 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXugang Lu
A Non-Intrusive Neural Quality Assessment Model for Surface Electromyography Signals
Feb 08, 2024
In practical scenarios involving the measurement of surface electromyography (sEMG) in muscles, particularly those areas near the heart, one of the primary sources of contamination is the presence of electrocardiogram (ECG) signals. To assess the quality of real-world sEMG data more effectively, this study proposes QASE-net, a new non-intrusive model that predicts the SNR of sEMG signals. QASE-net combines CNN-BLSTM with attention mechanisms and follows an end-to-end training strategy. Our experimental framework utilizes real-world sEMG and ECG data from two open-access databases, the Non-Invasive Adaptive Prosthetics Database and the MIT-BIH Normal Sinus Rhythm Database, respectively. The experimental results demonstrate the superiority of QASE-net over the previous assessment model, exhibiting significantly reduced prediction errors and notably higher linear correlations with the ground truth. These findings show the potential of QASE-net to substantially enhance the reliability and precision of sEMG quality assessment in practical applications.
Multi-Level Knowledge Distillation for Speech Emotion Recognition in Noisy Conditions
Dec 21, 2023Speech emotion recognition (SER) performance deteriorates significantly in the presence of noise, making it challenging to achieve competitive performance in noisy conditions. To this end, we propose a multi-level knowledge distillation (MLKD) method, which aims to transfer the knowledge from a teacher model trained on clean speech to a simpler student model trained on noisy speech. Specifically, we use clean speech features extracted by the wav2vec-2.0 as the learning goal and train the distil wav2vec-2.0 to approximate the feature extraction ability of the original wav2vec-2.0 under noisy conditions. Furthermore, we leverage the multi-level knowledge of the original wav2vec-2.0 to supervise the single-level output of the distil wav2vec-2.0. We evaluate the effectiveness of our proposed method by conducting extensive experiments using five types of noise-contaminated speech on the IEMOCAP dataset, which show promising results compared to state-of-the-art models.
Speaker Mask Transformer for Multi-talker Overlapped Speech Recognition
Dec 18, 2023Multi-talker overlapped speech recognition remains a significant challenge, requiring not only speech recognition but also speaker diarization tasks to be addressed. In this paper, to better address these tasks, we first introduce speaker labels into an autoregressive transformer-based speech recognition model to support multi-speaker overlapped speech recognition. Then, to improve speaker diarization, we propose a novel speaker mask branch to detection the speech segments of individual speakers. With the proposed model, we can perform both speech recognition and speaker diarization tasks simultaneously using a single model. Experimental results on the LibriSpeech-based overlapped dataset demonstrate the effectiveness of the proposed method in both speech recognition and speaker diarization tasks, particularly enhancing the accuracy of speaker diarization in relatively complex multi-talker scenarios.
Neural domain alignment for spoken language recognition based on optimal transport
Oct 20, 2023Domain shift poses a significant challenge in cross-domain spoken language recognition (SLR) by reducing its effectiveness. Unsupervised domain adaptation (UDA) algorithms have been explored to address domain shifts in SLR without relying on class labels in the target domain. One successful UDA approach focuses on learning domain-invariant representations to align feature distributions between domains. However, disregarding the class structure during the learning process of domain-invariant representations can result in over-alignment, negatively impacting the classification task. To overcome this limitation, we propose an optimal transport (OT)-based UDA algorithm for a cross-domain SLR, leveraging the distribution geometry structure-aware property of OT. An OT-based discrepancy measure on a joint distribution over feature and label information is considered during domain alignment in OT-based UDA. Our previous study discovered that completely aligning the distributions between the source and target domains can introduce a negative transfer, where classes or irrelevant classes from the source domain map to a different class in the target domain during distribution alignment. This negative transfer degrades the performance of the adaptive model. To mitigate this issue, we introduce coupling-weighted partial optimal transport (POT) within our UDA framework for SLR, where soft weighting on the OT coupling based on transport cost is adaptively set during domain alignment. A cross-domain SLR task was used in the experiments to evaluate the proposed UDA. The results demonstrated that our proposed UDA algorithm significantly improved the performance over existing UDA algorithms in a cross-channel SLR task.
Hierarchical Cross-Modality Knowledge Transfer with Sinkhorn Attention for CTC-based ASR
Sep 28, 2023Due to the modality discrepancy between textual and acoustic modeling, efficiently transferring linguistic knowledge from a pretrained language model (PLM) to acoustic encoding for automatic speech recognition (ASR) still remains a challenging task. In this study, we propose a cross-modality knowledge transfer (CMKT) learning framework in a temporal connectionist temporal classification (CTC) based ASR system where hierarchical acoustic alignments with the linguistic representation are applied. Additionally, we propose the use of Sinkhorn attention in cross-modality alignment process, where the transformer attention is a special case of this Sinkhorn attention process. The CMKT learning is supposed to compel the acoustic encoder to encode rich linguistic knowledge for ASR. On the AISHELL-1 dataset, with CTC greedy decoding for inference (without using any language model), we achieved state-of-the-art performance with 3.64% and 3.94% character error rates (CERs) for the development and test sets, which corresponding to relative improvements of 34.18% and 34.88% compared to the baseline CTC-ASR system, respectively.
Cross-modal Alignment with Optimal Transport for CTC-based ASR
Sep 24, 2023Temporal connectionist temporal classification (CTC)-based automatic speech recognition (ASR) is one of the most successful end to end (E2E) ASR frameworks. However, due to the token independence assumption in decoding, an external language model (LM) is required which destroys its fast parallel decoding property. Several studies have been proposed to transfer linguistic knowledge from a pretrained LM (PLM) to the CTC based ASR. Since the PLM is built from text while the acoustic model is trained with speech, a cross-modal alignment is required in order to transfer the context dependent linguistic knowledge from the PLM to acoustic encoding. In this study, we propose a novel cross-modal alignment algorithm based on optimal transport (OT). In the alignment process, a transport coupling matrix is obtained using OT, which is then utilized to transform a latent acoustic representation for matching the context-dependent linguistic features encoded by the PLM. Based on the alignment, the latent acoustic feature is forced to encode context dependent linguistic information. We integrate this latent acoustic feature to build conformer encoder-based CTC ASR system. On the AISHELL-1 data corpus, our system achieved 3.96% and 4.27% character error rate (CER) for dev and test sets, respectively, which corresponds to relative improvements of 28.39% and 29.42% compared to the baseline conformer CTC ASR system without cross-modal knowledge transfer.
Pronunciation-aware unique character encoding for RNN Transducer-based Mandarin speech recognition
Jul 29, 2022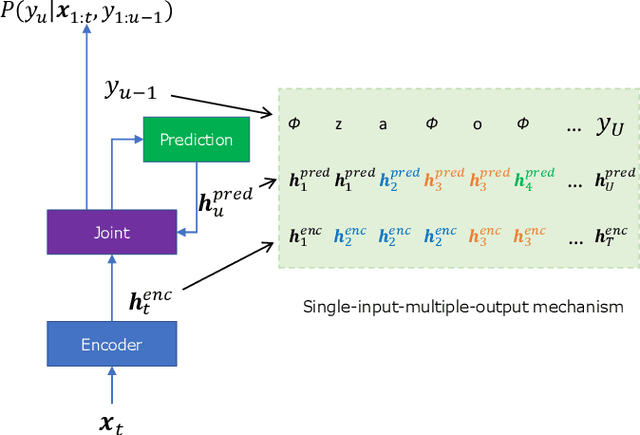
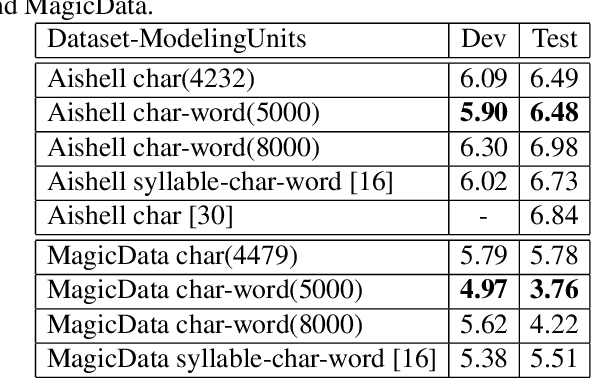

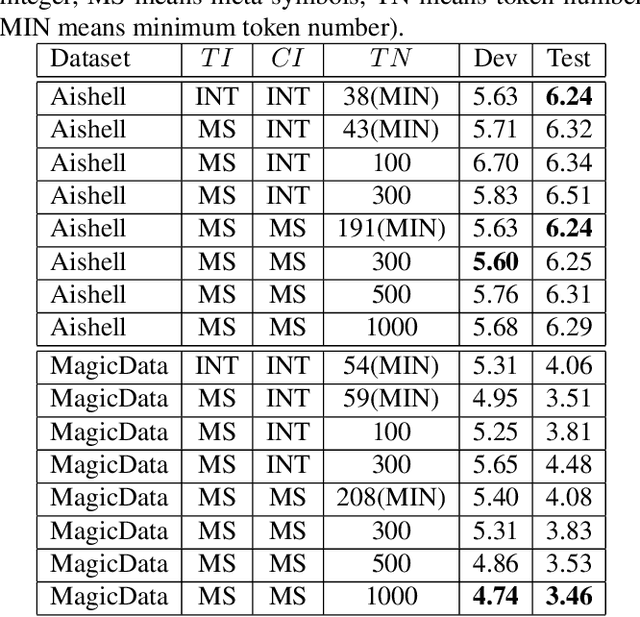
For Mandarin end-to-end (E2E) automatic speech recognition (ASR) tasks, compared to character-based modeling units, pronunciation-based modeling units could improve the sharing of modeling units in model training but meet homophone problems. In this study, we propose to use a novel pronunciation-aware unique character encoding for building E2E RNN-T-based Mandarin ASR systems. The proposed encoding is a combination of pronunciation-base syllable and character index (CI). By introducing the CI, the RNN-T model can overcome the homophone problem while utilizing the pronunciation information for extracting modeling units. With the proposed encoding, the model outputs can be converted into the final recognition result through a one-to-one mapping. We conducted experiments on Aishell and MagicData datasets, and the experimental results showed the effectiveness of the proposed method.
Transducer-based language embedding for spoken language identification
Apr 08, 2022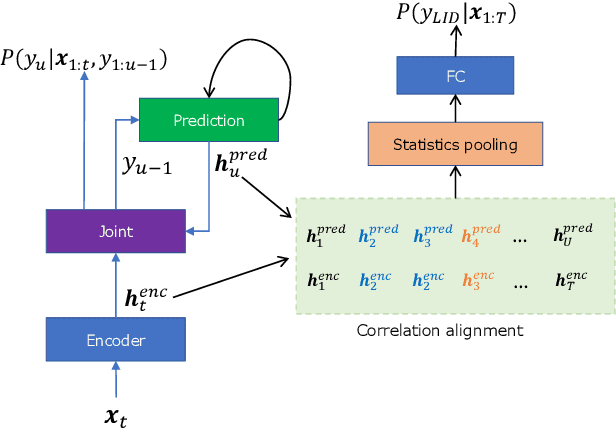
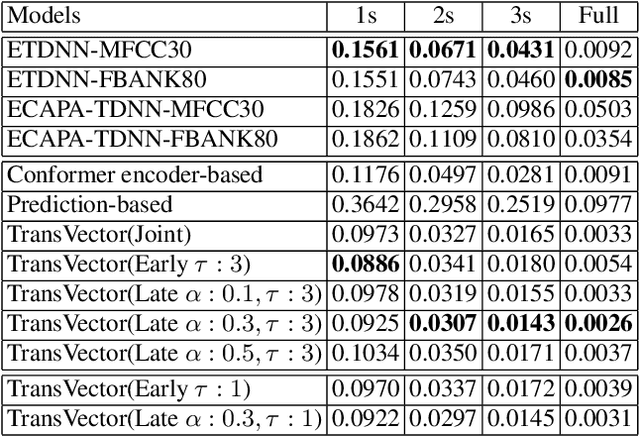
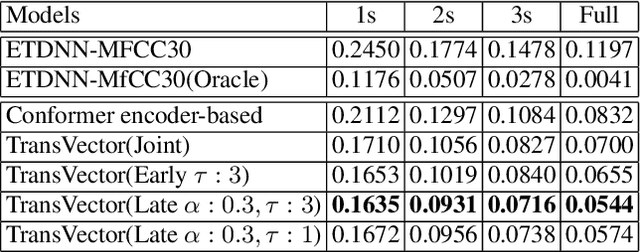
The acoustic and linguistic features are important cues for the spoken language identification (LID) task. Recent advanced LID systems mainly use acoustic features that lack the usage of explicit linguistic feature encoding. In this paper, we propose a novel transducer-based language embedding approach for LID tasks by integrating an RNN transducer model into a language embedding framework. Benefiting from the advantages of the RNN transducer's linguistic representation capability, the proposed method can exploit both phonetically-aware acoustic features and explicit linguistic features for LID tasks. Experiments were carried out on the large-scale multilingual LibriSpeech and VoxLingua107 datasets. Experimental results showed the proposed method significantly improves the performance on LID tasks with 12% to 59% and 16% to 24% relative improvement on in-domain and cross-domain datasets, respectively.
Perceptual Contrast Stretching on Target Feature for Speech Enhancement
Apr 01, 2022
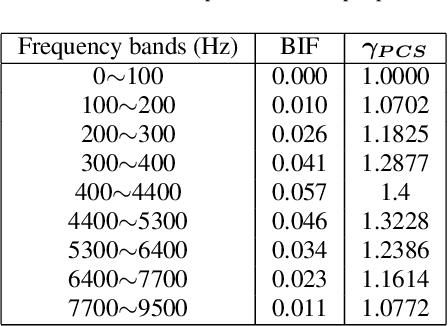
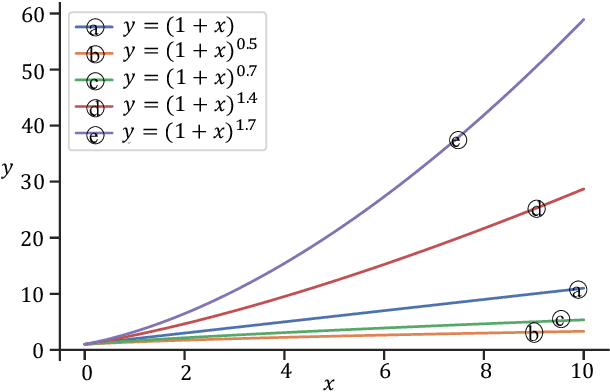
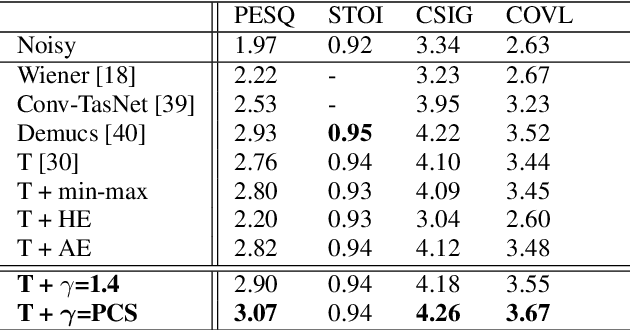
Speech enhancement (SE) performance has improved considerably since the use of deep learning (DL) models as a base function. In this study, we propose a perceptual contrast stretching (PCS) approach to further improve SE performance. PCS is derived based on the critical band importance function and applied to modify the targets of the SE model. Specifically, PCS stretches the contract of target features according to perceptual importance, thereby improving the overall SE performance. Compared to post-processing based implementations, incorporating PCS into the training phase preserves performance and reduces online computation. It is also worth noting that PCS can be suitably combined with different SE model architectures and training criteria. Meanwhile, PCS does not affect the causality or convergence of the SE model training. Experimental results on the VoiceBank-DEMAND dataset showed that the proposed method can achieve state-of-the-art performance on both causal (PESQ=3.07) and non-causal (PESQ=3.35) SE tasks.
Partial Coupling of Optimal Transport for Spoken Language Identification
Mar 31, 2022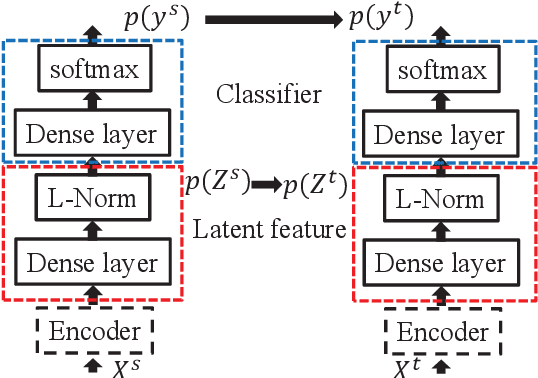
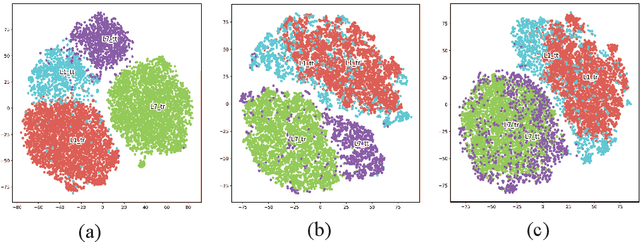
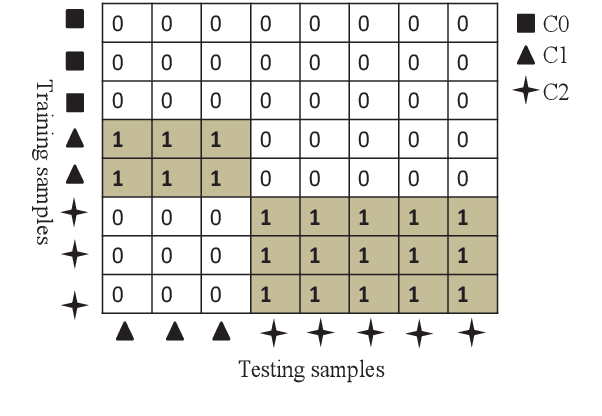
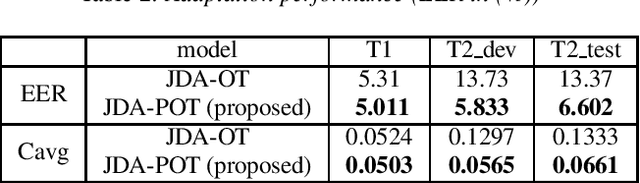
In order to reduce domain discrepancy to improve the performance of cross-domain spoken language identification (SLID) system, as an unsupervised domain adaptation (UDA) method, we have proposed a joint distribution alignment (JDA) model based on optimal transport (OT). A discrepancy measurement based on OT was adopted for JDA between training and test data sets. In our previous study, it was supposed that the training and test sets share the same label space. However, in real applications, the label space of the test set is only a subset of that of the training set. Fully matching training and test domains for distribution alignment may introduce negative domain transfer. In this paper, we propose an JDA model based on partial optimal transport (POT), i.e., only partial couplings of OT are allowed during JDA. Moreover, since the label of test data is unknown, in the POT, a soft weighting on the coupling based on transport cost is adaptively set during domain alignment. Experiments were carried out on a cross-domain SLID task to evaluate the proposed UDA. Results showed that our proposed UDA significantly improved the performance due to the consideration of the partial couplings in OT.