 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKai-Chun Liu
A Non-Intrusive Neural Quality Assessment Model for Surface Electromyography Signals
Feb 08, 2024
In practical scenarios involving the measurement of surface electromyography (sEMG) in muscles, particularly those areas near the heart, one of the primary sources of contamination is the presence of electrocardiogram (ECG) signals. To assess the quality of real-world sEMG data more effectively, this study proposes QASE-net, a new non-intrusive model that predicts the SNR of sEMG signals. QASE-net combines CNN-BLSTM with attention mechanisms and follows an end-to-end training strategy. Our experimental framework utilizes real-world sEMG and ECG data from two open-access databases, the Non-Invasive Adaptive Prosthetics Database and the MIT-BIH Normal Sinus Rhythm Database, respectively. The experimental results demonstrate the superiority of QASE-net over the previous assessment model, exhibiting significantly reduced prediction errors and notably higher linear correlations with the ground truth. These findings show the potential of QASE-net to substantially enhance the reliability and precision of sEMG quality assessment in practical applications.
SDEMG: Score-based Diffusion Model for Surface Electromyographic Signal Denoising
Feb 06, 2024Surface electromyography (sEMG) recordings can be influenced by electrocardiogram (ECG) signals when the muscle being monitored is close to the heart. Several existing methods use signal-processing-based approaches, such as high-pass filter and template subtraction, while some derive mapping functions to restore clean sEMG signals from noisy sEMG (sEMG with ECG interference). Recently, the score-based diffusion model, a renowned generative model, has been introduced to generate high-quality and accurate samples with noisy input data. In this study, we proposed a novel approach, termed SDEMG, as a score-based diffusion model for sEMG signal denoising. To evaluate the proposed SDEMG approach, we conduct experiments to reduce noise in sEMG signals, employing data from an openly accessible source, the Non-Invasive Adaptive Prosthetics database, along with ECG signals from the MIT-BIH Normal Sinus Rhythm Database. The experiment result indicates that SDEMG outperformed comparative methods and produced high-quality sEMG samples. The source code of SDEMG the framework is available at: https://github.com/tonyliu0910/SDEMG
Deep Learning-based Fall Detection Algorithm Using Ensemble Model of Coarse-fine CNN and GRU Networks
Apr 13, 2023


Falls are the public health issue for the elderly all over the world since the fall-induced injuries are associated with a large amount of healthcare cost. Falls can cause serious injuries, even leading to death if the elderly suffers a "long-lie". Hence, a reliable fall detection (FD) system is required to provide an emergency alarm for first aid. Due to the advances in wearable device technology and artificial intelligence, some fall detection systems have been developed using machine learning and deep learning methods to analyze the signal collected from accelerometer and gyroscopes. In order to achieve better fall detection performance, an ensemble model that combines a coarse-fine convolutional neural network and gated recurrent unit is proposed in this study. The parallel structure design used in this model restores the different grains of spatial characteristics and capture temporal dependencies for feature representation. This study applies the FallAllD public dataset to validate the reliability of the proposed model, which achieves a recall, precision, and F-score of 92.54%, 96.13%, and 94.26%, respectively. The results demonstrate the reliability of the proposed ensemble model in discriminating falls from daily living activities and its superior performance compared to the state-of-the-art convolutional neural network long short-term memory (CNN-LSTM) for FD.
PreFallKD: Pre-Impact Fall Detection via CNN-ViT Knowledge Distillation
Mar 13, 2023


Fall accidents are critical issues in an aging and aged society. Recently, many researchers developed pre-impact fall detection systems using deep learning to support wearable-based fall protection systems for preventing severe injuries. However, most works only employed simple neural network models instead of complex models considering the usability in resource-constrained mobile devices and strict latency requirements. In this work, we propose a novel pre-impact fall detection via CNN-ViT knowledge distillation, namely PreFallKD, to strike a balance between detection performance and computational complexity. The proposed PreFallKD transfers the detection knowledge from the pre-trained teacher model (vision transformer) to the student model (lightweight convolutional neural networks). Additionally, we apply data augmentation techniques to tackle issues of data imbalance. We conduct the experiment on the KFall public dataset and compare PreFallKD with other state-of-the-art models. The experiment results show that PreFallKD could boost the student model during the testing phase and achieves reliable F1-score (92.66%) and lead time (551.3 ms).
ECG Artifact Removal from Single-Channel Surface EMG Using Fully Convolutional Networks
Oct 24, 2022



Electrocardiogram (ECG) artifact contamination often occurs in surface electromyography (sEMG) applications when the measured muscles are in proximity to the heart. Previous studies have developed and proposed various methods, such as high-pass filtering, template subtraction and so forth. However, these methods remain limited by the requirement of reference signals and distortion of original sEMG. This study proposed a novel denoising method to eliminate ECG artifacts from the single-channel sEMG signals using fully convolutional networks (FCN). The proposed method adopts a denoise autoencoder structure and powerful nonlinear mapping capability of neural networks for sEMG denoising. We compared the proposed approach with conventional approaches, including high-pass filters and template subtraction, on open datasets called the Non-Invasive Adaptive Prosthetics database and MIT-BIH normal sinus rhythm database. The experimental results demonstrate that the FCN outperforms conventional methods in sEMG reconstruction quality under a wide range of signal-to-noise ratio inputs.
EMGSE: Acoustic/EMG Fusion for Multimodal Speech Enhancement
Feb 14, 2022



Multimodal learning has been proven to be an effective method to improve speech enhancement (SE) performance, especially in challenging situations such as low signal-to-noise ratios, speech noise, or unseen noise types. In previous studies, several types of auxiliary data have been used to construct multimodal SE systems, such as lip images, electropalatography, or electromagnetic midsagittal articulography. In this paper, we propose a novel EMGSE framework for multimodal SE, which integrates audio and facial electromyography (EMG) signals. Facial EMG is a biological signal containing articulatory movement information, which can be measured in a non-invasive way. Experimental results show that the proposed EMGSE system can achieve better performance than the audio-only SE system. The benefits of fusing EMG signals with acoustic signals for SE are notable under challenging circumstances. Furthermore, this study reveals that cheek EMG is sufficient for SE.
Instrumented shoulder functional assessment using inertial measurement units for frozen shoulder
Nov 26, 2021



Frozen shoulder (FS) is a shoulder condition that leads to pain and loss of shoulder range of motion. FS patients have difficulties in independently performing daily activities. Inertial measurement units (IMUs) have been developed to objectively measure upper limb range of motion (ROM) and shoulder function. In this work, we propose an IMU-based shoulder functional task assessment with kinematic parameters (e.g., smoothness, power, speed, and duration) in FS patients and analyze the functional performance on complete shoulder tasks and subtasks. Twenty FS patients and twenty healthy subjects were recruited in this study. Five shoulder functional tasks are performed by participants, such as washing hair (WH), washing upper back (WUB), washing lower back (WLB), placing an object on a high shelf (POH), and removing an object from back pocket (ROP). The results demonstrate that the used smoothness features can reflect the differences of movement fluency between FS patients and healthy controls (p < 0.05 and effect size > 0.8). Moreover, features of subtasks provided subtle information related to clinical conditions that have not been revealed in features of a complete task, especially the defined subtask 1 and 2 of each task.
Domain-adaptive Fall Detection Using Deep Adversarial Training
Dec 20, 2020



Fall detection (FD) systems are important assistive technologies for healthcare that can detect emergency fall events and alert caregivers. However, it is not easy to obtain large-scale annotated fall events with various specifications of sensors or sensor positions, during the implementation of accurate FD systems. Moreover, the knowledge obtained through machine learning has been restricted to tasks in the same domain. The mismatch between different domains might hinder the performance of FD systems. Cross-domain knowledge transfer is very beneficial for machine-learning based FD systems to train a reliable FD model with well-labeled data in new environments. In this study, we propose domain-adaptive fall detection (DAFD) using deep adversarial training (DAT) to tackle cross-domain problems, such as cross-position and cross-configuration. The proposed DAFD can transfer knowledge from the source domain to the target domain by minimizing the domain discrepancy to avoid mismatch problems. The experimental results show that the average F1score improvement when using DAFD ranges from 1.5% to 7% in the cross-position scenario, and from 3.5% to 12% in the cross-configuration scenario, compared to using the conventional FD model without domain adaptation training. The results demonstrate that the proposed DAFD successfully helps to deal with cross-domain problems and to achieve better detection performance.
Deep Learning Based Signal Enhancement of Low-Resolution Accelerometer for Fall Detection Systems
Dec 07, 2020



In the last two decades, fall detection (FD) systems have been developed as a popular assistive technology. Such systems automatically detect critical fall events and immediately alert medical professionals or caregivers. To support long-term FD services, various power-saving strategies have been implemented. Among them, a reduced sampling rate is a common approach for an energy-efficient system in the real-world. However, the performance of FD systems is diminished owing to low-resolution (LR) accelerometer signals. To improve the detection accuracy with LR accelerometer signals, several technical challenges must be considered, including misalignment, mismatch of effective features, and the degradation effects. In this work, a deep-learning-based accelerometer signal enhancement (ASE) model is proposed to improve the detection performance of LR-FD systems. This proposed model reconstructs high-resolution (HR) signals from the LR signals by learning the relationship between the LR and HR signals. The results show that the FD system using support vector machine and the proposed ASE model at an extremely low sampling rate (sampling rate < 2 Hz) achieved 97.34% and 90.52% accuracies in the SisFall and FallAllD datasets, respectively, while those without ASE models only achieved 95.92% and 87.47% accuracies in the SisFall and FallAllD datasets, respectively. This study demonstrates that the ASE model helps the FD systems tackle the technical challenges of LR signals and achieve better detection performance.
CITISEN: A Deep Learning-Based Speech Signal-Processing Mobile Application
Aug 21, 2020
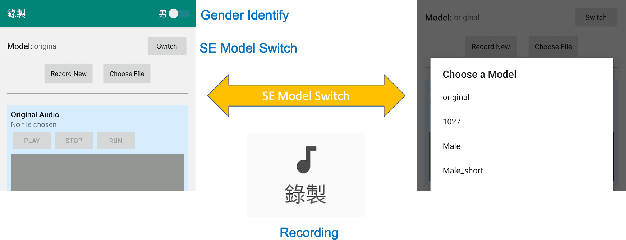
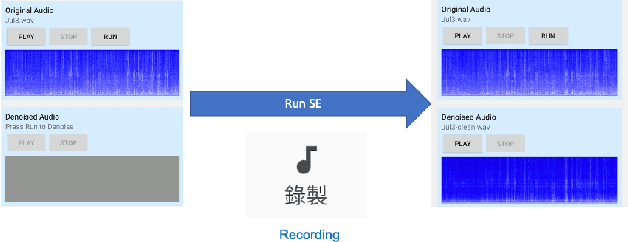

In this paper, we present a deep learning-based speech signal-processing mobile application, CITISEN, which can perform three functions: speech enhancement (SE), acoustic scene conversion (ASC), and model adaptation (MA). For SE, CITISEN can effectively reduce noise components from speech signals and accordingly enhance their clarity and intelligibility. For ASC, CITISEN can convert the current background sound to a different background sound. Finally, for MA, CITISEN can effectively adapt an SE model, with a few audio files, when it encounters unknown speakers or noise types; the adapted SE model is used to enhance the upcoming noisy utterances. Experimental results confirmed the effectiveness of CITISEN in performing these three functions via objective evaluation and subjective listening tests. The promising results reveal that the developed CITISEN mobile application can potentially be used as a front-end processor for various speech-related services such as voice communication, assistive hearing devices, and virtual reality headsets.