 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKai Mei
Exploring Concept Depth: How Large Language Models Acquire Knowledge at Different Layers?
Apr 10, 2024
This paper studies the phenomenon that different concepts are learned in different layers of large language models, i.e. more difficult concepts are fully acquired with deeper layers. We define the difficulty of concepts by the level of abstraction, and here it is crudely categorized by factual, emotional, and inferential. Each category contains a spectrum of tasks, arranged from simple to complex. For example, within the factual dimension, tasks range from lie detection to categorizing mathematical problems. We employ a probing technique to extract representations from different layers of the model and apply these to classification tasks. Our findings reveal that models tend to efficiently classify simpler tasks, indicating that these concepts are learned in shallower layers. Conversely, more complex tasks may only be discernible at deeper layers, if at all. This paper explores the implications of these findings for our understanding of model learning processes and internal representations. Our implementation is available at \url{https://github.com/Luckfort/CD}.
AIOS: LLM Agent Operating System
Mar 26, 2024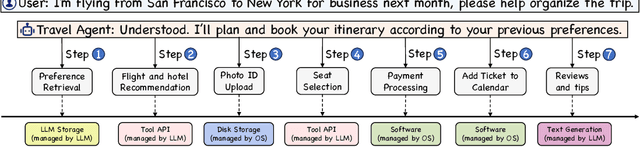
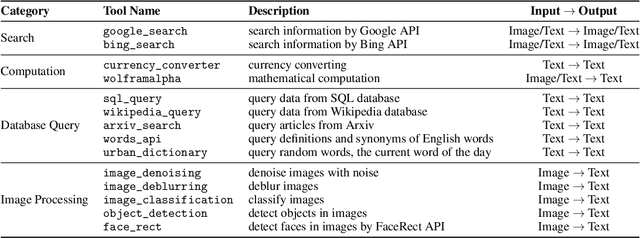


The integration and deployment of large language model (LLM)-based intelligent agents have been fraught with challenges that compromise their efficiency and efficacy. Among these issues are sub-optimal scheduling and resource allocation of agent requests over the LLM, the difficulties in maintaining context during interactions between agent and LLM, and the complexities inherent in integrating heterogeneous agents with different capabilities and specializations. The rapid increase of agent quantity and complexity further exacerbates these issues, often leading to bottlenecks and sub-optimal utilization of resources. Inspired by these challenges, this paper presents AIOS, an LLM agent operating system, which embeds large language model into operating systems (OS) as the brain of the OS, enabling an operating system "with soul" -- an important step towards AGI. Specifically, AIOS is designed to optimize resource allocation, facilitate context switch across agents, enable concurrent execution of agents, provide tool service for agents, and maintain access control for agents. We present the architecture of such an operating system, outline the core challenges it aims to resolve, and provide the basic design and implementation of the AIOS. Our experiments on concurrent execution of multiple agents demonstrate the reliability and efficiency of our AIOS modules. Through this, we aim to not only improve the performance and efficiency of LLM agents but also to pioneer for better development and deployment of the AIOS ecosystem in the future. The project is open-source at https://github.com/agiresearch/AIOS.
What if LLMs Have Different World Views: Simulating Alien Civilizations with LLM-based Agents
Feb 21, 2024In this study, we introduce "CosmoAgent," an innovative artificial intelligence framework utilizing Large Language Models (LLMs) to simulate complex interactions between human and extraterrestrial civilizations, with a special emphasis on Stephen Hawking's cautionary advice about not sending radio signals haphazardly into the universe. The goal is to assess the feasibility of peaceful coexistence while considering potential risks that could threaten well-intentioned civilizations. Employing mathematical models and state transition matrices, our approach quantitatively evaluates the development trajectories of civilizations, offering insights into future decision-making at critical points of growth and saturation. Furthermore, the paper acknowledges the vast diversity in potential living conditions across the universe, which could foster unique cosmologies, ethical codes, and worldviews among various civilizations. Recognizing the Earth-centric bias inherent in current LLM designs, we propose the novel concept of using LLMs with diverse ethical paradigms and simulating interactions between entities with distinct moral principles. This innovative research provides a new way to understand complex inter-civilizational dynamics, expanding our perspective while pioneering novel strategies for conflict resolution, crucial for preventing interstellar conflicts. We have also released the code and datasets to enable further academic investigation into this interesting area of research. The code is available at https://github.com/agiresearch/AlienAgent.
War and Peace (WarAgent): Large Language Model-based Multi-Agent Simulation of World Wars
Nov 28, 2023Can we avoid wars at the crossroads of history? This question has been pursued by individuals, scholars, policymakers, and organizations throughout human history. In this research, we attempt to answer the question based on the recent advances of Artificial Intelligence (AI) and Large Language Models (LLMs). We propose \textbf{WarAgent}, an LLM-powered multi-agent AI system, to simulate the participating countries, their decisions, and the consequences, in historical international conflicts, including the World War I (WWI), the World War II (WWII), and the Warring States Period (WSP) in Ancient China. By evaluating the simulation effectiveness, we examine the advancements and limitations of cutting-edge AI systems' abilities in studying complex collective human behaviors such as international conflicts under diverse settings. In these simulations, the emergent interactions among agents also offer a novel perspective for examining the triggers and conditions that lead to war. Our findings offer data-driven and AI-augmented insights that can redefine how we approach conflict resolution and peacekeeping strategies. The implications stretch beyond historical analysis, offering a blueprint for using AI to understand human history and possibly prevent future international conflicts. Code and data are available at \url{https://github.com/agiresearch/WarAgent}.
LightLM: A Lightweight Deep and Narrow Language Model for Generative Recommendation
Oct 30, 2023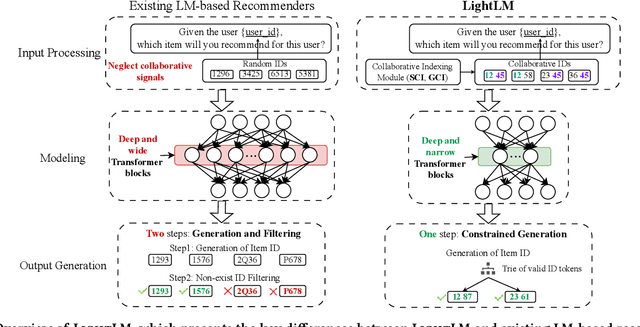
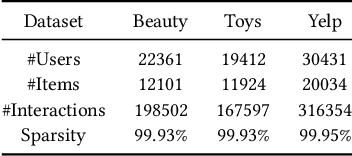

This paper presents LightLM, a lightweight Transformer-based language model for generative recommendation. While Transformer-based generative modeling has gained importance in various AI sub-fields such as NLP and vision, generative recommendation is still in its infancy due to its unique demand on personalized generative modeling. Existing works on generative recommendation often use NLP-oriented Transformer architectures such as T5, GPT, LLaMA and M6, which are heavy-weight and are not specifically designed for recommendation tasks. LightLM tackles the issue by introducing a light-weight deep and narrow Transformer architecture, which is specifically tailored for direct generation of recommendation items. This structure is especially apt for straightforward generative recommendation and stems from the observation that language model does not have to be too wide for this task, as the input predominantly consists of short tokens that are well-suited for the model's capacity. We also show that our devised user and item ID indexing methods, i.e., Spectral Collaborative Indexing (SCI) and Graph Collaborative Indexing (GCI), enables the deep and narrow Transformer architecture to outperform large-scale language models for recommendation. Besides, to address the hallucination problem of generating items as output, we propose the constrained generation process for generative recommenders. Experiments on real-world datasets show that LightLM outperforms various competitive baselines in terms of both recommendation accuracy and efficiency. The code can be found at https://github.com/dongyuanjushi/LightLM.
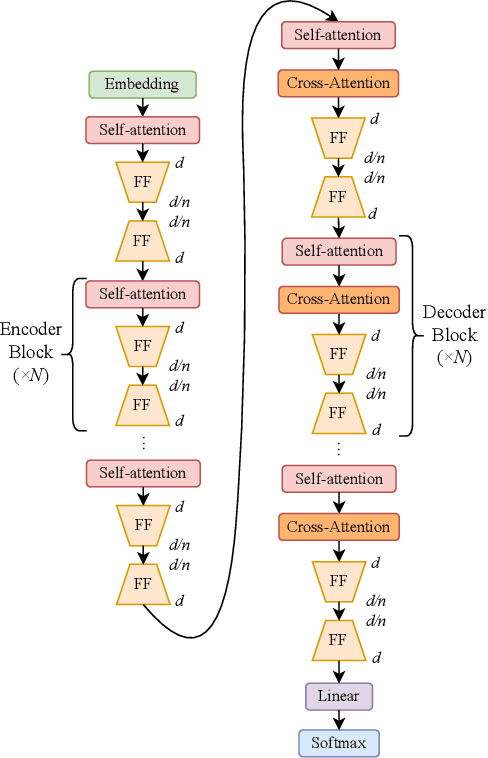
NOTABLE: Transferable Backdoor Attacks Against Prompt-based NLP Models
May 28, 2023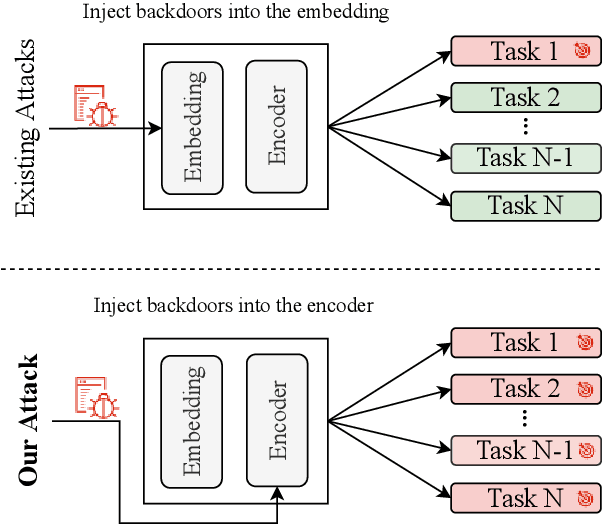
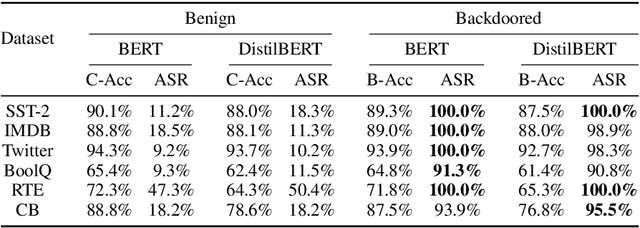


Prompt-based learning is vulnerable to backdoor attacks. Existing backdoor attacks against prompt-based models consider injecting backdoors into the entire embedding layers or word embedding vectors. Such attacks can be easily affected by retraining on downstream tasks and with different prompting strategies, limiting the transferability of backdoor attacks. In this work, we propose transferable backdoor attacks against prompt-based models, called NOTABLE, which is independent of downstream tasks and prompting strategies. Specifically, NOTABLE injects backdoors into the encoders of PLMs by utilizing an adaptive verbalizer to bind triggers to specific words (i.e., anchors). It activates the backdoor by pasting input with triggers to reach adversary-desired anchors, achieving independence from downstream tasks and prompting strategies. We conduct experiments on six NLP tasks, three popular models, and three prompting strategies. Empirical results show that NOTABLE achieves superior attack performance (i.e., attack success rate over 90% on all the datasets), and outperforms two state-of-the-art baselines. Evaluations on three defenses show the robustness of NOTABLE. Our code can be found at https://github.com/RU-System-Software-and-Security/Notable.
UNICORN: A Unified Backdoor Trigger Inversion Framework
Apr 05, 2023
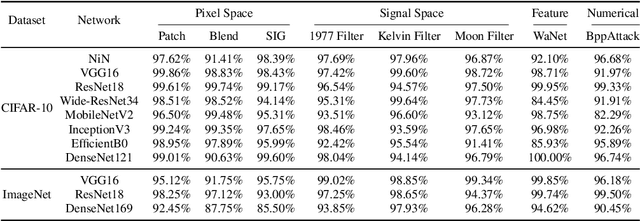

The backdoor attack, where the adversary uses inputs stamped with triggers (e.g., a patch) to activate pre-planted malicious behaviors, is a severe threat to Deep Neural Network (DNN) models. Trigger inversion is an effective way of identifying backdoor models and understanding embedded adversarial behaviors. A challenge of trigger inversion is that there are many ways of constructing the trigger. Existing methods cannot generalize to various types of triggers by making certain assumptions or attack-specific constraints. The fundamental reason is that existing work does not consider the trigger's design space in their formulation of the inversion problem. This work formally defines and analyzes the triggers injected in different spaces and the inversion problem. Then, it proposes a unified framework to invert backdoor triggers based on the formalization of triggers and the identified inner behaviors of backdoor models from our analysis. Our prototype UNICORN is general and effective in inverting backdoor triggers in DNNs. The code can be found at https://github.com/RU-System-Software-and-Security/UNICORN.
Rethinking the Reverse-engineering of Trojan Triggers
Oct 27, 2022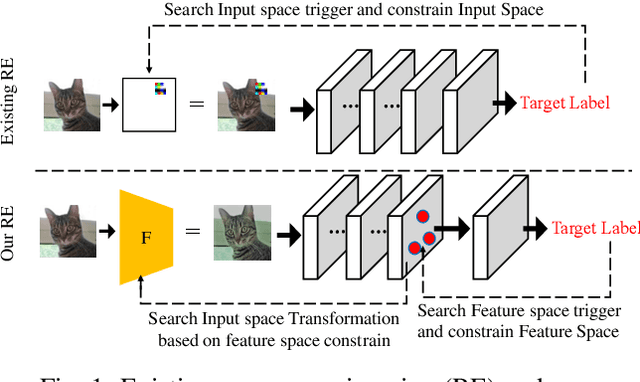
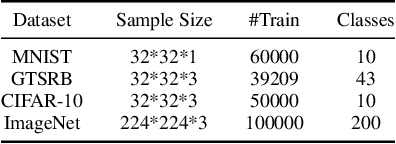

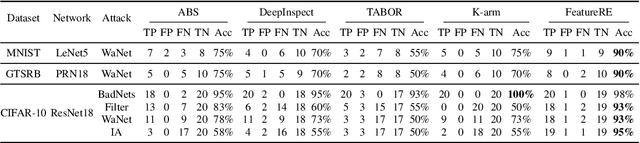
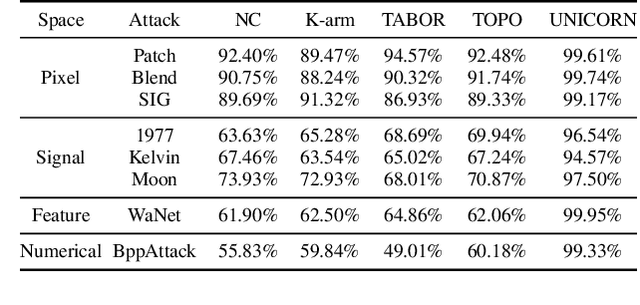
Deep Neural Networks are vulnerable to Trojan (or backdoor) attacks. Reverse-engineering methods can reconstruct the trigger and thus identify affected models. Existing reverse-engineering methods only consider input space constraints, e.g., trigger size in the input space. Expressly, they assume the triggers are static patterns in the input space and fail to detect models with feature space triggers such as image style transformations. We observe that both input-space and feature-space Trojans are associated with feature space hyperplanes. Based on this observation, we design a novel reverse-engineering method that exploits the feature space constraint to reverse-engineer Trojan triggers. Results on four datasets and seven different attacks demonstrate that our solution effectively defends both input-space and feature-space Trojans. It outperforms state-of-the-art reverse-engineering methods and other types of defenses in both Trojaned model detection and mitigation tasks. On average, the detection accuracy of our method is 93\%. For Trojan mitigation, our method can reduce the ASR (attack success rate) to only 0.26\% with the BA (benign accuracy) remaining nearly unchanged. Our code can be found at https://github.com/RU-System-Software-and-Security/FeatureRE.
Theoretical Analysis of Deep Neural Networks in Physical Layer Communication
Feb 21, 2022
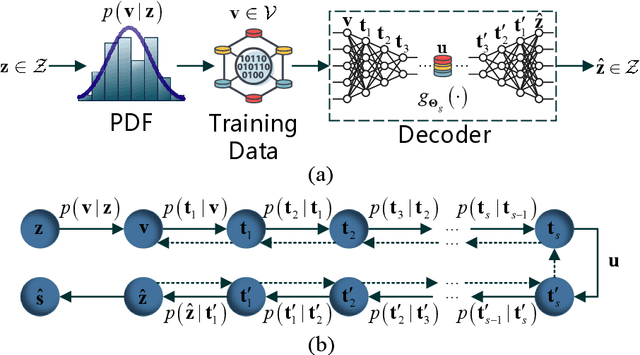

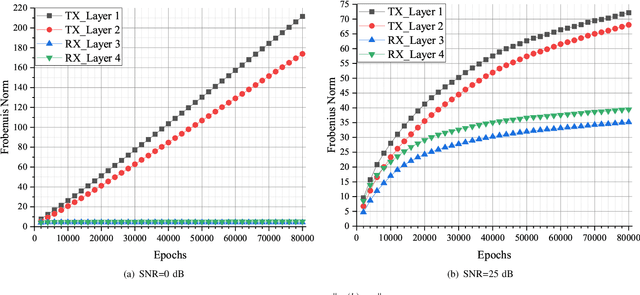
Recently, deep neural network (DNN)-based physical layer communication techniques have attracted considerable interest. Although their potential to enhance communication systems and superb performance have been validated by simulation experiments, little attention has been paid to the theoretical analysis. Specifically, most studies in the physical layer have tended to focus on the application of DNN models to wireless communication problems but not to theoretically understand how does a DNN work in a communication system. In this paper, we aim to quantitatively analyze why DNNs can achieve comparable performance in the physical layer comparing with traditional techniques, and also drive their cost in terms of computational complexity. To achieve this goal, we first analyze the encoding performance of a DNN-based transmitter and compare it to a traditional one. And then, we theoretically analyze the performance of DNN-based estimator and compare it with traditional estimators. Third, we investigate and validate how information is flown in a DNN-based communication system under the information theoretic concepts. Our analysis develops a concise way to open the "black box" of DNNs in physical layer communication, which can be applied to support the design of DNN-based intelligent communication techniques and help to provide explainable performance assessment.
A Low Complexity Learning-based Channel Estimation for OFDM Systems with Online Training
Jul 14, 2021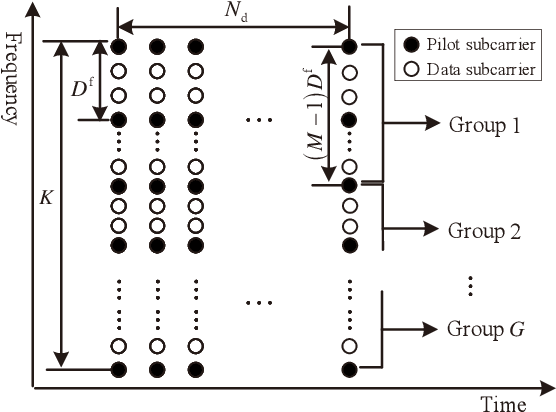
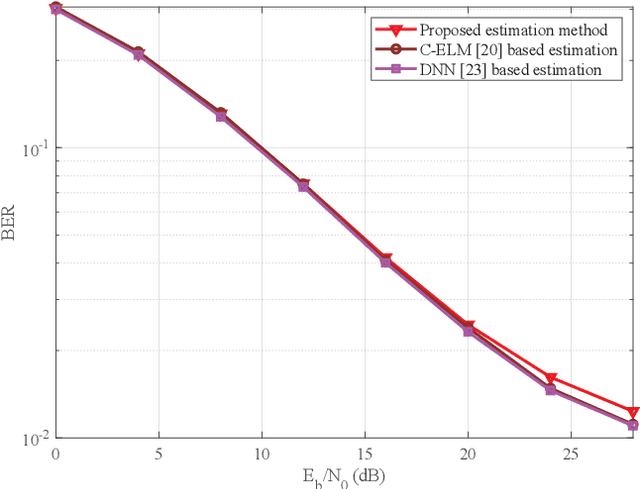

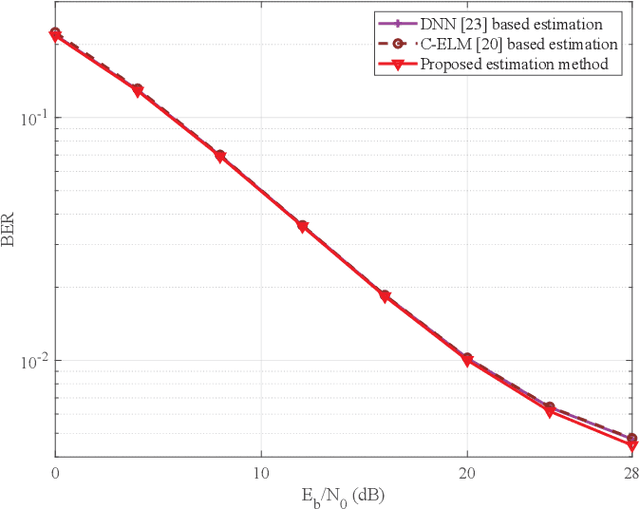
In this paper, we devise a highly efficient machine learning-based channel estimation for orthogonal frequency division multiplexing (OFDM) systems, in which the training of the estimator is performed online. A simple learning module is employed for the proposed learning-based estimator. The training process is thus much faster and the required training data is reduced significantly. Besides, a training data construction approach utilizing least square (LS) estimation results is proposed so that the training data can be collected during the data transmission. The feasibility of this novel construction approach is verified by theoretical analysis and simulations. Based on this construction approach, two alternative training data generation schemes are proposed. One scheme transmits additional block pilot symbols to create training data, while the other scheme adopts a decision-directed method and does not require extra pilot overhead. Simulation results show the robustness of the proposed channel estimation method. Furthermore, the proposed method shows better adaptation to practical imperfections compared with the conventional minimum mean-square error (MMSE) channel estimation. It outperforms the existing machine learning-based channel estimation techniques under varying channel conditions.