 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLin Shi
Exploring and Evaluating Hallucinations in LLM-Powered Code Generation
Apr 01, 2024
The rise of Large Language Models (LLMs) has significantly advanced many applications on software engineering tasks, particularly in code generation. Despite the promising performance, LLMs are prone to generate hallucinations, which means LLMs might produce outputs that deviate from users' intent, exhibit internal inconsistencies, or misalign with the factual knowledge, making the deployment of LLMs potentially risky in a wide range of applications. Existing work mainly focuses on investing the hallucination in the domain of natural language generation (NLG), leaving a gap in understanding the types and extent of hallucinations in the context of code generation. To bridge the gap, we conducted a thematic analysis of the LLM-generated code to summarize and categorize the hallucinations present in it. Our study established a comprehensive taxonomy of hallucinations in LLM-generated code, encompassing 5 primary categories of hallucinations depending on the conflicting objectives and varying degrees of deviation observed in code generation. Furthermore, we systematically analyzed the distribution of hallucinations, exploring variations among different LLMs and their correlation with code correctness. Based on the results, we proposed HalluCode, a benchmark for evaluating the performance of code LLMs in recognizing hallucinations. Hallucination recognition and mitigation experiments with HalluCode and HumanEval show existing LLMs face great challenges in recognizing hallucinations, particularly in identifying their types, and are hardly able to mitigate hallucinations. We believe our findings will shed light on future research about hallucination evaluation, detection, and mitigation, ultimately paving the way for building more effective and reliable code LLMs in the future.
DevBench: A Comprehensive Benchmark for Software Development
Mar 15, 2024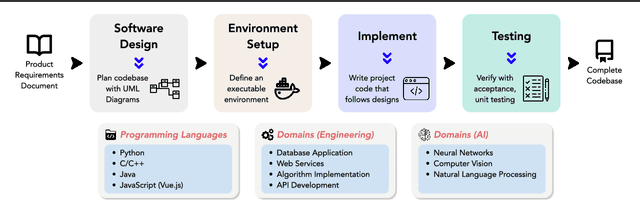
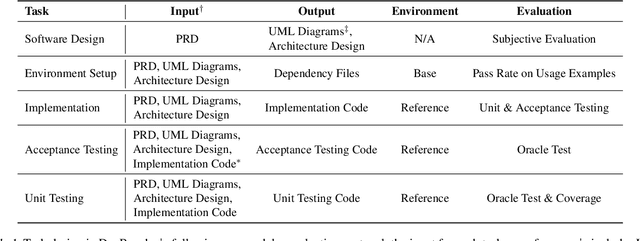
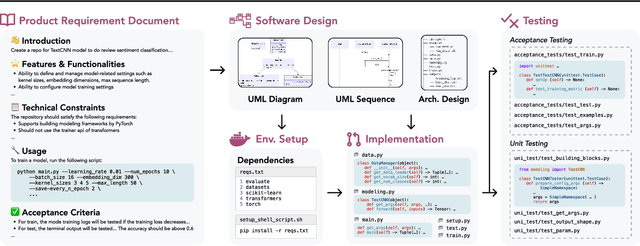
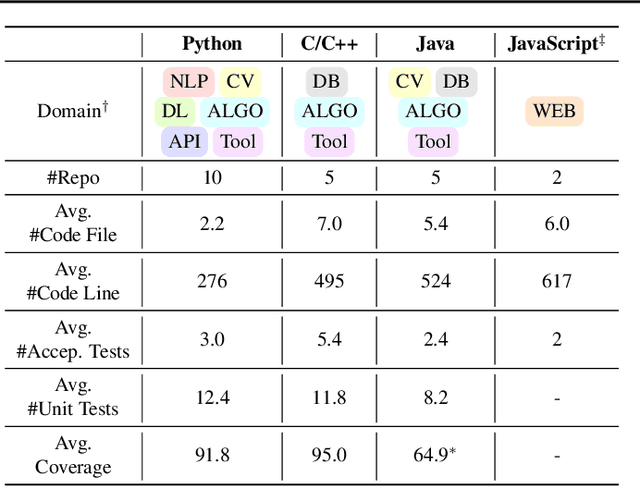
Recent advancements in large language models (LLMs) have significantly enhanced their coding capabilities. However, existing benchmarks predominantly focused on simplified or isolated aspects of programming, such as single-file code generation or repository issue debugging, falling short of measuring the full spectrum of challenges raised by real-world programming activities. To this end, we propose DevBench, a comprehensive benchmark that evaluates LLMs across various stages of the software development lifecycle, including software design, environment setup, implementation, acceptance testing, and unit testing. DevBench features a wide range of programming languages and domains, high-quality data collection, and carefully designed and verified metrics for each task. Empirical studies show that current LLMs, including GPT-4-Turbo, fail to solve the challenges presented within DevBench. Analyses reveal that models struggle with understanding the complex structures in the repository, managing the compilation process, and grasping advanced programming concepts. Our findings offer actionable insights for the future development of LLMs toward real-world programming applications. Our benchmark is available at https://github.com/open-compass/DevBench
FineMath: A Fine-Grained Mathematical Evaluation Benchmark for Chinese Large Language Models
Mar 12, 2024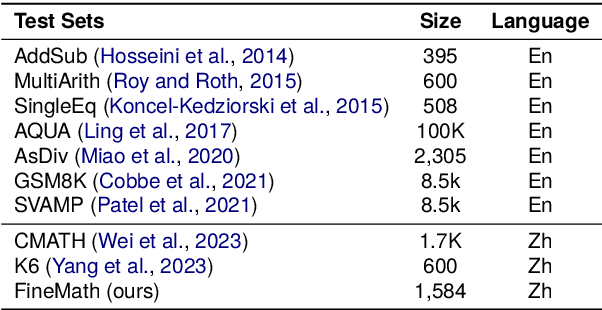
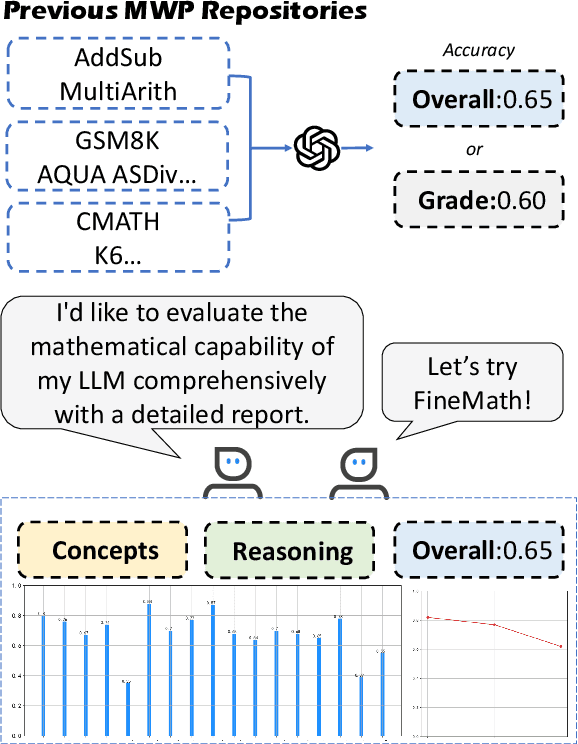
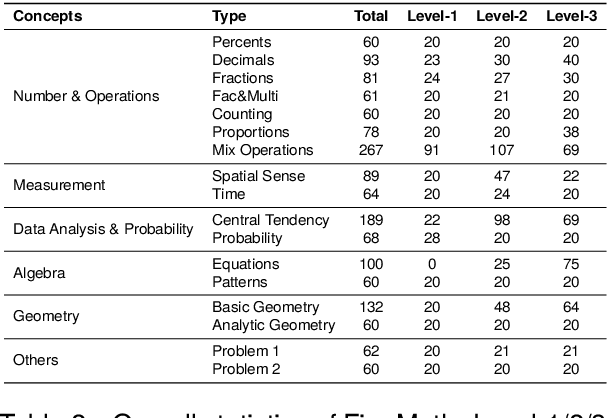
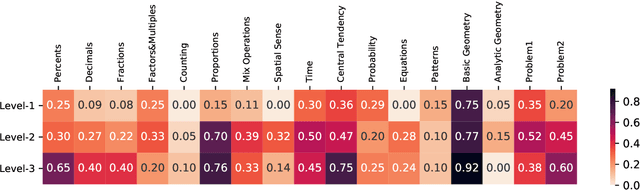
To thoroughly assess the mathematical reasoning abilities of Large Language Models (LLMs), we need to carefully curate evaluation datasets covering diverse mathematical concepts and mathematical problems at different difficulty levels. In pursuit of this objective, we propose FineMath in this paper, a fine-grained mathematical evaluation benchmark dataset for assessing Chinese LLMs. FineMath is created to cover the major key mathematical concepts taught in elementary school math, which are further divided into 17 categories of math word problems, enabling in-depth analysis of mathematical reasoning abilities of LLMs. All the 17 categories of math word problems are manually annotated with their difficulty levels according to the number of reasoning steps required to solve these problems. We conduct extensive experiments on a wide range of LLMs on FineMath and find that there is still considerable room for improvements in terms of mathematical reasoning capability of Chinese LLMs. We also carry out an in-depth analysis on the evaluation process and methods that have been overlooked previously. These two factors significantly influence the model results and our understanding of their mathematical reasoning capabilities. The dataset will be publicly available soon.
A Survey on Query-based API Recommendation
Dec 21, 2023Application Programming Interfaces (APIs) are designed to help developers build software more effectively. Recommending the right APIs for specific tasks has gained increasing attention among researchers and developers in recent years. To comprehensively understand this research domain, we have surveyed to analyze API recommendation studies published in the last 10 years. Our study begins with an overview of the structure of API recommendation tools. Subsequently, we systematically analyze prior research and pose four key research questions. For RQ1, we examine the volume of published papers and the venues in which these papers appear within the API recommendation field. In RQ2, we categorize and summarize the prevalent data sources and collection methods employed in API recommendation research. In RQ3, we explore the types of data and common data representations utilized by API recommendation approaches. We also investigate the typical data extraction procedures and collection approaches employed by the existing approaches. RQ4 delves into the modeling techniques employed by API recommendation approaches, encompassing both statistical and deep learning models. Additionally, we compile an overview of the prevalent ranking strategies and evaluation metrics used for assessing API recommendation tools. Drawing from our survey findings, we identify current challenges in API recommendation research that warrant further exploration, along with potential avenues for future research.
Curriculum Learning for Relative Overgeneralization
Dec 06, 2022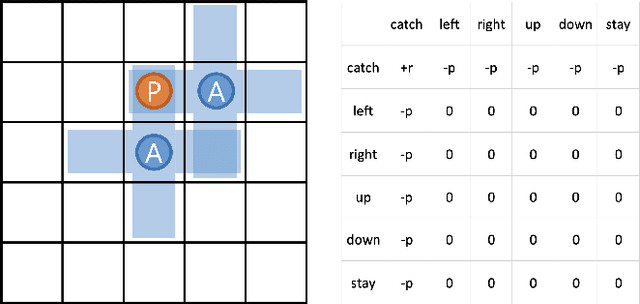
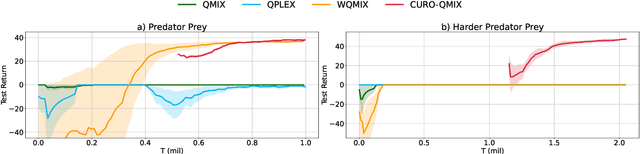
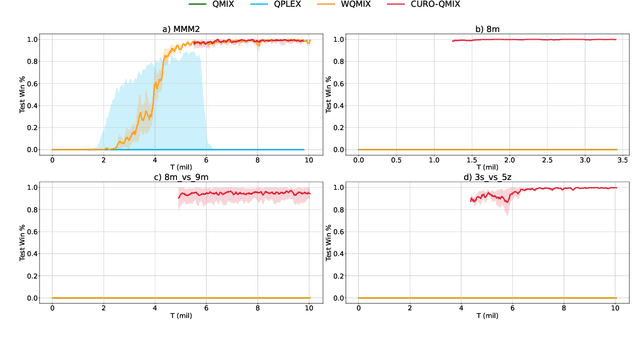
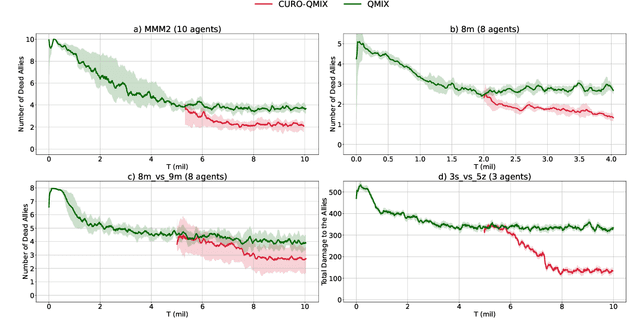
In multi-agent reinforcement learning (MARL), many popular methods, such as VDN and QMIX, are susceptible to a critical multi-agent pathology known as relative overgeneralization (RO), which arises when the optimal joint action's utility falls below that of a sub-optimal joint action in cooperative tasks. RO can cause the agents to get stuck into local optima or fail to solve tasks that require significant coordination between agents within a given timestep. Recent value-based MARL algorithms such as QPLEX and WQMIX can overcome RO to some extent. However, our experimental results show that they can still fail to solve cooperative tasks that exhibit strong RO. In this work, we propose a novel approach called curriculum learning for relative overgeneralization (CURO) to better overcome RO. To solve a target task that exhibits strong RO, in CURO, we first fine-tune the reward function of the target task to generate source tasks that are tailored to the current ability of the learning agent and train the agent on these source tasks first. Then, to effectively transfer the knowledge acquired in one task to the next, we use a novel transfer learning method that combines value function transfer with buffer transfer, which enables more efficient exploration in the target task. We demonstrate that, when applied to QMIX, CURO overcomes severe RO problem and significantly improves performance, yielding state-of-the-art results in a variety of cooperative multi-agent tasks, including the challenging StarCraft II micromanagement benchmarks.
Automatic Comment Generation via Multi-Pass Deliberation
Sep 14, 2022



Deliberation is a common and natural behavior in human daily life. For example, when writing papers or articles, we usually first write drafts, and then iteratively polish them until satisfied. In light of such a human cognitive process, we propose DECOM, which is a multi-pass deliberation framework for automatic comment generation. DECOM consists of multiple Deliberation Models and one Evaluation Model. Given a code snippet, we first extract keywords from the code and retrieve a similar code fragment from a pre-defined corpus. Then, we treat the comment of the retrieved code as the initial draft and input it with the code and keywords into DECOM to start the iterative deliberation process. At each deliberation, the deliberation model polishes the draft and generates a new comment. The evaluation model measures the quality of the newly generated comment to determine whether to end the iterative process or not. When the iterative process is terminated, the best-generated comment will be selected as the target comment. Our approach is evaluated on two real-world datasets in Java (87K) and Python (108K), and experiment results show that our approach outperforms the state-of-the-art baselines. A human evaluation study also confirms the comments generated by DECOM tend to be more readable, informative, and useful.
VTLayout: Fusion of Visual and Text Features for Document Layout Analysis
Aug 12, 2021



Documents often contain complex physical structures, which make the Document Layout Analysis (DLA) task challenging. As a pre-processing step for content extraction, DLA has the potential to capture rich information in historical or scientific documents on a large scale. Although many deep-learning-based methods from computer vision have already achieved excellent performance in detecting \emph{Figure} from documents, they are still unsatisfactory in recognizing the \emph{List}, \emph{Table}, \emph{Text} and \emph{Title} category blocks in DLA. This paper proposes a VTLayout model fusing the documents' deep visual, shallow visual, and text features to localize and identify different category blocks. The model mainly includes two stages, and the three feature extractors are built in the second stage. In the first stage, the Cascade Mask R-CNN model is applied directly to localize all category blocks of the documents. In the second stage, the deep visual, shallow visual, and text features are extracted for fusion to identify the category blocks of documents. As a result, we strengthen the classification power of different category blocks based on the existing localization technique. The experimental results show that the identification capability of the VTLayout is superior to the most advanced method of DLA based on the PubLayNet dataset, and the F1 score is as high as 0.9599.
QC-SPHRAM: Quasi-conformal Spherical Harmonics Based Geometric Distortions on Hippocampal Surfaces for Early Detection of the Alzheimer's Disease
Mar 20, 2020



We propose a disease classification model, called the QC-SPHARM, for the early detection of the Alzheimer's Disease (AD). The proposed QC-SPHARM can distinguish between normal control (NC) subjects and AD patients, as well as between amnestic mild cognitive impairment (aMCI) patients having high possibility progressing into AD and those who do not. Using the spherical harmonics (SPHARM) based registration, hippocampal surfaces segmented from the ADNI data are individually registered to a template surface constructed from the NC subjects using SPHARM. Local geometric distortions of the deformation from the template surface to each subject are quantified in terms of conformality distortions and curvatures distortions. The measurements are combined with the spherical harmonics coefficients and the total volume change of the subject from the template. Afterwards, a t-test based feature selection method incorporating the bagging strategy is applied to extract those local regions having high discriminating power of the two classes. The disease diagnosis machine can therefore be built using the data under the Support Vector Machine (SVM) setting. Using 110 NC subjects and 110 AD patients from the ADNI database, the proposed algorithm achieves 85:2% testing accuracy on 80 random samples as testing subjects, with the incorporation of surface geometry in the classification machine. Using 20 aMCI patients who has advanced to AD during a two-year period and another 20 aMCI patients who remain non-AD for the next two years, the algorithm achieves 81:2% accuracy using 10 randomly picked subjects as testing data. Our proposed method is 6%-15% better than other classification models without the incorporation of surface geometry. The results demonstrate the advantages of using local geometric distortions as the discriminating criterion for early AD diagnosis.