 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShiqing Ma
LOTUS: Evasive and Resilient Backdoor Attacks through Sub-Partitioning
Mar 25, 2024
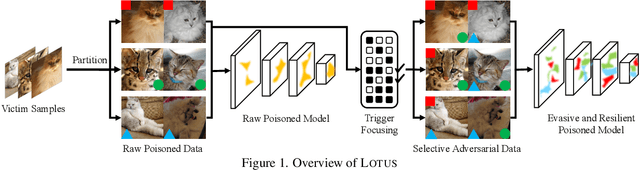
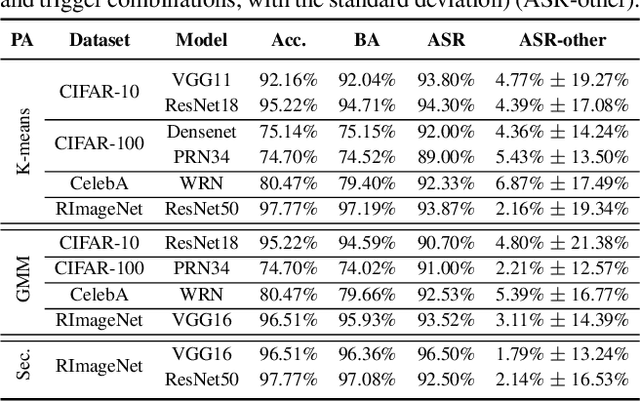

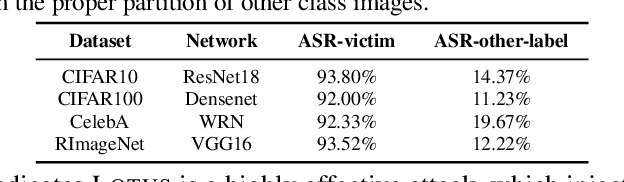
Backdoor attack poses a significant security threat to Deep Learning applications. Existing attacks are often not evasive to established backdoor detection techniques. This susceptibility primarily stems from the fact that these attacks typically leverage a universal trigger pattern or transformation function, such that the trigger can cause misclassification for any input. In response to this, recent papers have introduced attacks using sample-specific invisible triggers crafted through special transformation functions. While these approaches manage to evade detection to some extent, they reveal vulnerability to existing backdoor mitigation techniques. To address and enhance both evasiveness and resilience, we introduce a novel backdoor attack LOTUS. Specifically, it leverages a secret function to separate samples in the victim class into a set of partitions and applies unique triggers to different partitions. Furthermore, LOTUS incorporates an effective trigger focusing mechanism, ensuring only the trigger corresponding to the partition can induce the backdoor behavior. Extensive experimental results show that LOTUS can achieve high attack success rate across 4 datasets and 7 model structures, and effectively evading 13 backdoor detection and mitigation techniques. The code is available at https://github.com/Megum1/LOTUS.
SoK: Challenges and Opportunities in Federated Unlearning
Mar 04, 2024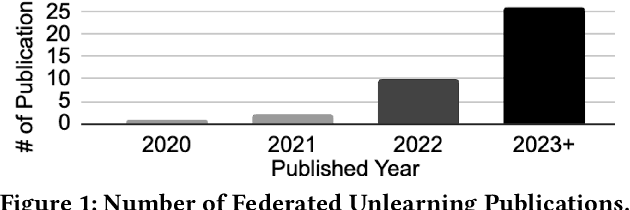
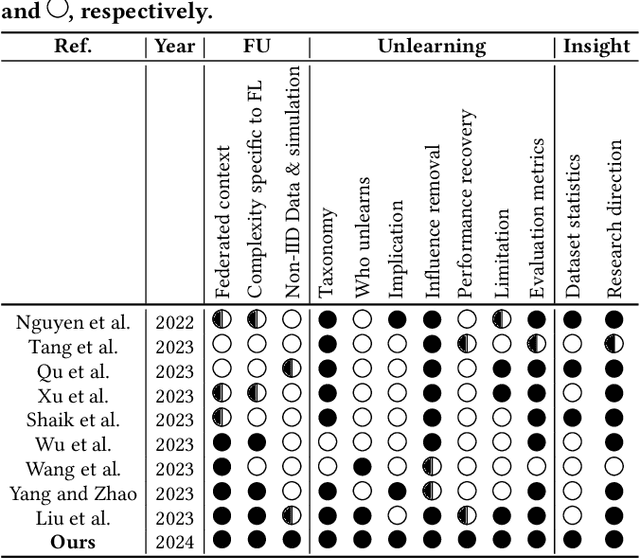
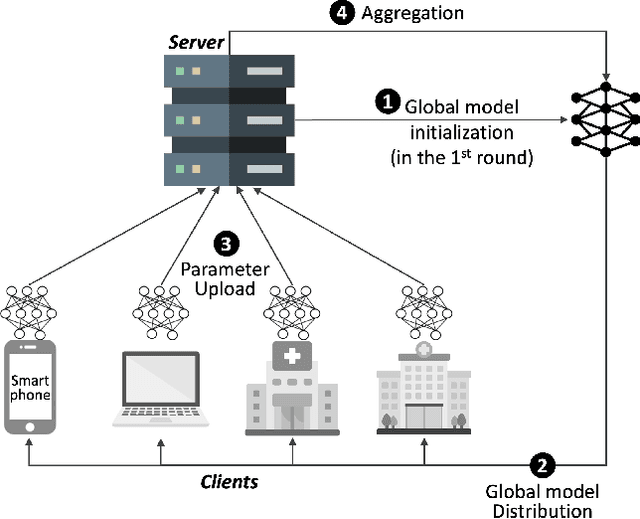

Federated learning (FL), introduced in 2017, facilitates collaborative learning between non-trusting parties with no need for the parties to explicitly share their data among themselves. This allows training models on user data while respecting privacy regulations such as GDPR and CPRA. However, emerging privacy requirements may mandate model owners to be able to \emph{forget} some learned data, e.g., when requested by data owners or law enforcement. This has given birth to an active field of research called \emph{machine unlearning}. In the context of FL, many techniques developed for unlearning in centralized settings are not trivially applicable! This is due to the unique differences between centralized and distributed learning, in particular, interactivity, stochasticity, heterogeneity, and limited accessibility in FL. In response, a recent line of work has focused on developing unlearning mechanisms tailored to FL. This SoK paper aims to take a deep look at the \emph{federated unlearning} literature, with the goal of identifying research trends and challenges in this emerging field. By carefully categorizing papers published on FL unlearning (since 2020), we aim to pinpoint the unique complexities of federated unlearning, highlighting limitations on directly applying centralized unlearning methods. We compare existing federated unlearning methods regarding influence removal and performance recovery, compare their threat models and assumptions, and discuss their implications and limitations. For instance, we analyze the experimental setup of FL unlearning studies from various perspectives, including data heterogeneity and its simulation, the datasets used for demonstration, and evaluation metrics. Our work aims to offer insights and suggestions for future research on federated unlearning.
Rapid Optimization for Jailbreaking LLMs via Subconscious Exploitation and Echopraxia
Feb 08, 2024Large Language Models (LLMs) have become prevalent across diverse sectors, transforming human life with their extraordinary reasoning and comprehension abilities. As they find increased use in sensitive tasks, safety concerns have gained widespread attention. Extensive efforts have been dedicated to aligning LLMs with human moral principles to ensure their safe deployment. Despite their potential, recent research indicates aligned LLMs are prone to specialized jailbreaking prompts that bypass safety measures to elicit violent and harmful content. The intrinsic discrete nature and substantial scale of contemporary LLMs pose significant challenges in automatically generating diverse, efficient, and potent jailbreaking prompts, representing a continuous obstacle. In this paper, we introduce RIPPLE (Rapid Optimization via Subconscious Exploitation and Echopraxia), a novel optimization-based method inspired by two psychological concepts: subconsciousness and echopraxia, which describe the processes of the mind that occur without conscious awareness and the involuntary mimicry of actions, respectively. Evaluations across 6 open-source LLMs and 4 commercial LLM APIs show RIPPLE achieves an average Attack Success Rate of 91.5\%, outperforming five current methods by up to 47.0\% with an 8x reduction in overhead. Furthermore, it displays significant transferability and stealth, successfully evading established detection mechanisms. The code of our work is available at \url{https://github.com/SolidShen/RIPPLE_official/tree/official}
DREAM: Debugging and Repairing AutoML Pipelines
Dec 31, 2023Deep Learning models have become an integrated component of modern software systems. In response to the challenge of model design, researchers proposed Automated Machine Learning (AutoML) systems, which automatically search for model architecture and hyperparameters for a given task. Like other software systems, existing AutoML systems suffer from bugs. We identify two common and severe bugs in AutoML, performance bug (i.e., searching for the desired model takes an unreasonably long time) and ineffective search bug (i.e., AutoML systems are not able to find an accurate enough model). After analyzing the workflow of AutoML, we observe that existing AutoML systems overlook potential opportunities in search space, search method, and search feedback, which results in performance and ineffective search bugs. Based on our analysis, we design and implement DREAM, an automatic debugging and repairing system for AutoML systems. It monitors the process of AutoML to collect detailed feedback and automatically repairs bugs by expanding search space and leveraging a feedback-driven search strategy. Our evaluation results show that DREAM can effectively and efficiently repair AutoML bugs.
Elijah: Eliminating Backdoors Injected in Diffusion Models via Distribution Shift
Nov 27, 2023Diffusion models (DM) have become state-of-the-art generative models because of their capability to generate high-quality images from noises without adversarial training. However, they are vulnerable to backdoor attacks as reported by recent studies. When a data input (e.g., some Gaussian noise) is stamped with a trigger (e.g., a white patch), the backdoored model always generates the target image (e.g., an improper photo). However, effective defense strategies to mitigate backdoors from DMs are underexplored. To bridge this gap, we propose the first backdoor detection and removal framework for DMs. We evaluate our framework Elijah on hundreds of DMs of 3 types including DDPM, NCSN and LDM, with 13 samplers against 3 existing backdoor attacks. Extensive experiments show that our approach can have close to 100% detection accuracy and reduce the backdoor effects to close to zero without significantly sacrificing the model utility.
How to Detect Unauthorized Data Usages in Text-to-image Diffusion Models
Jul 06, 2023



Recent text-to-image diffusion models have shown surprising performance in generating high-quality images. However, concerns have arisen regarding the unauthorized usage of data during the training process. One example is when a model trainer collects a set of images created by a particular artist and attempts to train a model capable of generating similar images without obtaining permission from the artist. To address this issue, it becomes crucial to detect unauthorized data usage. In this paper, we propose a method for detecting such unauthorized data usage by planting injected memorization into the text-to-image diffusion models trained on the protected dataset. Specifically, we modify the protected image dataset by adding unique contents on the images such as stealthy image wrapping functions that are imperceptible to human vision but can be captured and memorized by diffusion models. By analyzing whether the model has memorization for the injected content (i.e., whether the generated images are processed by the chosen post-processing function), we can detect models that had illegally utilized the unauthorized data. Our experiments conducted on Stable Diffusion and LoRA model demonstrate the effectiveness of the proposed method in detecting unauthorized data usages.
Alteration-free and Model-agnostic Origin Attribution of Generated Images
May 29, 2023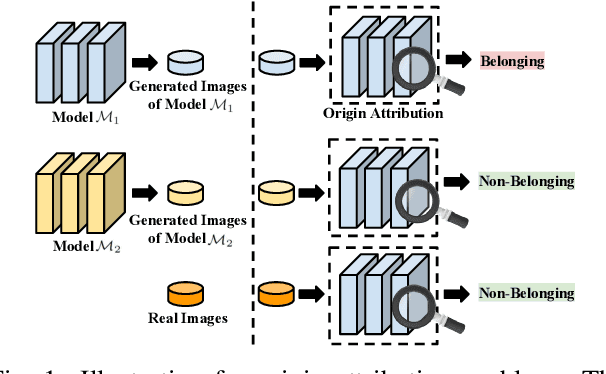


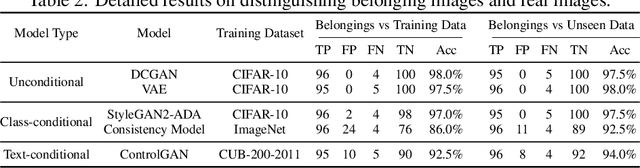
Recently, there has been a growing attention in image generation models. However, concerns have emerged regarding potential misuse and intellectual property (IP) infringement associated with these models. Therefore, it is necessary to analyze the origin of images by inferring if a specific image was generated by a particular model, i.e., origin attribution. Existing methods are limited in their applicability to specific types of generative models and require additional steps during training or generation. This restricts their use with pre-trained models that lack these specific operations and may compromise the quality of image generation. To overcome this problem, we first develop an alteration-free and model-agnostic origin attribution method via input reverse-engineering on image generation models, i.e., inverting the input of a particular model for a specific image. Given a particular model, we first analyze the differences in the hardness of reverse-engineering tasks for the generated images of the given model and other images. Based on our analysis, we propose a method that utilizes the reconstruction loss of reverse-engineering to infer the origin. Our proposed method effectively distinguishes between generated images from a specific generative model and other images, including those generated by different models and real images.
NOTABLE: Transferable Backdoor Attacks Against Prompt-based NLP Models
May 28, 2023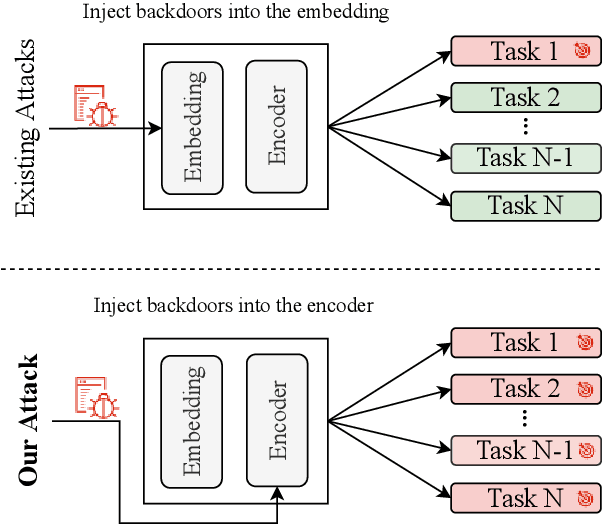
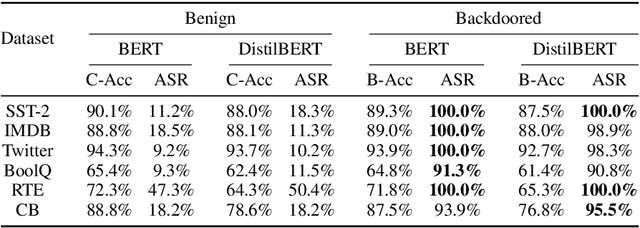


Prompt-based learning is vulnerable to backdoor attacks. Existing backdoor attacks against prompt-based models consider injecting backdoors into the entire embedding layers or word embedding vectors. Such attacks can be easily affected by retraining on downstream tasks and with different prompting strategies, limiting the transferability of backdoor attacks. In this work, we propose transferable backdoor attacks against prompt-based models, called NOTABLE, which is independent of downstream tasks and prompting strategies. Specifically, NOTABLE injects backdoors into the encoders of PLMs by utilizing an adaptive verbalizer to bind triggers to specific words (i.e., anchors). It activates the backdoor by pasting input with triggers to reach adversary-desired anchors, achieving independence from downstream tasks and prompting strategies. We conduct experiments on six NLP tasks, three popular models, and three prompting strategies. Empirical results show that NOTABLE achieves superior attack performance (i.e., attack success rate over 90% on all the datasets), and outperforms two state-of-the-art baselines. Evaluations on three defenses show the robustness of NOTABLE. Our code can be found at https://github.com/RU-System-Software-and-Security/Notable.
CILIATE: Towards Fairer Class-based Incremental Learning by Dataset and Training Refinement
Apr 09, 2023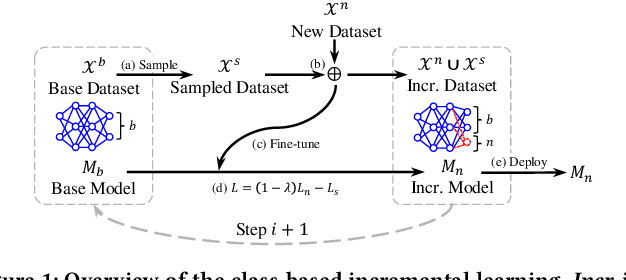
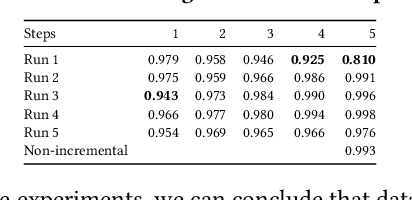

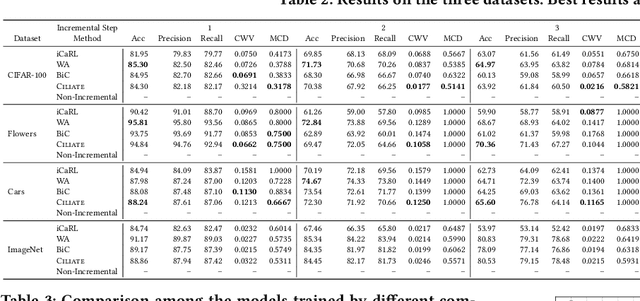
Due to the model aging problem, Deep Neural Networks (DNNs) need updates to adjust them to new data distributions. The common practice leverages incremental learning (IL), e.g., Class-based Incremental Learning (CIL) that updates output labels, to update the model with new data and a limited number of old data. This avoids heavyweight training (from scratch) using conventional methods and saves storage space by reducing the number of old data to store. But it also leads to poor performance in fairness. In this paper, we show that CIL suffers both dataset and algorithm bias problems, and existing solutions can only partially solve the problem. We propose a novel framework, CILIATE, that fixes both dataset and algorithm bias in CIL. It features a novel differential analysis guided dataset and training refinement process that identifies unique and important samples overlooked by existing CIL and enforces the model to learn from them. Through this process, CILIATE improves the fairness of CIL by 17.03%, 22.46%, and 31.79% compared to state-of-the-art methods, iCaRL, BiC, and WA, respectively, based on our evaluation on three popular datasets and widely used ResNet models.
UNICORN: A Unified Backdoor Trigger Inversion Framework
Apr 05, 2023
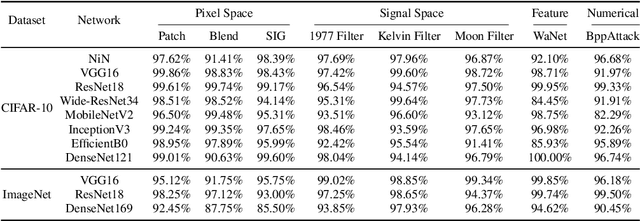

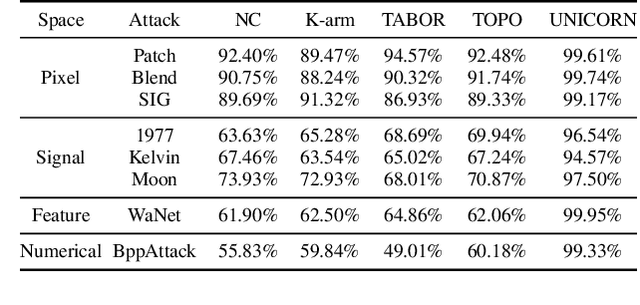
The backdoor attack, where the adversary uses inputs stamped with triggers (e.g., a patch) to activate pre-planted malicious behaviors, is a severe threat to Deep Neural Network (DNN) models. Trigger inversion is an effective way of identifying backdoor models and understanding embedded adversarial behaviors. A challenge of trigger inversion is that there are many ways of constructing the trigger. Existing methods cannot generalize to various types of triggers by making certain assumptions or attack-specific constraints. The fundamental reason is that existing work does not consider the trigger's design space in their formulation of the inversion problem. This work formally defines and analyzes the triggers injected in different spaces and the inversion problem. Then, it proposes a unified framework to invert backdoor triggers based on the formalization of triggers and the identified inner behaviors of backdoor models from our analysis. Our prototype UNICORN is general and effective in inverting backdoor triggers in DNNs. The code can be found at https://github.com/RU-System-Software-and-Security/UNICORN.