 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShang Gao
GRAMMAR: Grounded and Modular Methodology for Assessment of Domain-Specific Retrieval-Augmented Language Model
May 02, 2024
Retrieval-augmented Generation (RAG) systems have been actively studied and deployed across various industries to query on domain-specific knowledge base. However, evaluating these systems presents unique challenges due to the scarcity of domain-specific queries and corresponding ground truths, as well as a lack of systematic approaches to diagnosing the cause of failure cases -- whether they stem from knowledge deficits or issues related to system robustness. To address these challenges, we introduce GRAMMAR (GRounded And Modular Methodology for Assessment of RAG), an evaluation framework comprising two key elements: 1) a data generation process that leverages relational databases and LLMs to efficiently produce scalable query-answer pairs. This method facilitates the separation of query logic from linguistic variations for enhanced debugging capabilities; and 2) an evaluation framework that differentiates knowledge gaps from robustness and enables the identification of defective modules. Our empirical results underscore the limitations of current reference-free evaluation approaches and the reliability of GRAMMAR to accurately identify model vulnerabilities.
Deep Boosting Learning: A Brand-new Cooperative Approach for Image-Text Matching
Apr 28, 2024Image-text matching remains a challenging task due to heterogeneous semantic diversity across modalities and insufficient distance separability within triplets. Different from previous approaches focusing on enhancing multi-modal representations or exploiting cross-modal correspondence for more accurate retrieval, in this paper we aim to leverage the knowledge transfer between peer branches in a boosting manner to seek a more powerful matching model. Specifically, we propose a brand-new Deep Boosting Learning (DBL) algorithm, where an anchor branch is first trained to provide insights into the data properties, with a target branch gaining more advanced knowledge to develop optimal features and distance metrics. Concretely, an anchor branch initially learns the absolute or relative distance between positive and negative pairs, providing a foundational understanding of the particular network and data distribution. Building upon this knowledge, a target branch is concurrently tasked with more adaptive margin constraints to further enlarge the relative distance between matched and unmatched samples. Extensive experiments validate that our DBL can achieve impressive and consistent improvements based on various recent state-of-the-art models in the image-text matching field, and outperform related popular cooperative strategies, e.g., Conventional Distillation, Mutual Learning, and Contrastive Learning. Beyond the above, we confirm that DBL can be seamlessly integrated into their training scenarios and achieve superior performance under the same computational costs, demonstrating the flexibility and broad applicability of our proposed method. Our code is publicly available at: https://github.com/Paranioar/DBL.
Can't Remember Details in Long Documents? You Need Some R&R
Mar 08, 2024
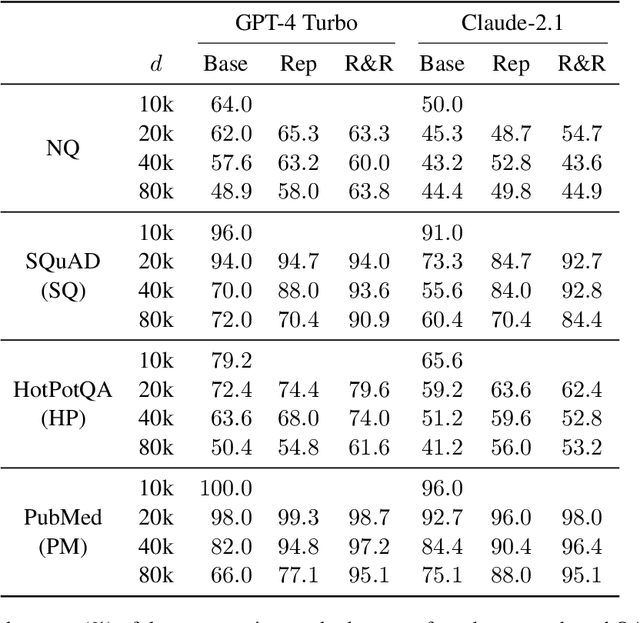
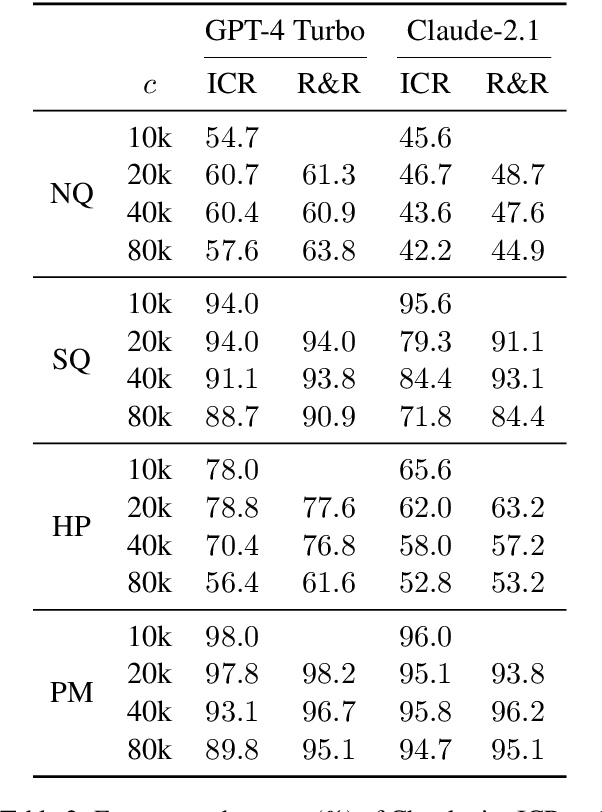
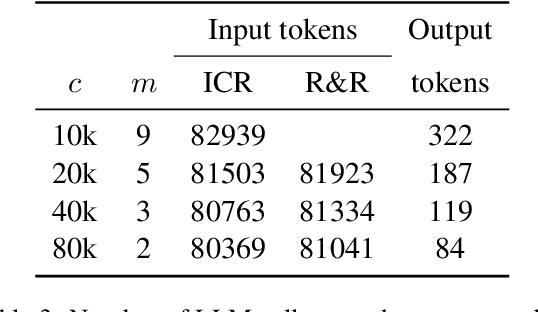
Long-context large language models (LLMs) hold promise for tasks such as question-answering (QA) over long documents, but they tend to miss important information in the middle of context documents (arXiv:2307.03172v3). Here, we introduce $\textit{R&R}$ -- a combination of two novel prompt-based methods called $\textit{reprompting}$ and $\textit{in-context retrieval}$ (ICR) -- to alleviate this effect in document-based QA. In reprompting, we repeat the prompt instructions periodically throughout the context document to remind the LLM of its original task. In ICR, rather than instructing the LLM to answer the question directly, we instruct it to retrieve the top $k$ passage numbers most relevant to the given question, which are then used as an abbreviated context in a second QA prompt. We test R&R with GPT-4 Turbo and Claude-2.1 on documents up to 80k tokens in length and observe a 16-point boost in QA accuracy on average. Our further analysis suggests that R&R improves performance on long document-based QA because it reduces the distance between relevant context and the instructions. Finally, we show that compared to short-context chunkwise methods, R&R enables the use of larger chunks that cost fewer LLM calls and output tokens, while minimizing the drop in accuracy.
Suturing Tasks Automation Based on Skills Learned From Demonstrations: A Simulation Study
Mar 01, 2024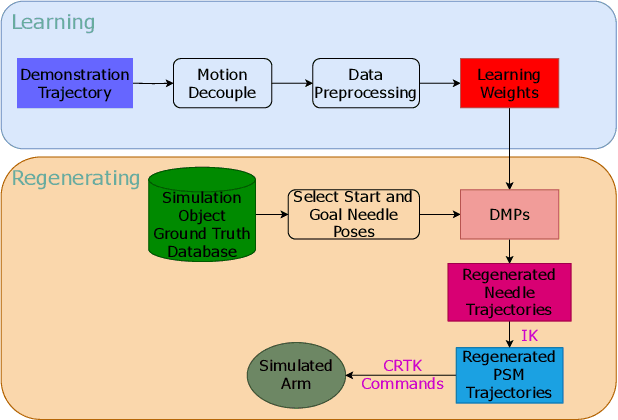
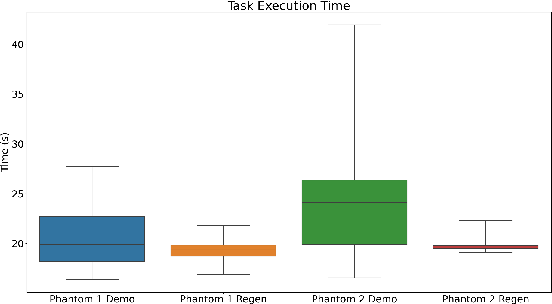
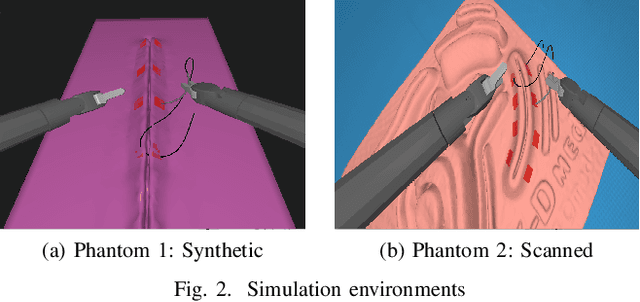

In this work, we develop an open-source surgical simulation environment that includes a realistic model obtained by MRI-scanning a physical phantom, for the purpose of training and evaluating a Learning from Demonstration (LfD) algorithm for autonomous suturing. The LfD algorithm utilizes Dynamic Movement Primitives (DMP) and Locally Weighted Regression (LWR), but focuses on the needle trajectory, rather than the instruments, to obtain better generality with respect to needle grasps. We conduct a user study to collect multiple suturing demonstrations and perform a comprehensive analysis of the ability of the LfD algorithm to generalize from a demonstration at one location in one phantom to different locations in the same phantom and to a different phantom. Our results indicate good generalization, on the order of 91.5%, when learning from more experienced subjects, indicating the need to integrate skill assessment in the future.
Part Representation Learning with Teacher-Student Decoder for Occluded Person Re-identification
Dec 15, 2023



Occluded person re-identification (ReID) is a very challenging task due to the occlusion disturbance and incomplete target information. Leveraging external cues such as human pose or parsing to locate and align part features has been proven to be very effective in occluded person ReID. Meanwhile, recent Transformer structures have a strong ability of long-range modeling. Considering the above facts, we propose a Teacher-Student Decoder (TSD) framework for occluded person ReID, which utilizes the Transformer decoder with the help of human parsing. More specifically, our proposed TSD consists of a Parsing-aware Teacher Decoder (PTD) and a Standard Student Decoder (SSD). PTD employs human parsing cues to restrict Transformer's attention and imparts this information to SSD through feature distillation. Thereby, SSD can learn from PTD to aggregate information of body parts automatically. Moreover, a mask generator is designed to provide discriminative regions for better ReID. In addition, existing occluded person ReID benchmarks utilize occluded samples as queries, which will amplify the role of alleviating occlusion interference and underestimate the impact of the feature absence issue. Contrastively, we propose a new benchmark with non-occluded queries, serving as a complement to the existing benchmark. Extensive experiments demonstrate that our proposed method is superior and the new benchmark is essential. The source codes are available at https://github.com/hh23333/TSD.
Learning to Learn for Few-shot Continual Active Learning
Nov 07, 2023Continual learning strives to ensure stability in solving previously seen tasks while demonstrating plasticity in a novel domain. Recent advances in CL are mostly confined to a supervised learning setting, especially in NLP domain. In this work, we consider a few-shot continual active learning (CAL) setting where labeled data is inadequate, and unlabeled data is abundant but with a limited annotation budget. We propose a simple but efficient method, called Meta-Continual Active Learning. Specifically, we employ meta-learning and experience replay to address the trade-off between stability and plasticity. As a result, it finds an optimal initialization that efficiently utilizes annotated information for fast adaptation while preventing catastrophic forgetting of past tasks. We conduct extensive experiments to validate the effectiveness of the proposed method and analyze the effect of various active learning strategies and memory sample selection methods in a few-shot CAL setup. Our experiment results demonstrate that random sampling is the best default strategy for both active learning and memory sample selection to solve few-shot CAL problems.
Enhanced Knowledge Injection for Radiology Report Generation
Nov 01, 2023Automatic generation of radiology reports holds crucial clinical value, as it can alleviate substantial workload on radiologists and remind less experienced ones of potential anomalies. Despite the remarkable performance of various image captioning methods in the natural image field, generating accurate reports for medical images still faces challenges, i.e., disparities in visual and textual data, and lack of accurate domain knowledge. To address these issues, we propose an enhanced knowledge injection framework, which utilizes two branches to extract different types of knowledge. The Weighted Concept Knowledge (WCK) branch is responsible for introducing clinical medical concepts weighted by TF-IDF scores. The Multimodal Retrieval Knowledge (MRK) branch extracts triplets from similar reports, emphasizing crucial clinical information related to entity positions and existence. By integrating this finer-grained and well-structured knowledge with the current image, we are able to leverage the multi-source knowledge gain to ultimately facilitate more accurate report generation. Extensive experiments have been conducted on two public benchmarks, demonstrating that our method achieves superior performance over other state-of-the-art methods. Ablation studies further validate the effectiveness of two extracted knowledge sources.
LegalBench: A Collaboratively Built Benchmark for Measuring Legal Reasoning in Large Language Models
Aug 20, 2023
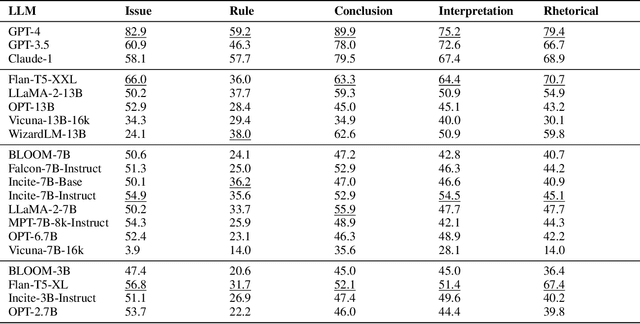
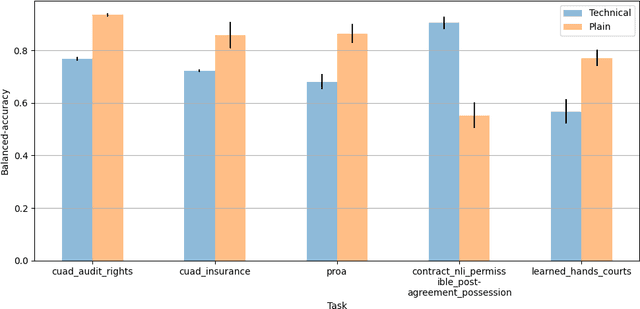
The advent of large language models (LLMs) and their adoption by the legal community has given rise to the question: what types of legal reasoning can LLMs perform? To enable greater study of this question, we present LegalBench: a collaboratively constructed legal reasoning benchmark consisting of 162 tasks covering six different types of legal reasoning. LegalBench was built through an interdisciplinary process, in which we collected tasks designed and hand-crafted by legal professionals. Because these subject matter experts took a leading role in construction, tasks either measure legal reasoning capabilities that are practically useful, or measure reasoning skills that lawyers find interesting. To enable cross-disciplinary conversations about LLMs in the law, we additionally show how popular legal frameworks for describing legal reasoning -- which distinguish between its many forms -- correspond to LegalBench tasks, thus giving lawyers and LLM developers a common vocabulary. This paper describes LegalBench, presents an empirical evaluation of 20 open-source and commercial LLMs, and illustrates the types of research explorations LegalBench enables.
Make Text Unlearnable: Exploiting Effective Patterns to Protect Personal Data
Jul 02, 2023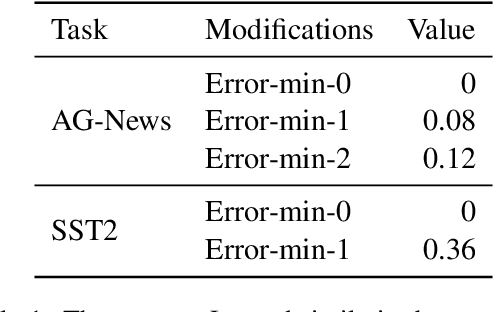
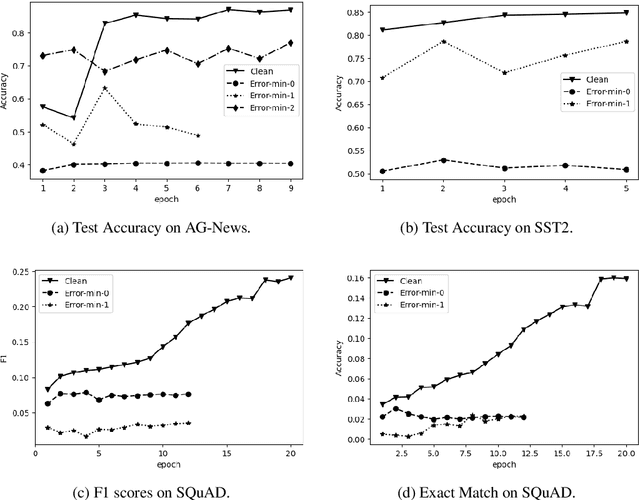
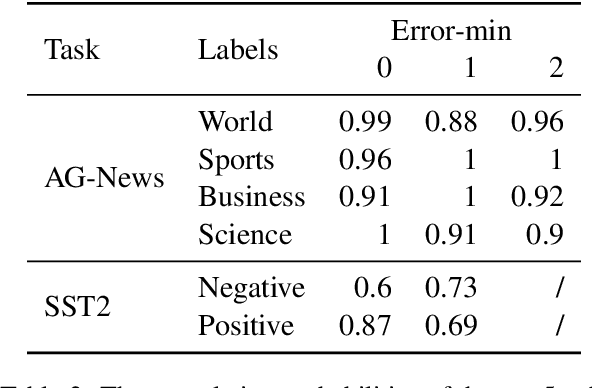
This paper addresses the ethical concerns arising from the use of unauthorized public data in deep learning models and proposes a novel solution. Specifically, building on the work of Huang et al. (2021), we extend their bi-level optimization approach to generate unlearnable text using a gradient-based search technique. However, although effective, this approach faces practical limitations, including the requirement of batches of instances and model architecture knowledge that is not readily accessible to ordinary users with limited access to their own data. Furthermore, even with semantic-preserving constraints, unlearnable noise can alter the text's semantics. To address these challenges, we extract simple patterns from unlearnable text produced by bi-level optimization and demonstrate that the data remains unlearnable for unknown models. Additionally, these patterns are not instance- or dataset-specific, allowing users to readily apply them to text classification and question-answering tasks, even if only a small proportion of users implement them on their public content. We also open-source codes to generate unlearnable text and assess unlearnable noise to benefit the public and future studies.
Can Pretrained Language Models Derive Correct Semantics from Corrupt Subwords under Noise?
Jun 27, 2023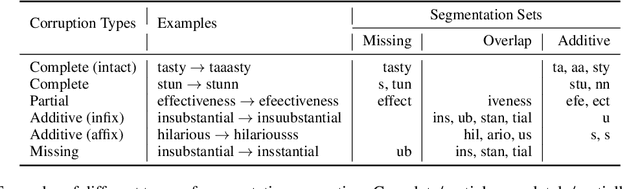
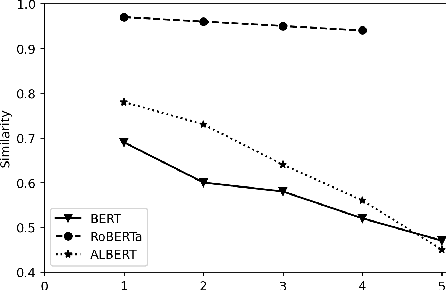

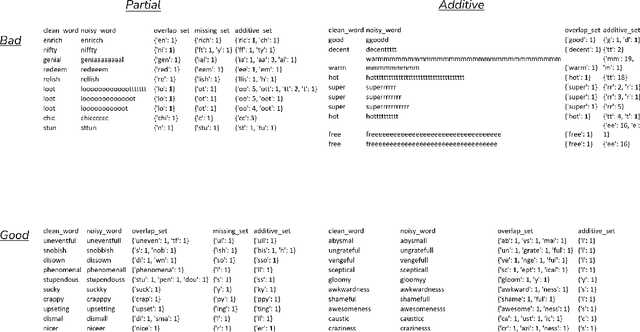
For Pretrained Language Models (PLMs), their susceptibility to noise has recently been linked to subword segmentation. However, it is unclear which aspects of segmentation affect their understanding. This study assesses the robustness of PLMs against various disrupted segmentation caused by noise. An evaluation framework for subword segmentation, named Contrastive Lexical Semantic (CoLeS) probe, is proposed. It provides a systematic categorization of segmentation corruption under noise and evaluation protocols by generating contrastive datasets with canonical-noisy word pairs. Experimental results indicate that PLMs are unable to accurately compute word meanings if the noise introduces completely different subwords, small subword fragments, or a large number of additional subwords, particularly when they are inserted within other subwords.