 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJulien Grand-Clément
Last-Iterate Convergence Properties of Regret-Matching Algorithms in Games
Nov 01, 2023
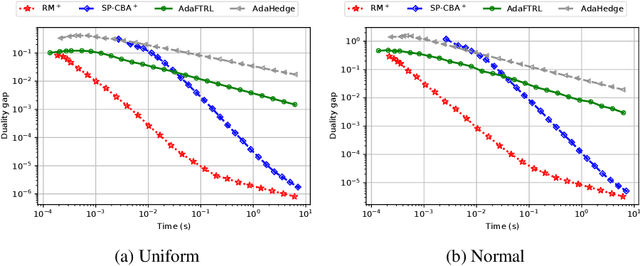
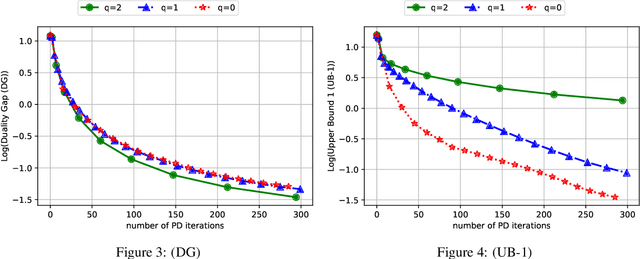
Algorithms based on regret matching, specifically regret matching$^+$ (RM$^+$), and its variants are the most popular approaches for solving large-scale two-player zero-sum games in practice. Unlike algorithms such as optimistic gradient descent ascent, which have strong last-iterate and ergodic convergence properties for zero-sum games, virtually nothing is known about the last-iterate properties of regret-matching algorithms. Given the importance of last-iterate convergence for numerical optimization reasons and relevance as modeling real-word learning in games, in this paper, we study the last-iterate convergence properties of various popular variants of RM$^+$. First, we show numerically that several practical variants such as simultaneous RM$^+$, alternating RM$^+$, and simultaneous predictive RM$^+$, all lack last-iterate convergence guarantees even on a simple $3\times 3$ game. We then prove that recent variants of these algorithms based on a smoothing technique do enjoy last-iterate convergence: we prove that extragradient RM$^{+}$ and smooth Predictive RM$^+$ enjoy asymptotic last-iterate convergence (without a rate) and $1/\sqrt{t}$ best-iterate convergence. Finally, we introduce restarted variants of these algorithms, and show that they enjoy linear-rate last-iterate convergence.
Regret Matching+: (In)Stability and Fast Convergence in Games
May 24, 2023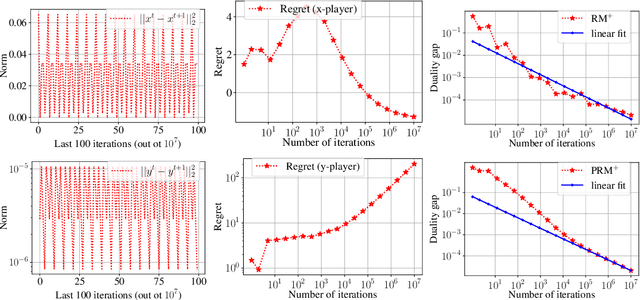
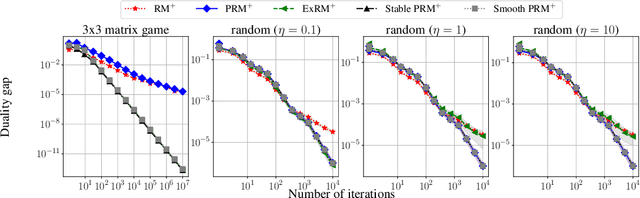
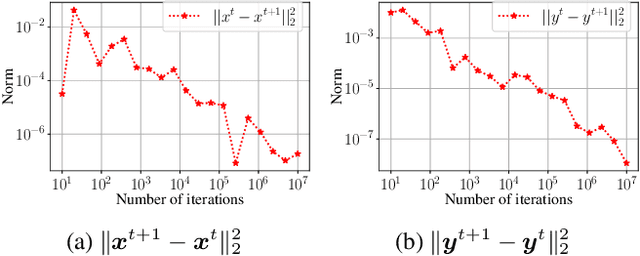
Regret Matching+ (RM+) and its variants are important algorithms for solving large-scale games. However, a theoretical understanding of their success in practice is still a mystery. Moreover, recent advances on fast convergence in games are limited to no-regret algorithms such as online mirror descent, which satisfy stability. In this paper, we first give counterexamples showing that RM+ and its predictive version can be unstable, which might cause other players to suffer large regret. We then provide two fixes: restarting and chopping off the positive orthant that RM+ works in. We show that these fixes are sufficient to get $O(T^{1/4})$ individual regret and $O(1)$ social regret in normal-form games via RM+ with predictions. We also apply our stabilizing techniques to clairvoyant updates in the uncoupled learning setting for RM+ and prove desirable results akin to recent works for Clairvoyant online mirror descent. Our experiments show the advantages of our algorithms over vanilla RM+-based algorithms in matrix and extensive-form games.
Reducing Blackwell and Average Optimality to Discounted MDPs via the Blackwell Discount Factor
Jan 31, 2023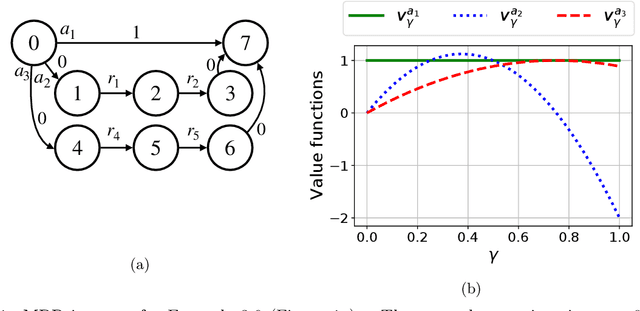
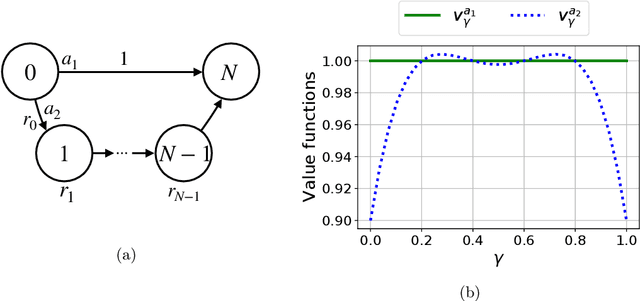
We introduce the Blackwell discount factor for Markov Decision Processes (MDPs). Classical objectives for MDPs include discounted, average, and Blackwell optimality. Many existing approaches to computing average-optimal policies solve for discounted optimal policies with a discount factor close to $1$, but they only work under strong or hard-to-verify assumptions such as ergodicity or weakly communicating MDPs. In this paper, we show that when the discount factor is larger than the Blackwell discount factor $\gamma_{\mathrm{bw}}$, all discounted optimal policies become Blackwell- and average-optimal, and we derive a general upper bound on $\gamma_{\mathrm{bw}}$. The upper bound on $\gamma_{\mathrm{bw}}$ provides the first reduction from average and Blackwell optimality to discounted optimality, without any assumptions, and new polynomial-time algorithms for average- and Blackwell-optimal policies. Our work brings new ideas from the study of polynomials and algebraic numbers to the analysis of MDPs. Our results also apply to robust MDPs, enabling the first algorithms to compute robust Blackwell-optimal policies.
On the convex formulations of robust Markov decision processes
Sep 21, 2022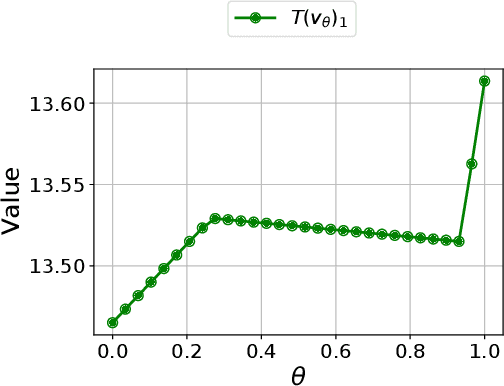
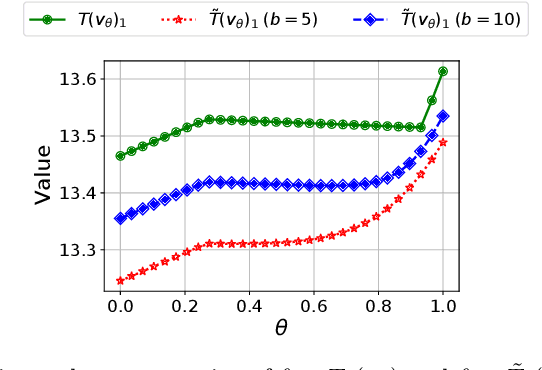
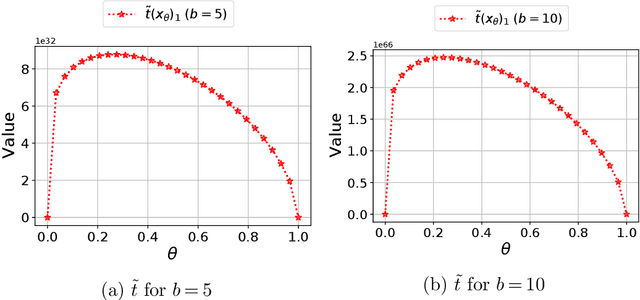
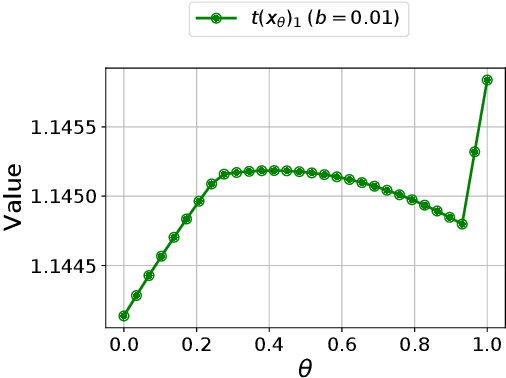
Robust Markov decision processes (MDPs) are used for applications of dynamic optimization in uncertain environments and have been studied extensively. Many of the main properties and algorithms of MDPs, such as value iteration and policy iteration, extend directly to RMDPs. Surprisingly, there is no known analog of the MDP convex optimization formulation for solving RMDPs. This work describes the first convex optimization formulation of RMDPs under the classical sa-rectangularity and s-rectangularity assumptions. We derive a convex formulation with a linear number of variables and constraints but large coefficients in the constraints by using entropic regularization and exponential change of variables. Our formulation can be combined with efficient methods from convex optimization to obtain new algorithms for solving RMDPs with uncertain probabilities. We further simplify the formulation for RMDPs with polyhedral uncertainty sets. Our work opens a new research direction for RMDPs and can serve as a first step toward obtaining a tractable convex formulation of RMDPs.
The Best Decisions Are Not the Best Advice: Making Adherence-Aware Recommendations
Sep 07, 2022

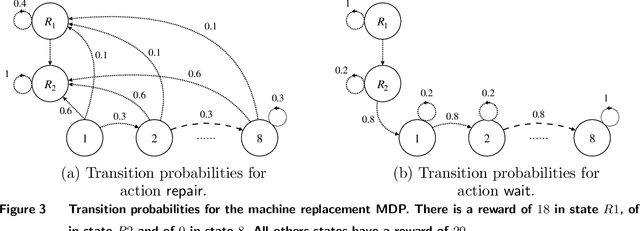

Many high-stake decisions follow an expert-in-loop structure in that a human operator receives recommendations from an algorithm but is the ultimate decision maker. Hence, the algorithm's recommendation may differ from the actual decision implemented in practice. However, most algorithmic recommendations are obtained by solving an optimization problem that assumes recommendations will be perfectly implemented. We propose an adherence-aware optimization framework to capture the dichotomy between the recommended and the implemented policy and analyze the impact of partial adherence on the optimal recommendation. We show that overlooking the partial adherence phenomenon, as is currently being done by most recommendation engines, can lead to arbitrarily severe performance deterioration, compared with both the current human baseline performance and what is expected by the recommendation algorithm. Our framework also provides useful tools to analyze the structure and to compute optimal recommendation policies that are naturally immune against such human deviations, and are guaranteed to improve upon the baseline policy.
Solving optimization problems with Blackwell approachability
Feb 24, 2022
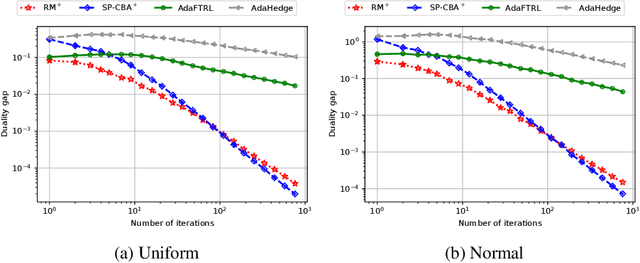
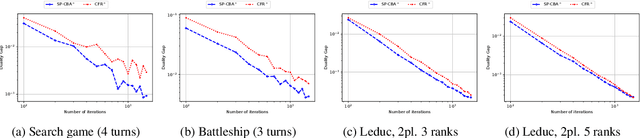
We introduce the Conic Blackwell Algorithm$^+$ (CBA$^+$) regret minimizer, a new parameter- and scale-free regret minimizer for general convex sets. CBA$^+$ is based on Blackwell approachability and attains $O(\sqrt{T})$ regret. We show how to efficiently instantiate CBA$^+$ for many decision sets of interest, including the simplex, $\ell_{p}$ norm balls, and ellipsoidal confidence regions in the simplex. Based on CBA$^+$, we introduce SP-CBA$^+$, a new parameter-free algorithm for solving convex-concave saddle-point problems, which achieves a $O(1/\sqrt{T})$ ergodic rate of convergence. In our simulations, we demonstrate the wide applicability of SP-CBA$^+$ on several standard saddle-point problems, including matrix games, extensive-form games, distributionally robust logistic regression, and Markov decision processes. In each setting, SP-CBA$^+$ achieves state-of-the-art numerical performance, and outperforms classical methods, without the need for any choice of step sizes or other algorithmic parameters.
Interpretable Machine Learning for Resource Allocation with Application to Ventilator Triage
Oct 21, 2021
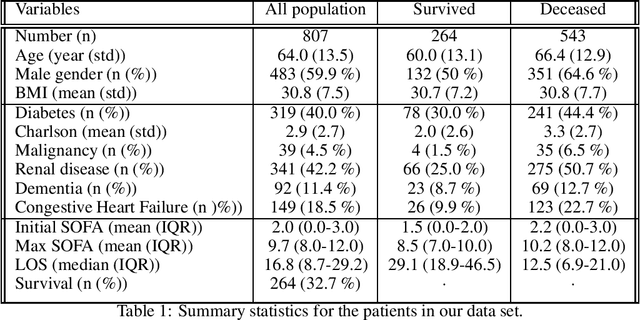
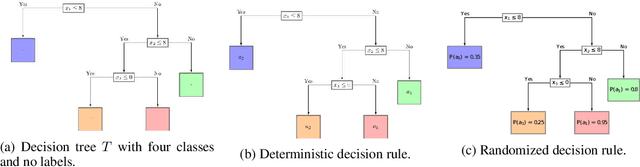
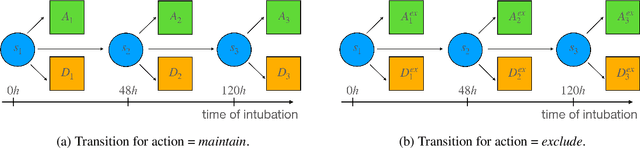
Rationing of healthcare resources is a challenging decision that policy makers and providers may be forced to make during a pandemic, natural disaster, or mass casualty event. Well-defined guidelines to triage scarce life-saving resources must be designed to promote transparency, trust, and consistency. To facilitate buy-in and use during high-stress situations, these guidelines need to be interpretable and operational. We propose a novel data-driven model to compute interpretable triage guidelines based on policies for Markov Decision Process that can be represented as simple sequences of decision trees ("tree policies"). In particular, we characterize the properties of optimal tree policies and present an algorithm based on dynamic programming recursions to compute good tree policies. We utilize this methodology to obtain simple, novel triage guidelines for ventilator allocations for COVID-19 patients, based on real patient data from Montefiore hospitals. We also compare the performance of our guidelines to the official New York State guidelines that were developed in 2015 (well before the COVID-19 pandemic). Our empirical study shows that the number of excess deaths associated with ventilator shortages could be reduced significantly using our policy. Our work highlights the limitations of the existing official triage guidelines, which need to be adapted specifically to COVID-19 before being successfully deployed.
Conic Blackwell Algorithm: Parameter-Free Convex-Concave Saddle-Point Solving
Jun 10, 2021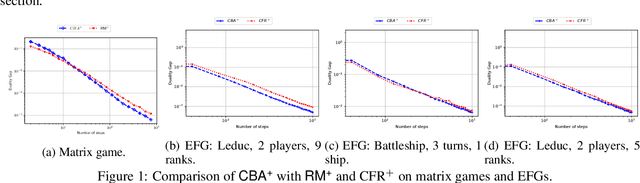
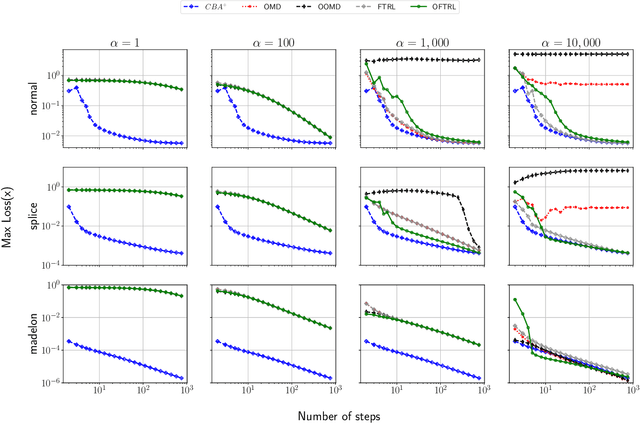
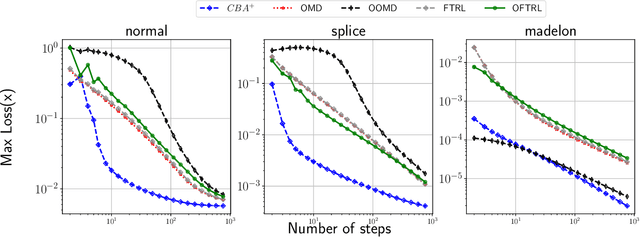
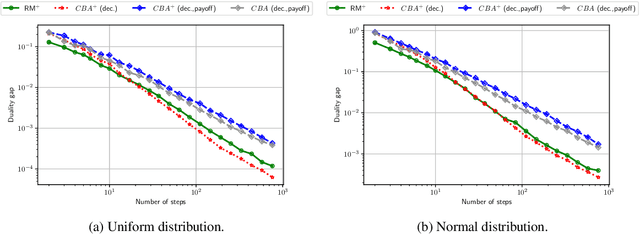
We develop new parameter and scale-free algorithms for solving convex-concave saddle-point problems. Our results are based on a new simple regret minimizer, the Conic Blackwell Algorithm$^+$ (CBA$^+$), which attains $O(1/\sqrt{T})$ average regret. Intuitively, our approach generalizes to other decision sets of interest ideas from the Counterfactual Regret minimization (CFR$^+$) algorithm, which has very strong practical performance for solving sequential games on simplexes. We show how to implement CBA$^+$ for the simplex, $\ell_{p}$ norm balls, and ellipsoidal confidence regions in the simplex, and we present numerical experiments for solving matrix games and distributionally robust optimization problems. Our empirical results show that CBA$^+$ is a simple algorithm that outperforms state-of-the-art methods on synthetic data and real data instances, without the need for any choice of step sizes or other algorithmic parameters.
Scalable First-Order Methods for Robust MDPs
Jun 05, 2020


Markov Decision Processes (MDPs) are a widely used model for dynamic decision-making problems. However, MDPs require precise specification of model parameters, and often the cost of a policy can be highly sensitive to the estimated parameters. Robust MDPs ameliorate this issue by allowing one to specify uncertainty sets around the parameters, which leads to a non-convex optimization problem. This non-convex problem can be solved via the Value Iteration algorithm, but Value Iteration requires repeatedly solving convex programs that become prohibitively expensive as MDPs grow larger. We propose an algorithmic framework based on first-order methods, where we interleave approximate value iteration updates with a first-order-based computation of the robust Bellman update. Our algorithm relies on having a proximal setup for the uncertainty sets. We go on to instantiate this proximal setup for $s$-rectangular ellipsoidal uncertainty sets and Kullback-Leibler uncertainty sets. By carefully controlling the warm-starts of our first-order method and the increasing approximation rate at each Value Iteration update, our algorithm achieves a convergence rate of $O \left( A^{2} S^{3}\log(S)\log(\epsilon^{-1}) \epsilon^{-1} \right)$ for the best choice of parameters, where $S,A$ are the numbers of states and actions. Our dependence on the number of states and actions is significantly better than that of Value Iteration algorithms. In numerical experiments on ellipsoidal uncertainty sets, we show that our algorithm is significantly more scalable than state-of-the-art approaches. In the class of $s$-rectangular robust MDPs, to the best of our knowledge, our algorithm is the first to address Kullback-Leibler uncertainty sets.