 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJosiah P. Hanna
On-Policy Policy Gradient Reinforcement Learning Without On-Policy Sampling
Nov 14, 2023
On-policy reinforcement learning (RL) algorithms perform policy updates using i.i.d. trajectories collected by the current policy. However, after observing only a finite number of trajectories, on-policy sampling may produce data that fails to match the expected on-policy data distribution. This sampling error leads to noisy updates and data inefficient on-policy learning. Recent work in the policy evaluation setting has shown that non-i.i.d., off-policy sampling can produce data with lower sampling error than on-policy sampling can produce. Motivated by this observation, we introduce an adaptive, off-policy sampling method to improve the data efficiency of on-policy policy gradient algorithms. Our method, Proximal Robust On-Policy Sampling (PROPS), reduces sampling error by collecting data with a behavior policy that increases the probability of sampling actions that are under-sampled with respect to the current policy. Rather than discarding data from old policies -- as is commonly done in on-policy algorithms -- PROPS uses data collection to adjust the distribution of previously collected data to be approximately on-policy. We empirically evaluate PROPS on both continuous-action MuJoCo benchmark tasks as well as discrete-action tasks and demonstrate that (1) PROPS decreases sampling error throughout training and (2) improves the data efficiency of on-policy policy gradient algorithms. Our work improves the RL community's understanding of a nuance in the on-policy vs off-policy dichotomy: on-policy learning requires on-policy data, not on-policy sampling.
Multi-task Representation Learning for Pure Exploration in Bilinear Bandits
Nov 01, 2023We study multi-task representation learning for the problem of pure exploration in bilinear bandits. In bilinear bandits, an action takes the form of a pair of arms from two different entity types and the reward is a bilinear function of the known feature vectors of the arms. In the \textit{multi-task bilinear bandit problem}, we aim to find optimal actions for multiple tasks that share a common low-dimensional linear representation. The objective is to leverage this characteristic to expedite the process of identifying the best pair of arms for all tasks. We propose the algorithm GOBLIN that uses an experimental design approach to optimize sample allocations for learning the global representation as well as minimize the number of samples needed to identify the optimal pair of arms in individual tasks. To the best of our knowledge, this is the first study to give sample complexity analysis for pure exploration in bilinear bandits with shared representation. Our results demonstrate that by learning the shared representation across tasks, we achieve significantly improved sample complexity compared to the traditional approach of solving tasks independently.
State-Action Similarity-Based Representations for Off-Policy Evaluation
Oct 27, 2023In reinforcement learning, off-policy evaluation (OPE) is the problem of estimating the expected return of an evaluation policy given a fixed dataset that was collected by running one or more different policies. One of the more empirically successful algorithms for OPE has been the fitted q-evaluation (FQE) algorithm that uses temporal difference updates to learn an action-value function, which is then used to estimate the expected return of the evaluation policy. Typically, the original fixed dataset is fed directly into FQE to learn the action-value function of the evaluation policy. Instead, in this paper, we seek to enhance the data-efficiency of FQE by first transforming the fixed dataset using a learned encoder, and then feeding the transformed dataset into FQE. To learn such an encoder, we introduce an OPE-tailored state-action behavioral similarity metric, and use this metric and the fixed dataset to learn an encoder that models this metric. Theoretically, we show that this metric allows us to bound the error in the resulting OPE estimate. Empirically, we show that other state-action similarity metrics lead to representations that cannot represent the action-value function of the evaluation policy, and that our state-action representation method boosts the data-efficiency of FQE and lowers OPE error relative to other OPE-based representation learning methods on challenging OPE tasks. We also empirically show that the learned representations significantly mitigate divergence of FQE under varying distribution shifts. Our code is available here: https://github.com/Badger-RL/ROPE.
Guided Data Augmentation for Offline Reinforcement Learning and Imitation Learning
Oct 27, 2023Learning from demonstration (LfD) is a popular technique that uses expert demonstrations to learn robot control policies. However, the difficulty in acquiring expert-quality demonstrations limits the applicability of LfD methods: real-world data collection is often costly, and the quality of the demonstrations depends greatly on the demonstrator's abilities and safety concerns. A number of works have leveraged data augmentation (DA) to inexpensively generate additional demonstration data, but most DA works generate augmented data in a random fashion and ultimately produce highly suboptimal data. In this work, we propose Guided Data Augmentation (GuDA), a human-guided DA framework that generates expert-quality augmented data. The key insight of GuDA is that while it may be difficult to demonstrate the sequence of actions required to produce expert data, a user can often easily identify when an augmented trajectory segment represents task progress. Thus, the user can impose a series of simple rules on the DA process to automatically generate augmented samples that approximate expert behavior. To extract a policy from GuDA, we use off-the-shelf offline reinforcement learning and behavior cloning algorithms. We evaluate GuDA on a physical robot soccer task as well as simulated D4RL navigation tasks, a simulated autonomous driving task, and a simulated soccer task. Empirically, we find that GuDA enables learning from a small set of potentially suboptimal demonstrations and substantially outperforms a DA strategy that samples augmented data randomly.
Understanding when Dynamics-Invariant Data Augmentations Benefit Model-Free Reinforcement Learning Updates
Oct 26, 2023Recently, data augmentation (DA) has emerged as a method for leveraging domain knowledge to inexpensively generate additional data in reinforcement learning (RL) tasks, often yielding substantial improvements in data efficiency. While prior work has demonstrated the utility of incorporating augmented data directly into model-free RL updates, it is not well-understood when a particular DA strategy will improve data efficiency. In this paper, we seek to identify general aspects of DA responsible for observed learning improvements. Our study focuses on sparse-reward tasks with dynamics-invariant data augmentation functions, serving as an initial step towards a more general understanding of DA and its integration into RL training. Experimentally, we isolate three relevant aspects of DA: state-action coverage, reward density, and the number of augmented transitions generated per update (the augmented replay ratio). From our experiments, we draw two conclusions: (1) increasing state-action coverage often has a much greater impact on data efficiency than increasing reward density, and (2) decreasing the augmented replay ratio substantially improves data efficiency. In fact, certain tasks in our empirical study are solvable only when the replay ratio is sufficiently low.
Tackling Unbounded State Spaces in Continuing Task Reinforcement Learning
Jun 02, 2023



While deep reinforcement learning (RL) algorithms have been successfully applied to many tasks, their inability to extrapolate and strong reliance on episodic resets inhibits their applicability to many real-world settings. For instance, in stochastic queueing problems, the state space can be unbounded and the agent may have to learn online without the system ever being reset to states the agent has seen before. In such settings, we show that deep RL agents can diverge into unseen states from which they can never recover due to the lack of resets, especially in highly stochastic environments. Towards overcoming this divergence, we introduce a Lyapunov-inspired reward shaping approach that encourages the agent to first learn to be stable (i.e. to achieve bounded cost) and then to learn to be optimal. We theoretically show that our reward shaping technique reduces the rate of divergence of the agent and empirically find that it prevents it. We further combine our reward shaping approach with a weight annealing scheme that gradually introduces optimality and log-transform of state inputs, and find that these techniques enable deep RL algorithms to learn high performing policies when learning online in unbounded state space domains.
Conditional Mutual Information for Disentangled Representations in Reinforcement Learning
May 23, 2023



Reinforcement Learning (RL) environments can produce training data with spurious correlations between features due to the amount of training data or its limited feature coverage. This can lead to RL agents encoding these misleading correlations in their latent representation, preventing the agent from generalising if the correlation changes within the environment or when deployed in the real world. Disentangled representations can improve robustness, but existing disentanglement techniques that minimise mutual information between features require independent features, thus they cannot disentangle correlated features. We propose an auxiliary task for RL algorithms that learns a disentangled representation of high-dimensional observations with correlated features by minimising the conditional mutual information between features in the representation. We demonstrate experimentally, using continuous control tasks, that our approach improves generalisation under correlation shifts, as well as improving the training performance of RL algorithms in the presence of correlated features.
Safe Evaluation For Offline Learning: Are We Ready To Deploy?
Dec 16, 2022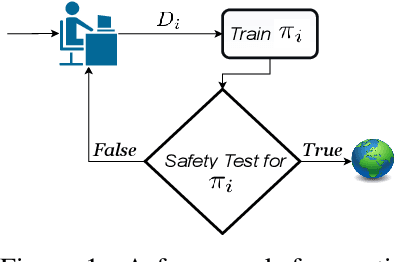
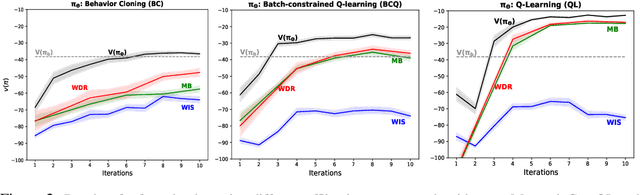
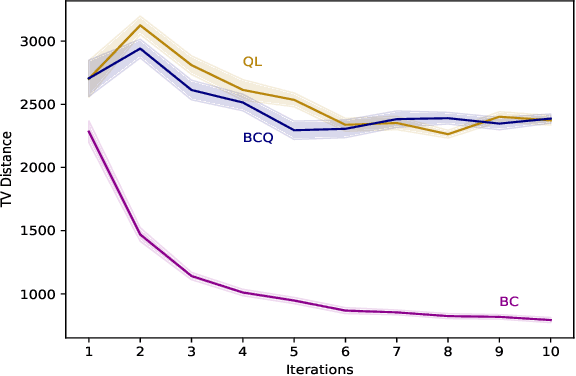
The world currently offers an abundance of data in multiple domains, from which we can learn reinforcement learning (RL) policies without further interaction with the environment. RL agents learning offline from such data is possible but deploying them while learning might be dangerous in domains where safety is critical. Therefore, it is essential to find a way to estimate how a newly-learned agent will perform if deployed in the target environment before actually deploying it and without the risk of overestimating its true performance. To achieve this, we introduce a framework for safe evaluation of offline learning using approximate high-confidence off-policy evaluation (HCOPE) to estimate the performance of offline policies during learning. In our setting, we assume a source of data, which we split into a train-set, to learn an offline policy, and a test-set, to estimate a lower-bound on the offline policy using off-policy evaluation with bootstrapping. A lower-bound estimate tells us how good a newly-learned target policy would perform before it is deployed in the real environment, and therefore allows us to decide when to deploy our learned policy.
Scaling Marginalized Importance Sampling to High-Dimensional State-Spaces via State Abstraction
Dec 14, 2022



We consider the problem of off-policy evaluation (OPE) in reinforcement learning (RL), where the goal is to estimate the performance of an evaluation policy, $\pi_e$, using a fixed dataset, $\mathcal{D}$, collected by one or more policies that may be different from $\pi_e$. Current OPE algorithms may produce poor OPE estimates under policy distribution shift i.e., when the probability of a particular state-action pair occurring under $\pi_e$ is very different from the probability of that same pair occurring in $\mathcal{D}$ (Voloshin et al. 2021, Fu et al. 2021). In this work, we propose to improve the accuracy of OPE estimators by projecting the high-dimensional state-space into a low-dimensional state-space using concepts from the state abstraction literature. Specifically, we consider marginalized importance sampling (MIS) OPE algorithms which compute state-action distribution correction ratios to produce their OPE estimate. In the original ground state-space, these ratios may have high variance which may lead to high variance OPE. However, we prove that in the lower-dimensional abstract state-space the ratios can have lower variance resulting in lower variance OPE. We then highlight the challenges that arise when estimating the abstract ratios from data, identify sufficient conditions to overcome these issues, and present a minimax optimization problem whose solution yields these abstract ratios. Finally, our empirical evaluation on difficult, high-dimensional state-space OPE tasks shows that the abstract ratios can make MIS OPE estimators achieve lower mean-squared error and more robust to hyperparameter tuning than the ground ratios.
A Joint Imitation-Reinforcement Learning Framework for Reduced Baseline Regret
Sep 20, 2022


In various control task domains, existing controllers provide a baseline level of performance that -- though possibly suboptimal -- should be maintained. Reinforcement learning (RL) algorithms that rely on extensive exploration of the state and action space can be used to optimize a control policy. However, fully exploratory RL algorithms may decrease performance below a baseline level during training. In this paper, we address the issue of online optimization of a control policy while minimizing regret w.r.t a baseline policy performance. We present a joint imitation-reinforcement learning framework, denoted JIRL. The learning process in JIRL assumes the availability of a baseline policy and is designed with two objectives in mind \textbf{(a)} leveraging the baseline's online demonstrations to minimize the regret w.r.t the baseline policy during training, and \textbf{(b)} eventually surpassing the baseline performance. JIRL addresses these objectives by initially learning to imitate the baseline policy and gradually shifting control from the baseline to an RL agent. Experimental results show that JIRL effectively accomplishes the aforementioned objectives in several, continuous action-space domains. The results demonstrate that JIRL is comparable to a state-of-the-art algorithm in its final performance while incurring significantly lower baseline regret during training in all of the presented domains. Moreover, the results show a reduction factor of up to $21$ in baseline regret over a state-of-the-art baseline regret minimization approach.