 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLukáš Burget
Beyond the Labels: Unveiling Text-Dependency in Paralinguistic Speech Recognition Datasets
Mar 12, 2024



Paralinguistic traits like cognitive load and emotion are increasingly recognized as pivotal areas in speech recognition research, often examined through specialized datasets like CLSE and IEMOCAP. However, the integrity of these datasets is seldom scrutinized for text-dependency. This paper critically evaluates the prevalent assumption that machine learning models trained on such datasets genuinely learn to identify paralinguistic traits, rather than merely capturing lexical features. By examining the lexical overlap in these datasets and testing the performance of machine learning models, we expose significant text-dependency in trait-labeling. Our results suggest that some machine learning models, especially large pre-trained models like HuBERT, might inadvertently focus on lexical characteristics rather than the intended paralinguistic features. The study serves as a call to action for the research community to reevaluate the reliability of existing datasets and methodologies, ensuring that machine learning models genuinely learn what they are designed to recognize.
Do End-to-End Neural Diarization Attractors Need to Encode Speaker Characteristic Information?
Feb 29, 2024In this paper, we apply the variational information bottleneck approach to end-to-end neural diarization with encoder-decoder attractors (EEND-EDA). This allows us to investigate what information is essential for the model. EEND-EDA utilizes vector representations of the speakers in a conversation - attractors. Our analysis shows that, attractors do not necessarily have to contain speaker characteristic information. On the other hand, giving the attractors more freedom allowing them to encode some extra (possibly speaker-specific) information leads to small but consistent diarization performance improvements. Despite architectural differences in EEND systems, the notion of attractors and frame embeddings is common to most of them and not specific to EEND-EDA. We believe that the main conclusions of this work can apply to other variants of EEND. Thus, we hope this paper will be a valuable contribution to guide the community to make more informed decisions when designing new systems.
DiaPer: End-to-End Neural Diarization with Perceiver-Based Attractors
Dec 22, 2023Until recently, the field of speaker diarization was dominated by cascaded systems. Due to their limitations, mainly regarding overlapped speech and cumbersome pipelines, end-to-end models have gained great popularity lately. One of the most successful models is end-to-end neural diarization with encoder-decoder based attractors (EEND-EDA). In this work, we replace the EDA module with a Perceiver-based one and show its advantages over EEND-EDA; namely obtaining better performance on the largely studied Callhome dataset, finding the quantity of speakers in a conversation more accurately, and running inference on almost half of the time on long recordings. Furthermore, when exhaustively compared with other methods, our model, DiaPer, reaches remarkable performance with a very lightweight design. Besides, we perform comparisons with other works and a cascaded baseline across more than ten public wide-band datasets. Together with this publication, we release the code of DiaPer as well as models trained on public and free data.
Discriminative Training of VBx Diarization
Oct 04, 2023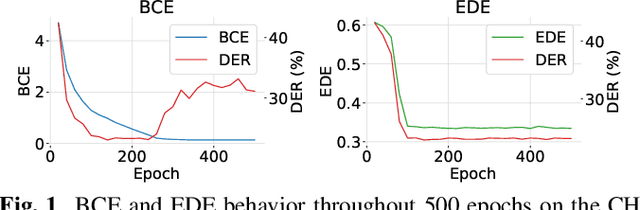
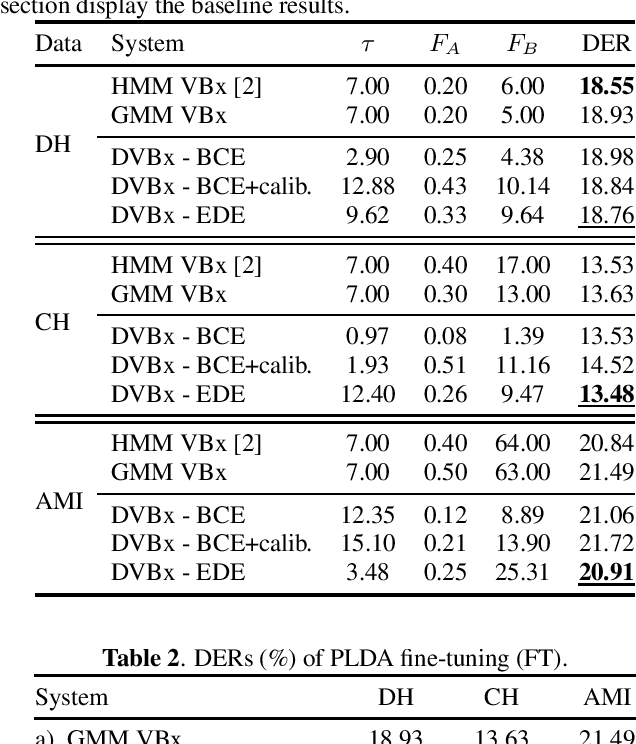
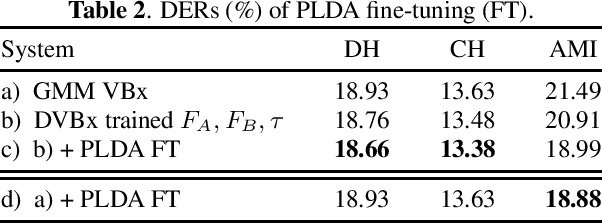
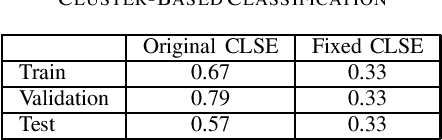
Bayesian HMM clustering of x-vector sequences (VBx) has become a widely adopted diarization baseline model in publications and challenges. It uses an HMM to model speaker turns, a generatively trained probabilistic linear discriminant analysis (PLDA) for speaker distribution modeling, and Bayesian inference to estimate the assignment of x-vectors to speakers. This paper presents a new framework for updating the VBx parameters using discriminative training, which directly optimizes a predefined loss. We also propose a new loss that better correlates with the diarization error rate compared to binary cross-entropy $\unicode{x2013}$ the default choice for diarization end-to-end systems. Proof-of-concept results across three datasets (AMI, CALLHOME, and DIHARD II) demonstrate the method's capability of automatically finding hyperparameters, achieving comparable performance to those found by extensive grid search, which typically requires additional hyperparameter behavior knowledge. Moreover, we show that discriminative fine-tuning of PLDA can further improve the model's performance. We release the source code with this publication.
Hystoc: Obtaining word confidences for fusion of end-to-end ASR systems
May 21, 2023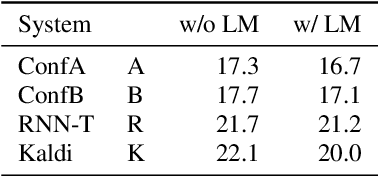
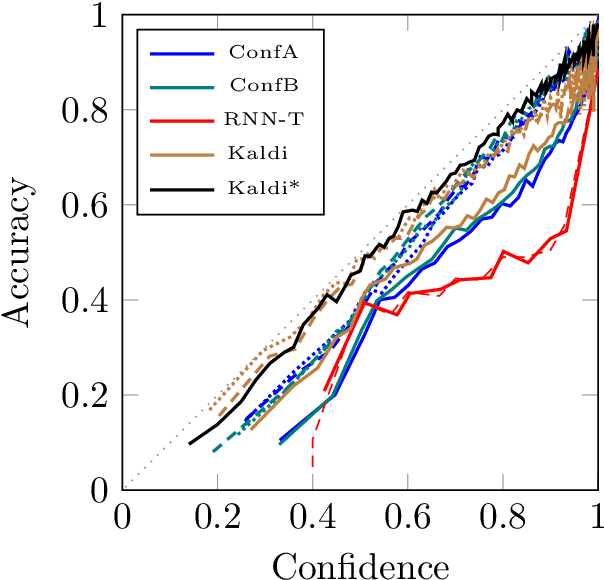
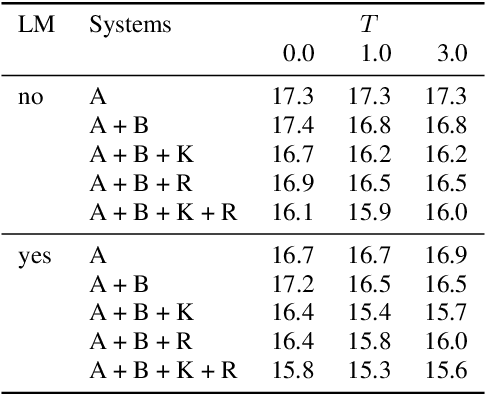
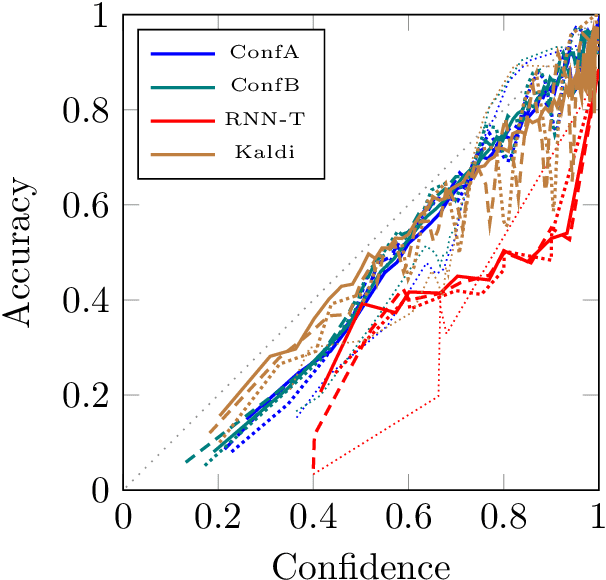
End-to-end (e2e) systems have recently gained wide popularity in automatic speech recognition. However, these systems do generally not provide well-calibrated word-level confidences. In this paper, we propose Hystoc, a simple method for obtaining word-level confidences from hypothesis-level scores. Hystoc is an iterative alignment procedure which turns hypotheses from an n-best output of the ASR system into a confusion network. Eventually, word-level confidences are obtained as posterior probabilities in the individual bins of the confusion network. We show that Hystoc provides confidences that correlate well with the accuracy of the ASR hypothesis. Furthermore, we show that utilizing Hystoc in fusion of multiple e2e ASR systems increases the gains from the fusion by up to 1\,\% WER absolute on Spanish RTVE2020 dataset. Finally, we experiment with using Hystoc for direct fusion of n-best outputs from multiple systems, but we only achieve minor gains when fusing very similar systems.
Improving Speaker Verification with Self-Pretrained Transformer Models
May 17, 2023

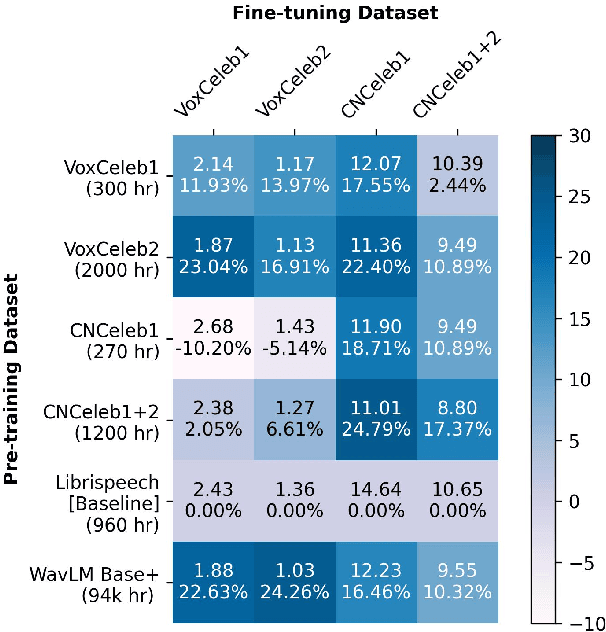
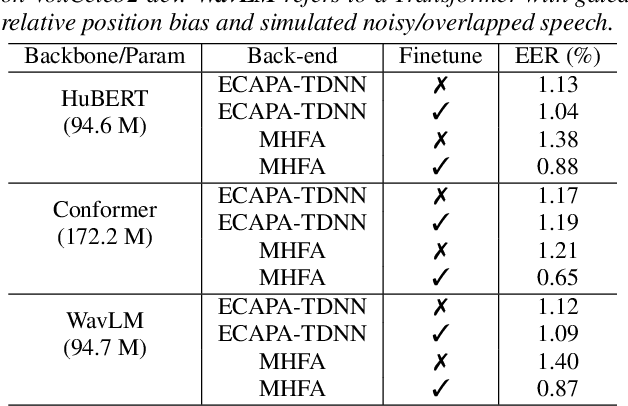
Recently, fine-tuning large pre-trained Transformer models using downstream datasets has received a rising interest. Despite their success, it is still challenging to disentangle the benefits of large-scale datasets and Transformer structures from the limitations of the pre-training. In this paper, we introduce a hierarchical training approach, named self-pretraining, in which Transformer models are pretrained and finetuned on the same dataset. Three pre-trained models including HuBERT, Conformer and WavLM are evaluated on four different speaker verification datasets with varying sizes. Our experiments show that these self-pretrained models achieve competitive performance on downstream speaker verification tasks with only one-third of the data compared to Librispeech pretraining, such as VoxCeleb1 and CNCeleb1. Furthermore, when pre-training only on the VoxCeleb2-dev, the Conformer model outperforms the one pre-trained on 94k hours of data using the same fine-tuning settings.
Multi-Speaker and Wide-Band Simulated Conversations as Training Data for End-to-End Neural Diarization
Nov 12, 2022
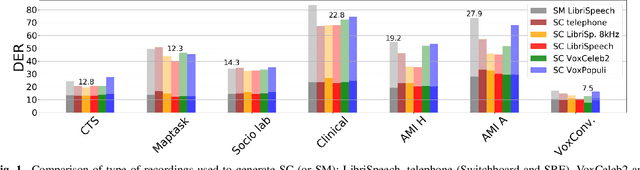


End-to-end diarization presents an attractive alternative to standard cascaded diarization systems because a single system can handle all aspects of the task at once. Many flavors of end-to-end models have been proposed but all of them require (so far non-existing) large amounts of annotated data for training. The compromise solution consists in generating synthetic data and the recently proposed simulated conversations (SC) have shown remarkable improvements over the original simulated mixtures (SM). In this work, we create SC with multiple speakers per conversation and show that they allow for substantially better performance than SM, also reducing the dependence on a fine-tuning stage. We also create SC with wide-band public audio sources and present an analysis on several evaluation sets. Together with this publication, we release the recipes for generating such data and models trained on public sets as well as the implementation to efficiently handle multiple speakers per conversation and an auxiliary voice activity detection loss.
Parameter-efficient transfer learning of pre-trained Transformer models for speaker verification using adapters
Oct 28, 2022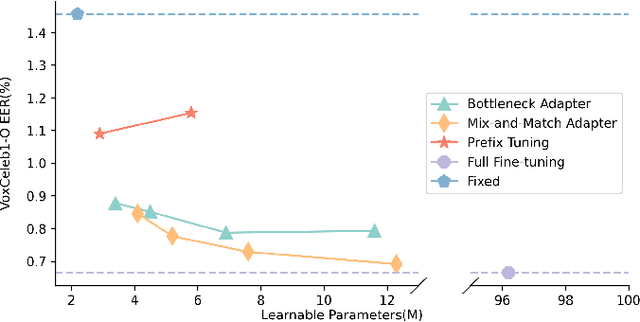
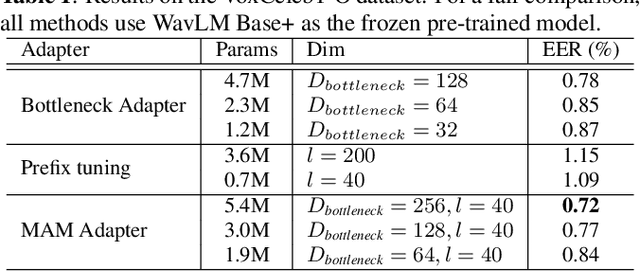
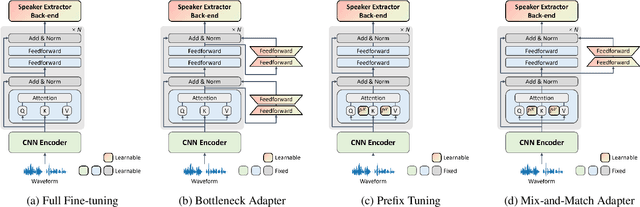
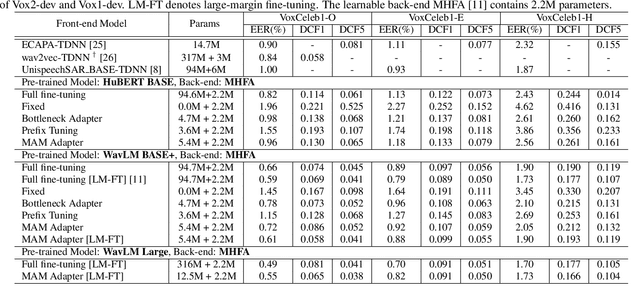
Recently, the pre-trained Transformer models have received a rising interest in the field of speech processing thanks to their great success in various downstream tasks. However, most fine-tuning approaches update all the parameters of the pre-trained model, which becomes prohibitive as the model size grows and sometimes results in overfitting on small datasets. In this paper, we conduct a comprehensive analysis of applying parameter-efficient transfer learning (PETL) methods to reduce the required learnable parameters for adapting to speaker verification tasks. Specifically, during the fine-tuning process, the pre-trained models are frozen, and only lightweight modules inserted in each Transformer block are trainable (a method known as adapters). Moreover, to boost the performance in a cross-language low-resource scenario, the Transformer model is further tuned on a large intermediate dataset before directly fine-tuning it on a small dataset. With updating fewer than 4% of parameters, (our proposed) PETL-based methods achieve comparable performances with full fine-tuning methods (Vox1-O: 0.55%, Vox1-E: 0.82%, Vox1-H:1.73%).
Toroidal Probabilistic Spherical Discriminant Analysis
Oct 27, 2022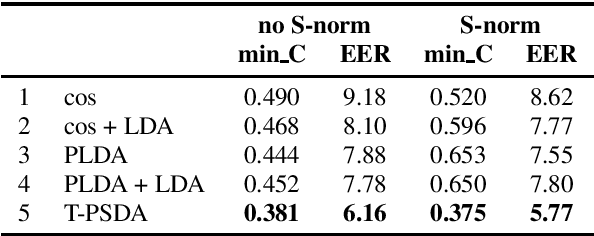
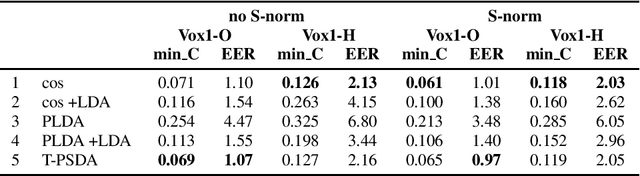
In speaker recognition, where speech segments are mapped to embeddings on the unit hypersphere, two scoring back-ends are commonly used, namely cosine scoring and PLDA. We have recently proposed PSDA, an analog to PLDA that uses Von Mises-Fisher distributions instead of Gaussians. In this paper, we present toroidal PSDA (T-PSDA). It extends PSDA with the ability to model within and between-speaker variabilities in toroidal submanifolds of the hypersphere. Like PLDA and PSDA, the model allows closed-form scoring and closed-form EM updates for training. On VoxCeleb, we find T-PSDA accuracy on par with cosine scoring, while PLDA accuracy is inferior. On NIST SRE'21 we find that T-PSDA gives large accuracy gains compared to both cosine scoring and PLDA.
From Simulated Mixtures to Simulated Conversations as Training Data for End-to-End Neural Diarization
Apr 02, 2022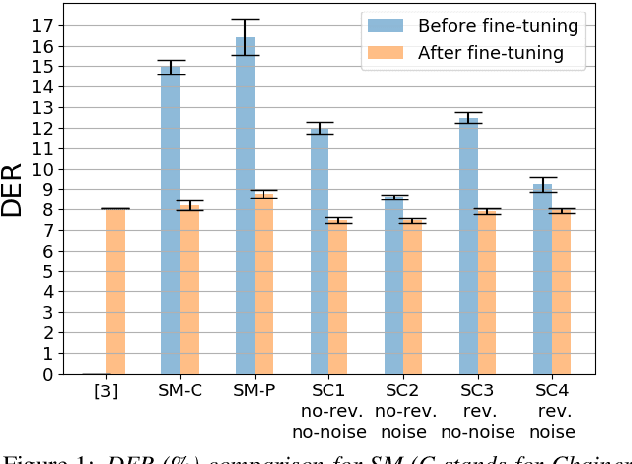
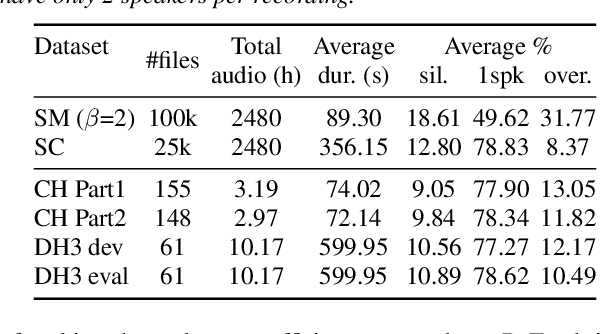

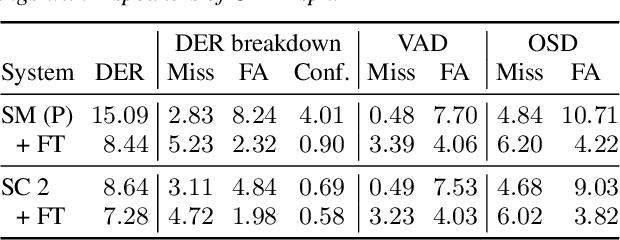
End-to-end neural diarization (EEND) is nowadays one of the most prominent research topics in speaker diarization. EEND presents an attractive alternative to standard cascaded diarization systems since a single system is trained at once to deal with the whole diarization problem. Several EEND variants and approaches are being proposed, however, all these models require large amounts of annotated data for training but available annotated data are scarce. Thus, EEND works have used mostly simulated mixtures for training. However, simulated mixtures do not resemble real conversations in many aspects. In this work we present an alternative method for creating synthetic conversations that resemble real ones by using statistics about distributions of pauses and overlaps estimated on genuine conversations. Furthermore, we analyze the effect of the source of the statistics, different augmentations and amounts of data. We demonstrate that our approach performs substantially better than the original one, while reducing the dependence on the fine-tuning stage. Experiments are carried out on 2-speaker telephone conversations of Callhome and DIHARD 3. Together with this publication, we release our implementations of EEND and the method for creating simulated conversations.