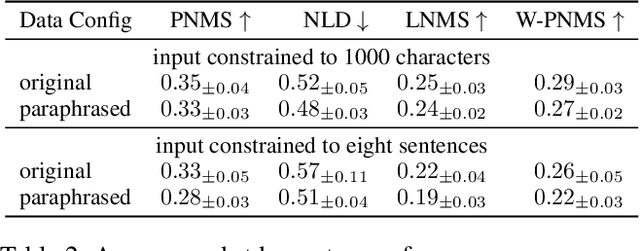
Anonymity of both natural and legal persons in court rulings is a critical aspect of privacy protection in the European Union and Switzerland. With the advent of LLMs, concerns about large-scale re-identification of anonymized persons are growing. In accordance with the Federal Supreme Court of Switzerland, we explore the potential of LLMs to re-identify individuals in court rulings by constructing a proof-of-concept using actual legal data from the Swiss federal supreme court. Following the initial experiment, we constructed an anonymized Wikipedia dataset as a more rigorous testing ground to further investigate the findings. With the introduction and application of the new task of re-identifying people in texts, we also introduce new metrics to measure performance. We systematically analyze the factors that influence successful re-identifications, identifying model size, input length, and instruction tuning among the most critical determinants. Despite high re-identification rates on Wikipedia, even the best LLMs struggled with court decisions. The complexity is attributed to the lack of test datasets, the necessity for substantial training resources, and data sparsity in the information used for re-identification. In conclusion, this study demonstrates that re-identification using LLMs may not be feasible for now, but as the proof-of-concept on Wikipedia showed, it might become possible in the future. We hope that our system can help enhance the confidence in the security of anonymized decisions, thus leading to the courts being more confident to publish decisions.
LegalBench: A Collaboratively Built Benchmark for Measuring Legal Reasoning in Large Language Models
Aug 20, 2023
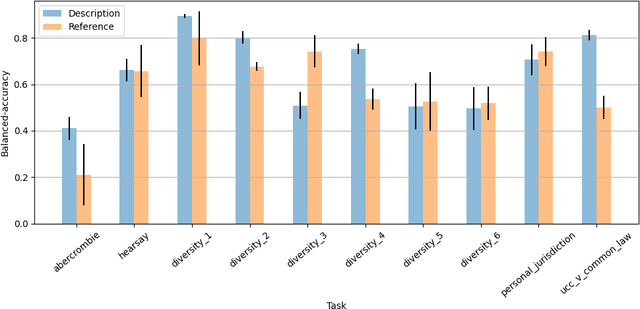
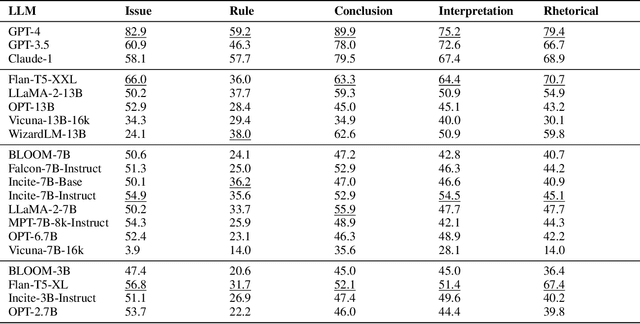
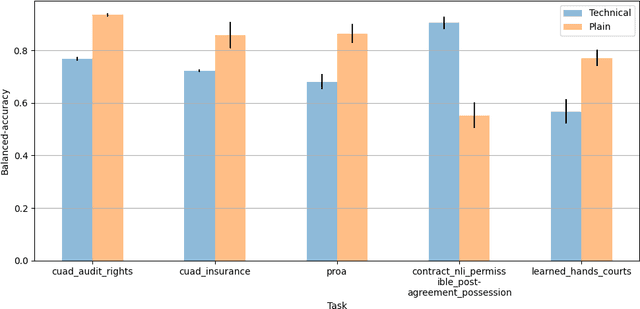
The advent of large language models (LLMs) and their adoption by the legal community has given rise to the question: what types of legal reasoning can LLMs perform? To enable greater study of this question, we present LegalBench: a collaboratively constructed legal reasoning benchmark consisting of 162 tasks covering six different types of legal reasoning. LegalBench was built through an interdisciplinary process, in which we collected tasks designed and hand-crafted by legal professionals. Because these subject matter experts took a leading role in construction, tasks either measure legal reasoning capabilities that are practically useful, or measure reasoning skills that lawyers find interesting. To enable cross-disciplinary conversations about LLMs in the law, we additionally show how popular legal frameworks for describing legal reasoning -- which distinguish between its many forms -- correspond to LegalBench tasks, thus giving lawyers and LLM developers a common vocabulary. This paper describes LegalBench, presents an empirical evaluation of 20 open-source and commercial LLMs, and illustrates the types of research explorations LegalBench enables.
SCALE: Scaling up the Complexity for Advanced Language Model Evaluation
Jun 15, 2023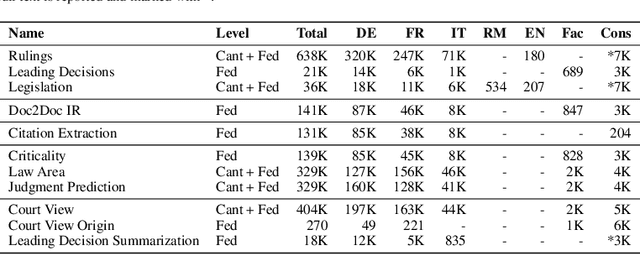
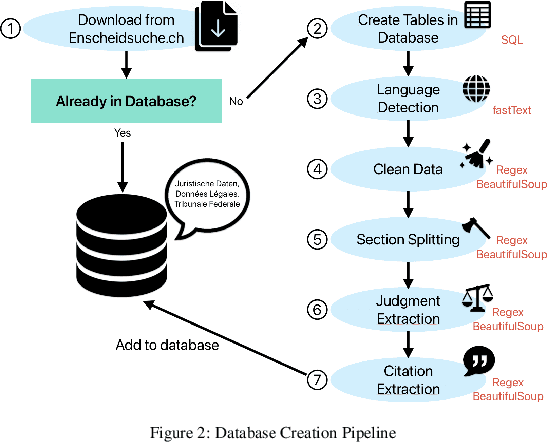
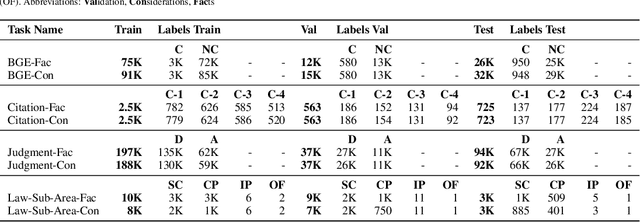
Recent strides in Large Language Models (LLMs) have saturated many NLP benchmarks (even professional domain-specific ones), emphasizing the need for novel, more challenging novel ones to properly assess LLM capabilities. In this paper, we introduce a novel NLP benchmark that poses challenges to current LLMs across four key dimensions: processing long documents (up to 50K tokens), utilizing domain specific knowledge (embodied in legal texts), multilingual understanding (covering five languages), and multitasking (comprising legal document to document Information Retrieval, Court View Generation, Leading Decision Summarization, Citation Extraction, and eight challenging Text Classification tasks). Our benchmark comprises diverse legal NLP datasets from the Swiss legal system, allowing for a comprehensive study of the underlying Non-English, inherently multilingual, federal legal system. Despite recent advances, efficiently processing long documents for intense review/analysis tasks remains an open challenge for language models. Also, comprehensive, domain-specific benchmarks requiring high expertise to develop are rare, as are multilingual benchmarks. This scarcity underscores our contribution's value, considering most public models are trained predominantly on English corpora, while other languages remain understudied, particularly for practical domain-specific NLP tasks. Our benchmark allows for testing and advancing the state-of-the-art LLMs. As part of our study, we evaluate several pre-trained multilingual language models on our benchmark to establish strong baselines as a point of reference. Despite the large size of our datasets (tens to hundreds of thousands of examples), existing publicly available models struggle with most tasks, even after in-domain pretraining. We publish all resources (benchmark suite, pre-trained models, code) under a fully permissive open CC BY-SA license.
MultiLegalPile: A 689GB Multilingual Legal Corpus
Jun 06, 2023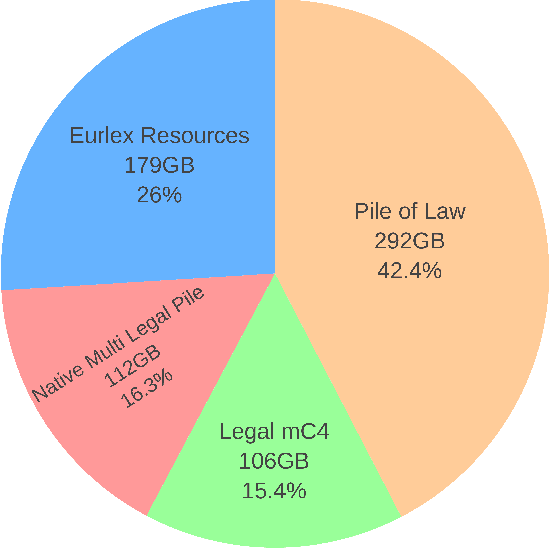
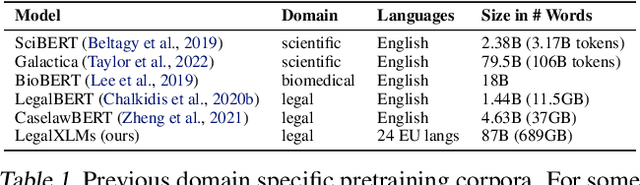
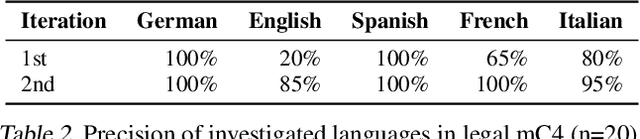
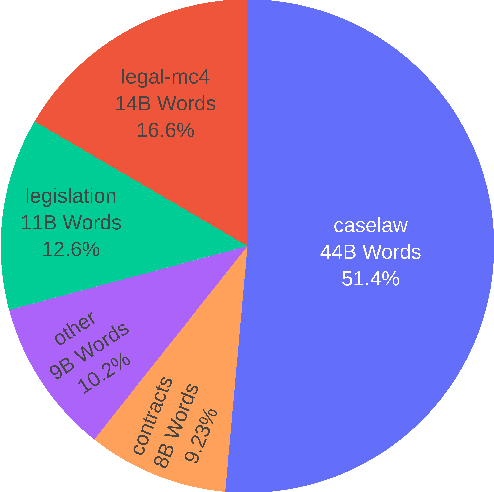
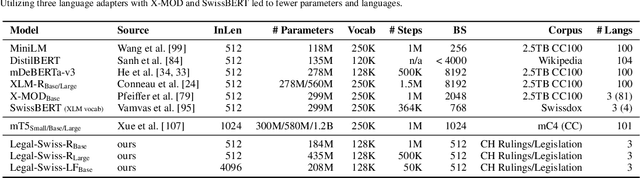
Large, high-quality datasets are crucial for training Large Language Models (LLMs). However, so far, there are few datasets available for specialized critical domains such as law and the available ones are often only for the English language. We curate and release MultiLegalPile, a 689GB corpus in 24 languages from 17 jurisdictions. The MultiLegalPile corpus, which includes diverse legal data sources with varying licenses, allows for pretraining NLP models under fair use, with more permissive licenses for the Eurlex Resources and Legal mC4 subsets. We pretrain two RoBERTa models and one Longformer multilingually, and 24 monolingual models on each of the language-specific subsets and evaluate them on LEXTREME. Additionally, we evaluate the English and multilingual models on LexGLUE. Our multilingual models set a new SotA on LEXTREME and our English models on LexGLUE. We release the dataset, the trained models, and all of the code under the most open possible licenses.
MultiLegalSBD: A Multilingual Legal Sentence Boundary Detection Dataset
May 02, 2023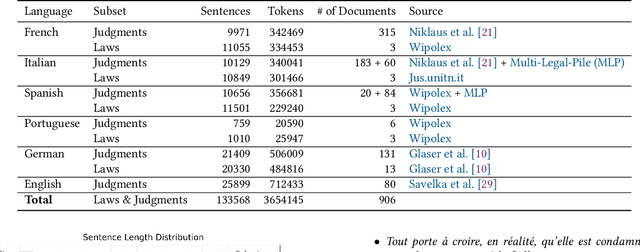
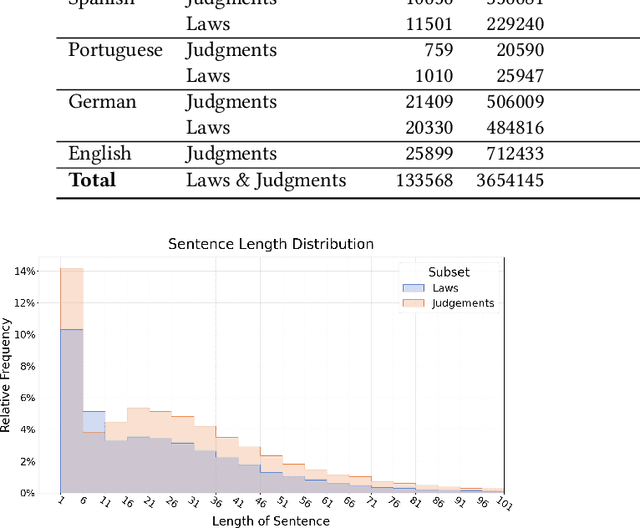
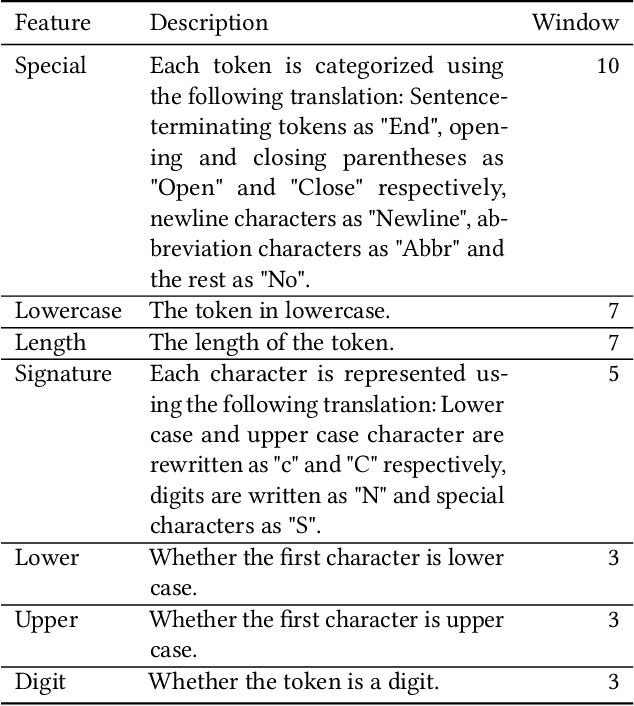
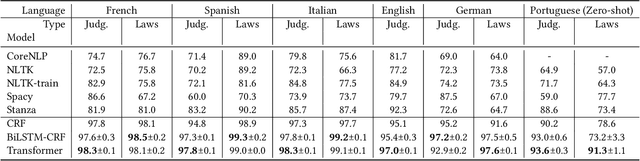
Sentence Boundary Detection (SBD) is one of the foundational building blocks of Natural Language Processing (NLP), with incorrectly split sentences heavily influencing the output quality of downstream tasks. It is a challenging task for algorithms, especially in the legal domain, considering the complex and different sentence structures used. In this work, we curated a diverse multilingual legal dataset consisting of over 130'000 annotated sentences in 6 languages. Our experimental results indicate that the performance of existing SBD models is subpar on multilingual legal data. We trained and tested monolingual and multilingual models based on CRF, BiLSTM-CRF, and transformers, demonstrating state-of-the-art performance. We also show that our multilingual models outperform all baselines in the zero-shot setting on a Portuguese test set. To encourage further research and development by the community, we have made our dataset, models, and code publicly available.