 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJohn Yang
DevBench: A Comprehensive Benchmark for Software Development
Mar 15, 2024
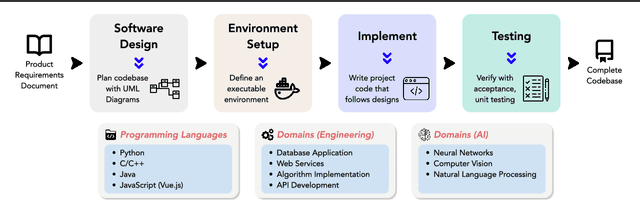
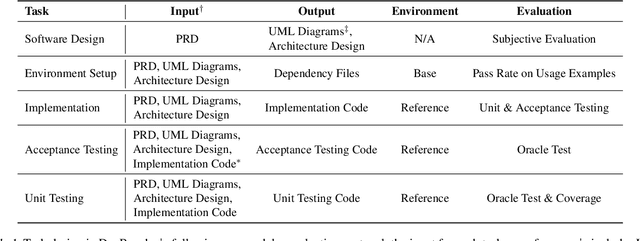
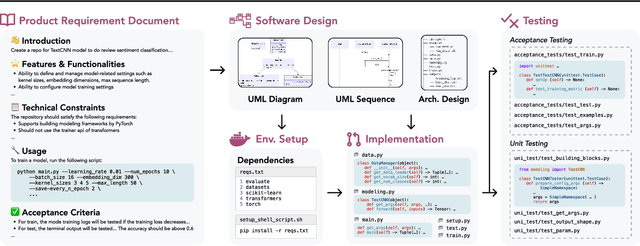
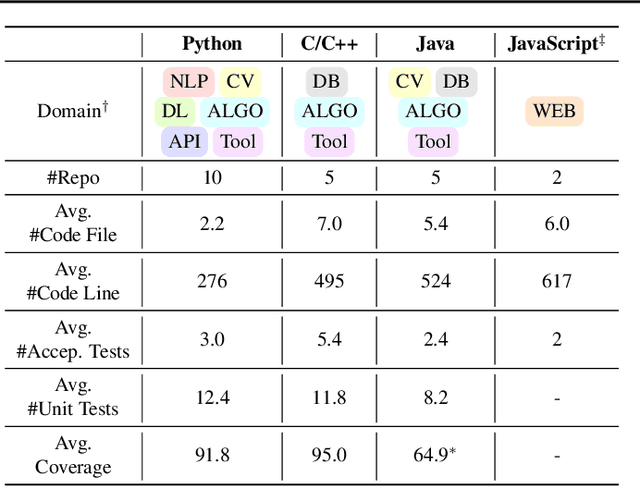
Recent advancements in large language models (LLMs) have significantly enhanced their coding capabilities. However, existing benchmarks predominantly focused on simplified or isolated aspects of programming, such as single-file code generation or repository issue debugging, falling short of measuring the full spectrum of challenges raised by real-world programming activities. To this end, we propose DevBench, a comprehensive benchmark that evaluates LLMs across various stages of the software development lifecycle, including software design, environment setup, implementation, acceptance testing, and unit testing. DevBench features a wide range of programming languages and domains, high-quality data collection, and carefully designed and verified metrics for each task. Empirical studies show that current LLMs, including GPT-4-Turbo, fail to solve the challenges presented within DevBench. Analyses reveal that models struggle with understanding the complex structures in the repository, managing the compilation process, and grasping advanced programming concepts. Our findings offer actionable insights for the future development of LLMs toward real-world programming applications. Our benchmark is available at https://github.com/open-compass/DevBench
SWE-bench: Can Language Models Resolve Real-World GitHub Issues?
Oct 10, 2023Language models have outpaced our ability to evaluate them effectively, but for their future development it is essential to study the frontier of their capabilities. We consider real-world software engineering to be a rich, sustainable, and challenging testbed for evaluating the next generation of language models. We therefore introduce SWE-bench, an evaluation framework including $2,294$ software engineering problems drawn from real GitHub issues and corresponding pull requests across $12$ popular Python repositories. Given a codebase along with a description of an issue to be resolved, a language model is tasked with editing the codebase to address the issue. Resolving issues in SWE-bench frequently requires understanding and coordinating changes across multiple functions, classes, and even files simultaneously, calling for models to interact with execution environments, process extremely long contexts and perform complex reasoning that goes far beyond traditional code generation. Our evaluations show that both state-of-the-art proprietary models and our fine-tuned model SWE-Llama can resolve only the simplest issues. Claude 2 and GPT-4 solve a mere $4.8$% and $1.7$% of instances respectively, even when provided with an oracle retriever. Advances on SWE-bench represent steps towards LMs that are more practical, intelligent, and autonomous.
InterCode: Standardizing and Benchmarking Interactive Coding with Execution Feedback
Jun 27, 2023



Humans write code in a fundamentally interactive manner and rely on constant execution feedback to correct errors, resolve ambiguities, and decompose tasks. While LLMs have recently exhibited promising coding capabilities, current coding benchmarks mostly consider a static instruction-to-code sequence transduction process, which has the potential for error propagation and a disconnect between the generated code and its final execution environment. To address this gap, we introduce InterCode, a lightweight, flexible, and easy-to-use framework of interactive coding as a standard reinforcement learning (RL) environment, with code as actions and execution feedback as observations. Our framework is language and platform agnostic, uses self-contained Docker environments to provide safe and reproducible execution, and is compatible out-of-the-box with traditional seq2seq coding methods, while enabling the development of new methods for interactive code generation. We use InterCode to create two interactive code environments with Bash and SQL as action spaces, leveraging data from the static Spider and NL2Bash datasets. We demonstrate InterCode's viability as a testbed by evaluating multiple state-of-the-art LLMs configured with different prompting strategies such as ReAct and Plan & Solve. Our results showcase the benefits of interactive code generation and demonstrate that InterCode can serve as a challenging benchmark for advancing code understanding and generation capabilities. InterCode is designed to be easily extensible and can even be used to incorporate new tasks such as Capture the Flag, a popular coding puzzle that is inherently multi-step and involves multiple programming languages. Project site with code and data: https://intercode-benchmark.github.io
Swin-Free: Achieving Better Cross-Window Attention and Efficiency with Size-varying Window
Jun 23, 2023



Transformer models have shown great potential in computer vision, following their success in language tasks. Swin Transformer is one of them that outperforms convolution-based architectures in terms of accuracy, while improving efficiency when compared to Vision Transformer (ViT) and its variants, which have quadratic complexity with respect to the input size. Swin Transformer features shifting windows that allows cross-window connection while limiting self-attention computation to non-overlapping local windows. However, shifting windows introduces memory copy operations, which account for a significant portion of its runtime. To mitigate this issue, we propose Swin-Free in which we apply size-varying windows across stages, instead of shifting windows, to achieve cross-connection among local windows. With this simple design change, Swin-Free runs faster than the Swin Transformer at inference with better accuracy. Furthermore, we also propose a few of Swin-Free variants that are faster than their Swin Transformer counterparts.
Referral Augmentation for Zero-Shot Information Retrieval
May 24, 2023



We propose Referral-Augmented Retrieval (RAR), a simple technique that concatenates document indices with referrals, i.e. text from other documents that cite or link to the given document, to provide significant performance gains for zero-shot information retrieval. The key insight behind our method is that referrals provide a more complete, multi-view representation of a document, much like incoming page links in algorithms like PageRank provide a comprehensive idea of a webpage's importance. RAR works with both sparse and dense retrievers, and outperforms generative text expansion techniques such as DocT5Query and Query2Doc a 37% and 21% absolute improvement on ACL paper retrieval Recall@10 -- while also eliminating expensive model training and inference. We also analyze different methods for multi-referral aggregation and show that RAR enables up-to-date information retrieval without re-training.
WebShop: Towards Scalable Real-World Web Interaction with Grounded Language Agents
Jul 17, 2022



Existing benchmarks for grounding language in interactive environments either lack real-world linguistic elements, or prove difficult to scale up due to substantial human involvement in the collection of data or feedback signals. To bridge this gap, we develop WebShop -- a simulated e-commerce website environment with $1.18$ million real-world products and $12,087$ crowd-sourced text instructions. Given a text instruction specifying a product requirement, an agent needs to navigate multiple types of webpages and issue diverse actions to find, customize, and purchase an item. WebShop provides several challenges for language grounding including understanding compositional instructions, query (re-)formulation, comprehending and acting on noisy text in webpages, and performing strategic exploration. We collect over $1,600$ human demonstrations for the task, and train and evaluate a diverse range of agents using reinforcement learning, imitation learning, and pre-trained image and language models. Our best model achieves a task success rate of $29\%$, which outperforms rule-based heuristics ($9.6\%$) but is far lower than human expert performance ($59\%$). We also analyze agent and human trajectories and ablate various model components to provide insights for developing future agents with stronger language understanding and decision making abilities. Finally, we show that agents trained on WebShop exhibit non-trivial sim-to-real transfer when evaluated on amazon.com and ebay.com, indicating the potential value of WebShop in developing practical web-based agents that can operate in the wild.
Depth Estimation with Simplified Transformer
Apr 28, 2022



Transformer and its variants have shown state-of-the-art results in many vision tasks recently, ranging from image classification to dense prediction. Despite of their success, limited work has been reported on improving the model efficiency for deployment in latency-critical applications, such as autonomous driving and robotic navigation. In this paper, we aim at improving upon the existing transformers in vision, and propose a method for self-supervised monocular Depth Estimation with Simplified Transformer (DEST), which is efficient and particularly suitable for deployment on GPU-based platforms. Through strategic design choices, our model leads to significant reduction in model size, complexity, as well as inference latency, while achieving superior accuracy as compared to state-of-the-art. We also show that our design generalize well to other dense prediction task without bells and whistles.
Dynamic Iterative Refinement for Efficient 3D Hand Pose Estimation
Nov 11, 2021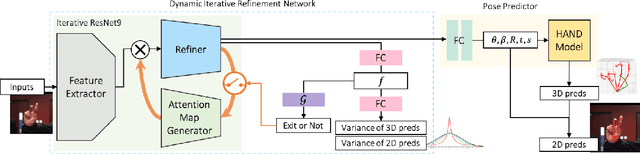



While hand pose estimation is a critical component of most interactive extended reality and gesture recognition systems, contemporary approaches are not optimized for computational and memory efficiency. In this paper, we propose a tiny deep neural network of which partial layers are recursively exploited for refining its previous estimations. During its iterative refinements, we employ learned gating criteria to decide whether to exit from the weight-sharing loop, allowing per-sample adaptation in our model. Our network is trained to be aware of the uncertainty in its current predictions to efficiently gate at each iteration, estimating variances after each loop for its keypoint estimates. Additionally, we investigate the effectiveness of end-to-end and progressive training protocols for our recursive structure on maximizing the model capacity. With the proposed setting, our method consistently outperforms state-of-the-art 2D/3D hand pose estimation approaches in terms of both accuracy and efficiency for widely used benchmarks.
SeqHAND:RGB-Sequence-Based 3D Hand Pose and Shape Estimation
Jul 10, 2020



3D hand pose estimation based on RGB images has been studied for a long time. Most of the studies, however, have performed frame-by-frame estimation based on independent static images. In this paper, we attempt to not only consider the appearance of a hand but incorporate the temporal movement information of a hand in motion into the learning framework for better 3D hand pose estimation performance, which leads to the necessity of a large scale dataset with sequential RGB hand images. We propose a novel method that generates a synthetic dataset that mimics natural human hand movements by re-engineering annotations of an extant static hand pose dataset into pose-flows. With the generated dataset, we train a newly proposed recurrent framework, exploiting visuo-temporal features from sequential images of synthetic hands in motion and emphasizing temporal smoothness of estimations with a temporal consistency constraint. Our novel training strategy of detaching the recurrent layer of the framework during domain finetuning from synthetic to real allows preservation of the visuo-temporal features learned from sequential synthetic hand images. Hand poses that are sequentially estimated consequently produce natural and smooth hand movements which lead to more robust estimations. We show that utilizing temporal information for 3D hand pose estimation significantly enhances general pose estimations by outperforming state-of-the-art methods in experiments on hand pose estimation benchmarks.
Image Translation to Mixed-Domain using Sym-Parameterized Generative Network
Nov 29, 2018



Recent advances in image-to-image translation have led to some ways to generate multiple domain images through a single network. However, there is still a limit in creating an image of a target domain without a dataset on it. We propose a method to expand the concept of `multi-domain' from data to the loss area, and to combine the characteristics of each domain to create an image. First, we introduce a sym-parameter and its learning method that can mix various losses and can synchronize them with input conditions. Then, we propose Sym-parameterized Generative Network (SGN) using it. Through experiments, we confirmed that SGN could mix the characteristics of various data and loss, and it is possible to translate images to any mixed-domain without ground truths, such as 30% Van Gogh and 20% Monet.