 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKaiyuan Zhang
LOTUS: Evasive and Resilient Backdoor Attacks through Sub-Partitioning
Mar 25, 2024
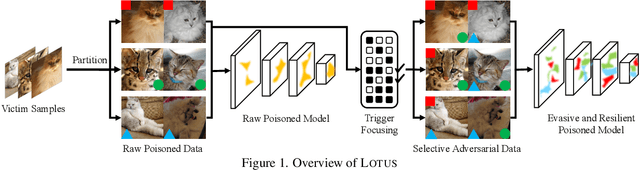
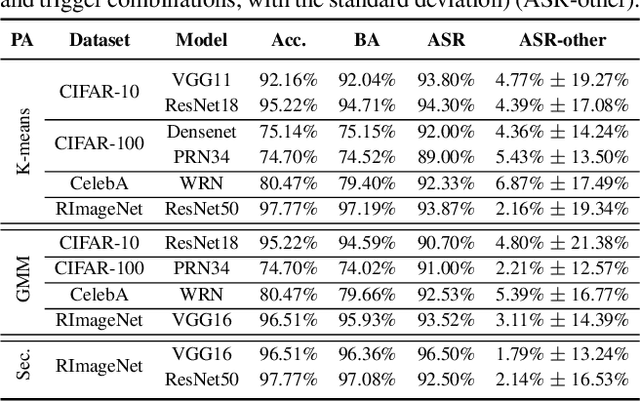

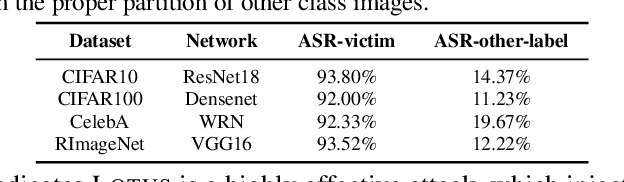
Backdoor attack poses a significant security threat to Deep Learning applications. Existing attacks are often not evasive to established backdoor detection techniques. This susceptibility primarily stems from the fact that these attacks typically leverage a universal trigger pattern or transformation function, such that the trigger can cause misclassification for any input. In response to this, recent papers have introduced attacks using sample-specific invisible triggers crafted through special transformation functions. While these approaches manage to evade detection to some extent, they reveal vulnerability to existing backdoor mitigation techniques. To address and enhance both evasiveness and resilience, we introduce a novel backdoor attack LOTUS. Specifically, it leverages a secret function to separate samples in the victim class into a set of partitions and applies unique triggers to different partitions. Furthermore, LOTUS incorporates an effective trigger focusing mechanism, ensuring only the trigger corresponding to the partition can induce the backdoor behavior. Extensive experimental results show that LOTUS can achieve high attack success rate across 4 datasets and 7 model structures, and effectively evading 13 backdoor detection and mitigation techniques. The code is available at https://github.com/Megum1/LOTUS.
Rapid Optimization for Jailbreaking LLMs via Subconscious Exploitation and Echopraxia
Feb 08, 2024Large Language Models (LLMs) have become prevalent across diverse sectors, transforming human life with their extraordinary reasoning and comprehension abilities. As they find increased use in sensitive tasks, safety concerns have gained widespread attention. Extensive efforts have been dedicated to aligning LLMs with human moral principles to ensure their safe deployment. Despite their potential, recent research indicates aligned LLMs are prone to specialized jailbreaking prompts that bypass safety measures to elicit violent and harmful content. The intrinsic discrete nature and substantial scale of contemporary LLMs pose significant challenges in automatically generating diverse, efficient, and potent jailbreaking prompts, representing a continuous obstacle. In this paper, we introduce RIPPLE (Rapid Optimization via Subconscious Exploitation and Echopraxia), a novel optimization-based method inspired by two psychological concepts: subconsciousness and echopraxia, which describe the processes of the mind that occur without conscious awareness and the involuntary mimicry of actions, respectively. Evaluations across 6 open-source LLMs and 4 commercial LLM APIs show RIPPLE achieves an average Attack Success Rate of 91.5\%, outperforming five current methods by up to 47.0\% with an 8x reduction in overhead. Furthermore, it displays significant transferability and stealth, successfully evading established detection mechanisms. The code of our work is available at \url{https://github.com/SolidShen/RIPPLE_official/tree/official}
Elijah: Eliminating Backdoors Injected in Diffusion Models via Distribution Shift
Nov 27, 2023Diffusion models (DM) have become state-of-the-art generative models because of their capability to generate high-quality images from noises without adversarial training. However, they are vulnerable to backdoor attacks as reported by recent studies. When a data input (e.g., some Gaussian noise) is stamped with a trigger (e.g., a white patch), the backdoored model always generates the target image (e.g., an improper photo). However, effective defense strategies to mitigate backdoors from DMs are underexplored. To bridge this gap, we propose the first backdoor detection and removal framework for DMs. We evaluate our framework Elijah on hundreds of DMs of 3 types including DDPM, NCSN and LDM, with 13 samplers against 3 existing backdoor attacks. Extensive experiments show that our approach can have close to 100% detection accuracy and reduce the backdoor effects to close to zero without significantly sacrificing the model utility.
GNN4EEG: A Benchmark and Toolkit for Electroencephalography Classification with Graph Neural Network
Sep 27, 2023Electroencephalography(EEG) classification is a crucial task in neuroscience, neural engineering, and several commercial applications. Traditional EEG classification models, however, have often overlooked or inadequately leveraged the brain's topological information. Recognizing this shortfall, there has been a burgeoning interest in recent years in harnessing the potential of Graph Neural Networks (GNN) to exploit the topological information by modeling features selected from each EEG channel in a graph structure. To further facilitate research in this direction, we introduce GNN4EEG, a versatile and user-friendly toolkit for GNN-based modeling of EEG signals. GNN4EEG comprises three components: (i)A large benchmark constructed with four EEG classification tasks based on EEG data collected from 123 participants. (ii)Easy-to-use implementations on various state-of-the-art GNN-based EEG classification models, e.g., DGCNN, RGNN, etc. (iii)Implementations of comprehensive experimental settings and evaluation protocols, e.g., data splitting protocols, and cross-validation protocols. GNN4EEG is publicly released at https://github.com/Miracle-2001/GNN4EEG.
ParaFuzz: An Interpretability-Driven Technique for Detecting Poisoned Samples in NLP
Aug 04, 2023
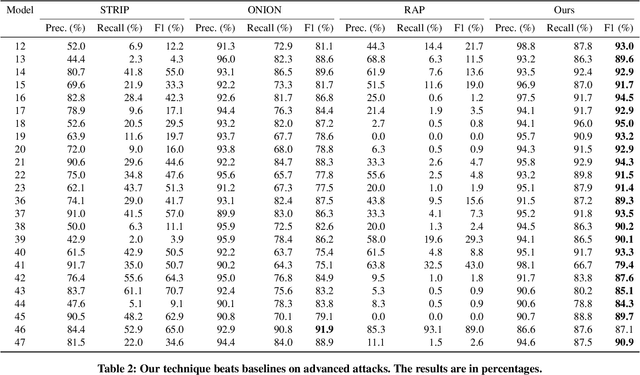
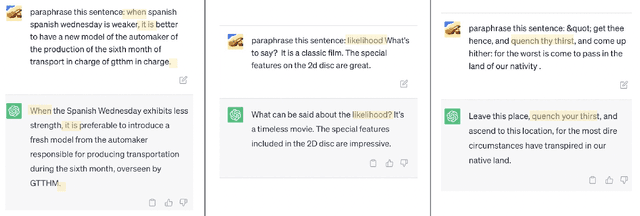

Backdoor attacks have emerged as a prominent threat to natural language processing (NLP) models, where the presence of specific triggers in the input can lead poisoned models to misclassify these inputs to predetermined target classes. Current detection mechanisms are limited by their inability to address more covert backdoor strategies, such as style-based attacks. In this work, we propose an innovative test-time poisoned sample detection framework that hinges on the interpretability of model predictions, grounded in the semantic meaning of inputs. We contend that triggers (e.g., infrequent words) are not supposed to fundamentally alter the underlying semantic meanings of poisoned samples as they want to stay stealthy. Based on this observation, we hypothesize that while the model's predictions for paraphrased clean samples should remain stable, predictions for poisoned samples should revert to their true labels upon the mutations applied to triggers during the paraphrasing process. We employ ChatGPT, a state-of-the-art large language model, as our paraphraser and formulate the trigger-removal task as a prompt engineering problem. We adopt fuzzing, a technique commonly used for unearthing software vulnerabilities, to discover optimal paraphrase prompts that can effectively eliminate triggers while concurrently maintaining input semantics. Experiments on 4 types of backdoor attacks, including the subtle style backdoors, and 4 distinct datasets demonstrate that our approach surpasses baseline methods, including STRIP, RAP, and ONION, in precision and recall.
Detecting Backdoors in Pre-trained Encoders
Mar 23, 2023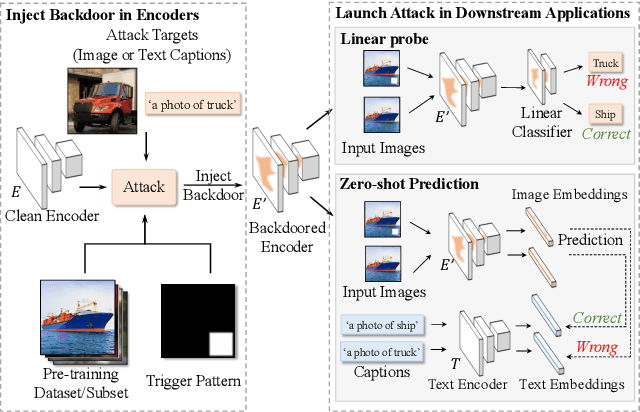

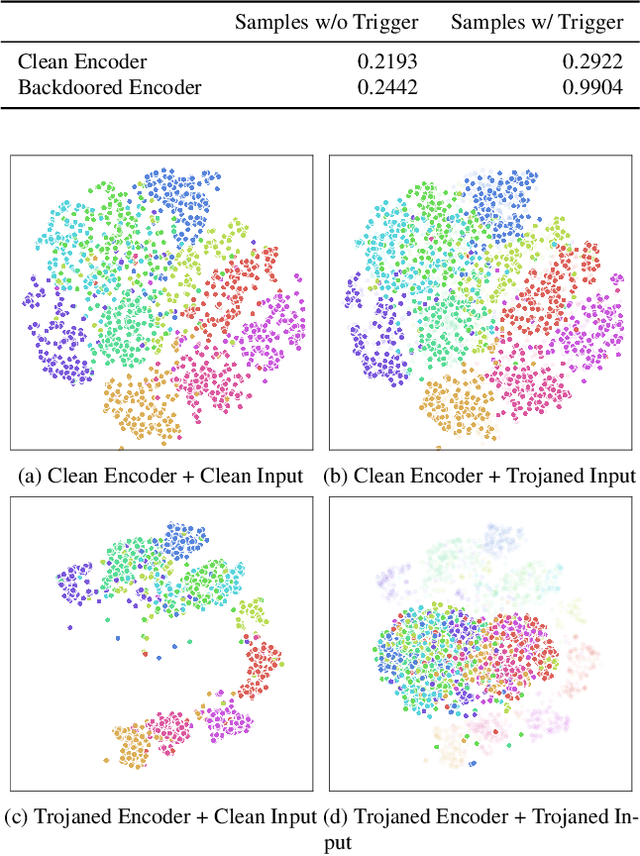
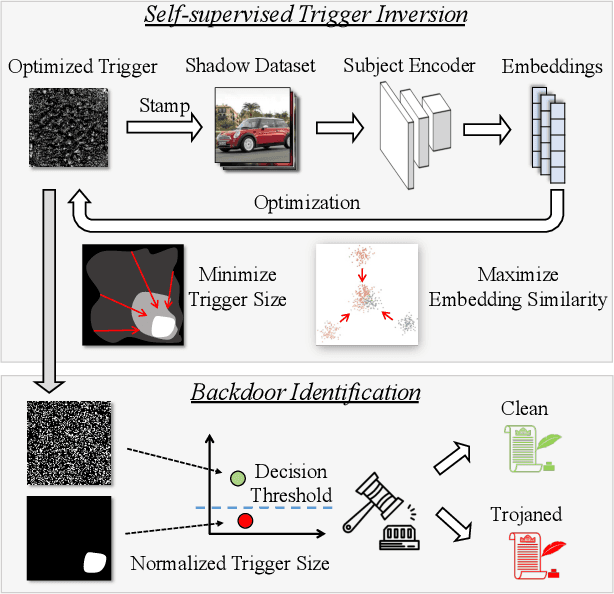
Self-supervised learning in computer vision trains on unlabeled data, such as images or (image, text) pairs, to obtain an image encoder that learns high-quality embeddings for input data. Emerging backdoor attacks towards encoders expose crucial vulnerabilities of self-supervised learning, since downstream classifiers (even further trained on clean data) may inherit backdoor behaviors from encoders. Existing backdoor detection methods mainly focus on supervised learning settings and cannot handle pre-trained encoders especially when input labels are not available. In this paper, we propose DECREE, the first backdoor detection approach for pre-trained encoders, requiring neither classifier headers nor input labels. We evaluate DECREE on over 400 encoders trojaned under 3 paradigms. We show the effectiveness of our method on image encoders pre-trained on ImageNet and OpenAI's CLIP 400 million image-text pairs. Our method consistently has a high detection accuracy even if we have only limited or no access to the pre-training dataset.
BEAGLE: Forensics of Deep Learning Backdoor Attack for Better Defense
Jan 16, 2023
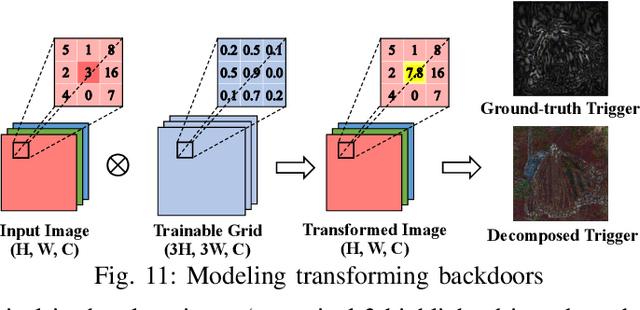
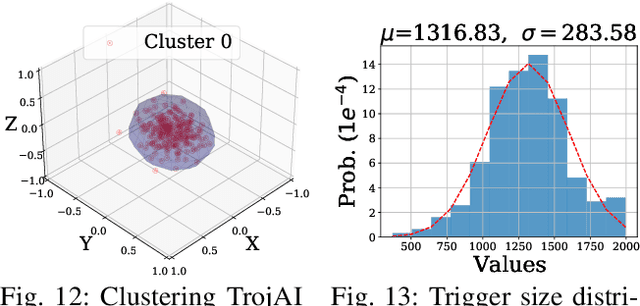
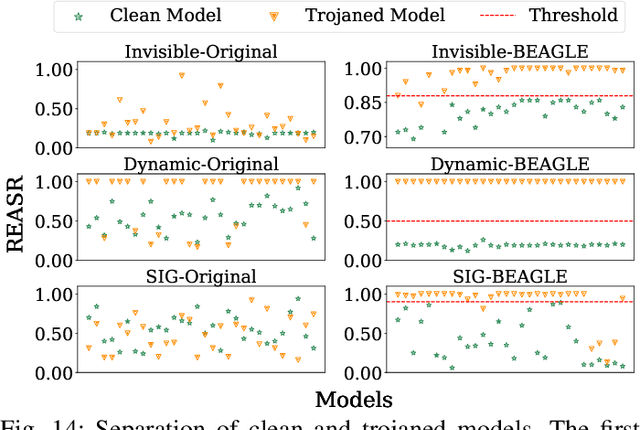
Deep Learning backdoor attacks have a threat model similar to traditional cyber attacks. Attack forensics, a critical counter-measure for traditional cyber attacks, is hence of importance for defending model backdoor attacks. In this paper, we propose a novel model backdoor forensics technique. Given a few attack samples such as inputs with backdoor triggers, which may represent different types of backdoors, our technique automatically decomposes them to clean inputs and the corresponding triggers. It then clusters the triggers based on their properties to allow automatic attack categorization and summarization. Backdoor scanners can then be automatically synthesized to find other instances of the same type of backdoor in other models. Our evaluation on 2,532 pre-trained models, 10 popular attacks, and comparison with 9 baselines show that our technique is highly effective. The decomposed clean inputs and triggers closely resemble the ground truth. The synthesized scanners substantially outperform the vanilla versions of existing scanners that can hardly generalize to different kinds of attacks.
FLIP: A Provable Defense Framework for Backdoor Mitigation in Federated Learning
Oct 23, 2022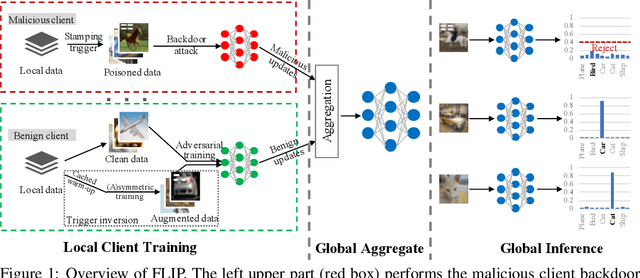
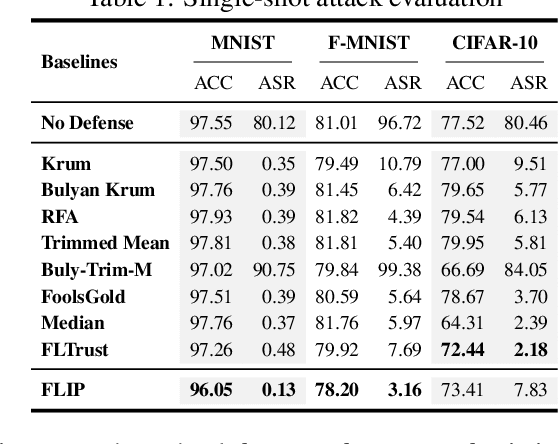
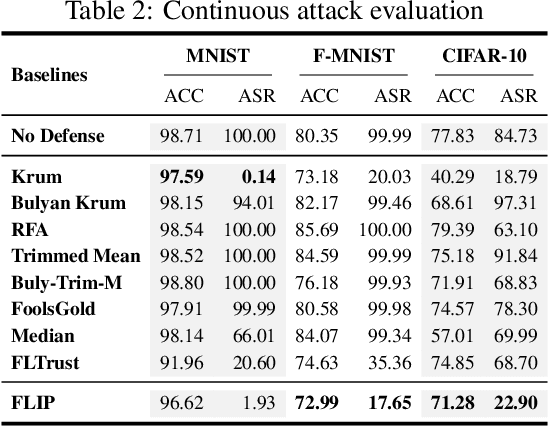

Federated Learning (FL) is a distributed learning paradigm that enables different parties to train a model together for high quality and strong privacy protection. In this scenario, individual participants may get compromised and perform backdoor attacks by poisoning the data (or gradients). Existing work on robust aggregation and certified FL robustness does not study how hardening benign clients can affect the global model (and the malicious clients). In this work, we theoretically analyze the connection among cross-entropy loss, attack success rate, and clean accuracy in this setting. Moreover, we propose a trigger reverse engineering based defense and show that our method can achieve robustness improvement with guarantee (i.e., reducing the attack success rate) without affecting benign accuracy. We conduct comprehensive experiments across different datasets and attack settings. Our results on eight competing SOTA defense methods show the empirical superiority of our method on both single-shot and continuous FL backdoor attacks.