 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJunyi Peng
Target Speech Extraction with Pre-trained Self-supervised Learning Models
Feb 17, 2024




Pre-trained self-supervised learning (SSL) models have achieved remarkable success in various speech tasks. However, their potential in target speech extraction (TSE) has not been fully exploited. TSE aims to extract the speech of a target speaker in a mixture guided by enrollment utterances. We exploit pre-trained SSL models for two purposes within a TSE framework, i.e., to process the input mixture and to derive speaker embeddings from the enrollment. In this paper, we focus on how to effectively use SSL models for TSE. We first introduce a novel TSE downstream task following the SUPERB principles. This simple experiment shows the potential of SSL models for TSE, but extraction performance remains far behind the state-of-the-art. We then extend a powerful TSE architecture by incorporating two SSL-based modules: an Adaptive Input Enhancer (AIE) and a speaker encoder. Specifically, the proposed AIE utilizes intermediate representations from the CNN encoder by adjusting the time resolution of CNN encoder and transformer blocks through progressive upsampling, capturing both fine-grained and hierarchical features. Our method outperforms current TSE systems achieving a SI-SDR improvement of 14.0 dB on LibriMix. Moreover, we can further improve performance by 0.7 dB by fine-tuning the whole model including the SSL model parameters.
Probing Self-supervised Learning Models with Target Speech Extraction
Feb 17, 2024Large-scale pre-trained self-supervised learning (SSL) models have shown remarkable advancements in speech-related tasks. However, the utilization of these models in complex multi-talker scenarios, such as extracting a target speaker in a mixture, is yet to be fully evaluated. In this paper, we introduce target speech extraction (TSE) as a novel downstream task to evaluate the feature extraction capabilities of pre-trained SSL models. TSE uniquely requires both speaker identification and speech separation, distinguishing it from other tasks in the Speech processing Universal PERformance Benchmark (SUPERB) evaluation. Specifically, we propose a TSE downstream model composed of two lightweight task-oriented modules based on the same frozen SSL model. One module functions as a speaker encoder to obtain target speaker information from an enrollment speech, while the other estimates the target speaker's mask to extract its speech from the mixture. Experimental results on the Libri2mix datasets reveal the relevance of the TSE downstream task to probe SSL models, as its performance cannot be simply deduced from other related tasks such as speaker verification and separation.
Improving Speaker Verification with Self-Pretrained Transformer Models
May 17, 2023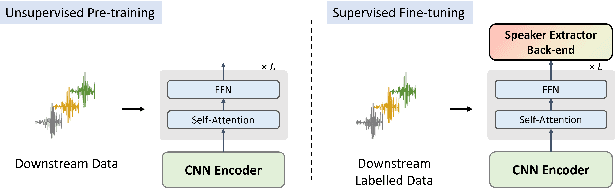

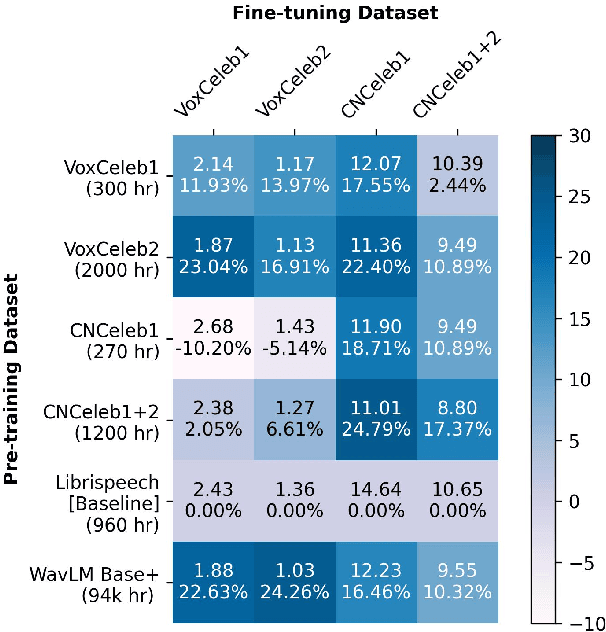
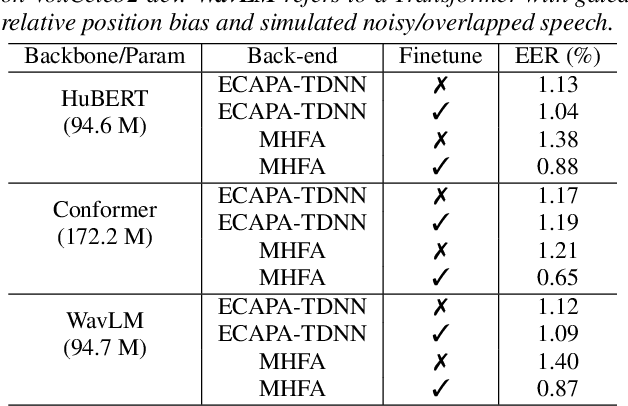
Recently, fine-tuning large pre-trained Transformer models using downstream datasets has received a rising interest. Despite their success, it is still challenging to disentangle the benefits of large-scale datasets and Transformer structures from the limitations of the pre-training. In this paper, we introduce a hierarchical training approach, named self-pretraining, in which Transformer models are pretrained and finetuned on the same dataset. Three pre-trained models including HuBERT, Conformer and WavLM are evaluated on four different speaker verification datasets with varying sizes. Our experiments show that these self-pretrained models achieve competitive performance on downstream speaker verification tasks with only one-third of the data compared to Librispeech pretraining, such as VoxCeleb1 and CNCeleb1. Furthermore, when pre-training only on the VoxCeleb2-dev, the Conformer model outperforms the one pre-trained on 94k hours of data using the same fine-tuning settings.
Probing Deep Speaker Embeddings for Speaker-related Tasks
Dec 14, 2022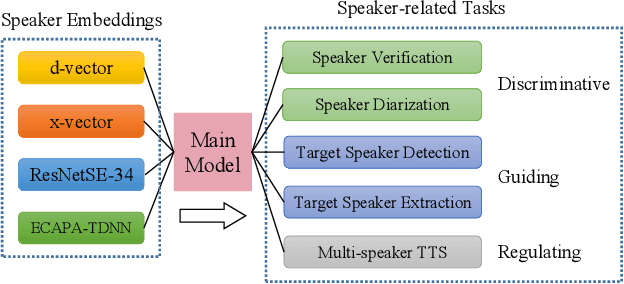

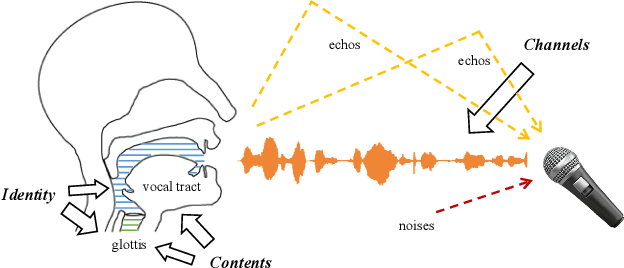
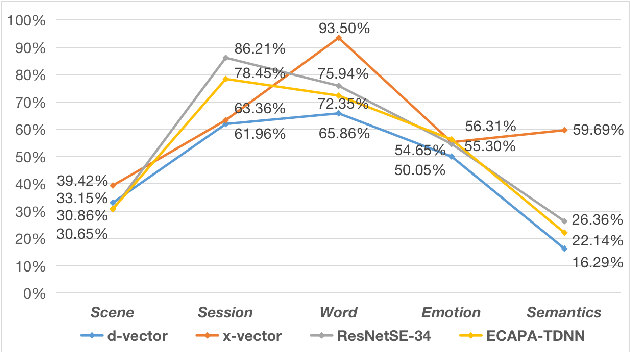
Deep speaker embeddings have shown promising results in speaker recognition, as well as in other speaker-related tasks. However, some issues are still under explored, for instance, the information encoded in these representations and their influence on downstream tasks. Four deep speaker embeddings are studied in this paper, namely, d-vector, x-vector, ResNetSE-34 and ECAPA-TDNN. Inspired by human voice mechanisms, we explored possibly encoded information from perspectives of identity, contents and channels; Based on this, experiments were conducted on three categories of speaker-related tasks to further explore impacts of different deep embeddings, including discriminative tasks (speaker verification and diarization), guiding tasks (target speaker detection and extraction) and regulating tasks (multi-speaker text-to-speech). Results show that all deep embeddings encoded channel and content information in addition to speaker identity, but the extent could vary and their performance on speaker-related tasks can be tremendously different: ECAPA-TDNN is dominant in discriminative tasks, and d-vector leads the guiding tasks, while regulating task is less sensitive to the choice of speaker representations. These may benefit future research utilizing speaker embeddings.
Parameter-efficient transfer learning of pre-trained Transformer models for speaker verification using adapters
Oct 28, 2022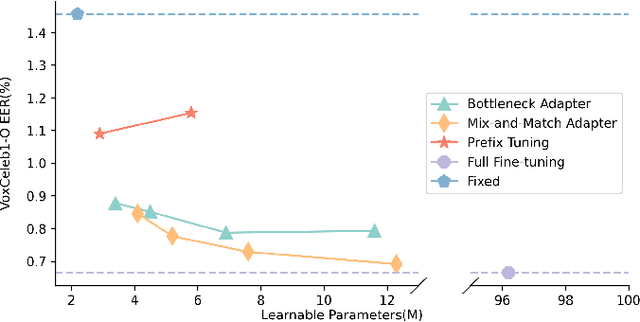
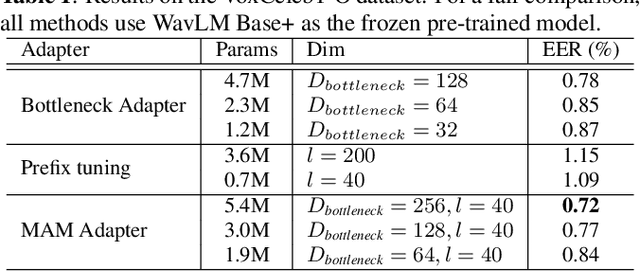
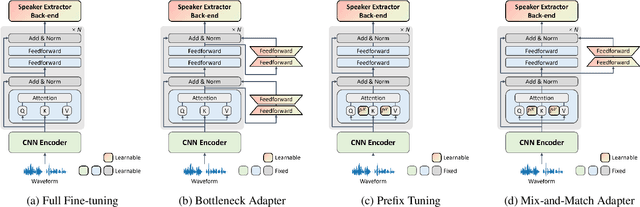
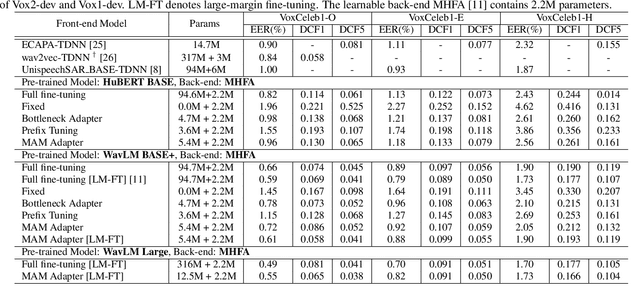
Recently, the pre-trained Transformer models have received a rising interest in the field of speech processing thanks to their great success in various downstream tasks. However, most fine-tuning approaches update all the parameters of the pre-trained model, which becomes prohibitive as the model size grows and sometimes results in overfitting on small datasets. In this paper, we conduct a comprehensive analysis of applying parameter-efficient transfer learning (PETL) methods to reduce the required learnable parameters for adapting to speaker verification tasks. Specifically, during the fine-tuning process, the pre-trained models are frozen, and only lightweight modules inserted in each Transformer block are trainable (a method known as adapters). Moreover, to boost the performance in a cross-language low-resource scenario, the Transformer model is further tuned on a large intermediate dataset before directly fine-tuning it on a small dataset. With updating fewer than 4% of parameters, (our proposed) PETL-based methods achieve comparable performances with full fine-tuning methods (Vox1-O: 0.55%, Vox1-E: 0.82%, Vox1-H:1.73%).
An attention-based backend allowing efficient fine-tuning of transformer models for speaker verification
Oct 03, 2022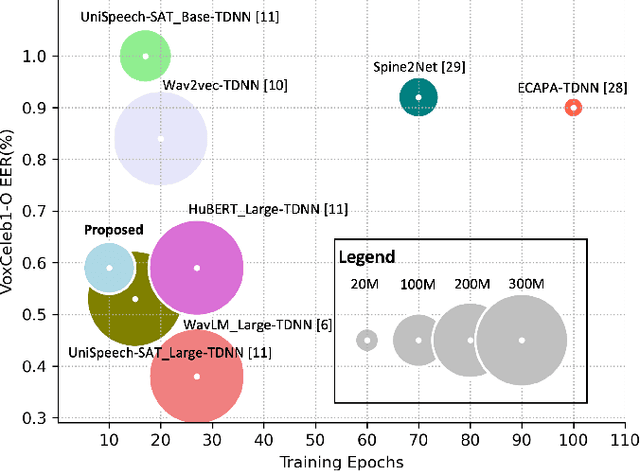

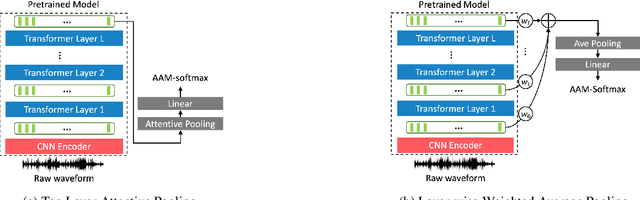

In recent years, self-supervised learning paradigm has received extensive attention due to its great success in various down-stream tasks. However, the fine-tuning strategies for adapting those pre-trained models to speaker verification task have yet to be fully explored. In this paper, we analyze several feature extraction approaches built on top of a pre-trained model, as well as regularization and learning rate schedule to stabilize the fine-tuning process and further boost performance: multi-head factorized attentive pooling is proposed to factorize the comparison of speaker representations into multiple phonetic clusters. We regularize towards the parameters of the pre-trained model and we set different learning rates for each layer of the pre-trained model during fine-tuning. The experimental results show our method can significantly shorten the training time to 4 hours and achieve SOTA performance: 0.59%, 0.79% and 1.77% EER on Vox1-O, Vox1-E and Vox1-H, respectively.