 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRong Chao
An Investigation of Incorporating Mamba for Speech Enhancement
May 10, 2024
This work aims to study a scalable state-space model (SSM), Mamba, for the speech enhancement (SE) task. We exploit a Mamba-based regression model to characterize speech signals and build an SE system upon Mamba, termed SEMamba. We explore the properties of Mamba by integrating it as the core model in both basic and advanced SE systems, along with utilizing signal-level distances as well as metric-oriented loss functions. SEMamba demonstrates promising results and attains a PESQ score of 3.55 on the VoiceBank-DEMAND dataset. When combined with the perceptual contrast stretching technique, the proposed SEMamba yields a new state-of-the-art PESQ score of 3.69.
ElectrodeNet -- A Deep Learning Based Sound Coding Strategy for Cochlear Implants
May 26, 2023



ElectrodeNet, a deep learning based sound coding strategy for the cochlear implant (CI), is proposed to emulate the advanced combination encoder (ACE) strategy by replacing the conventional envelope detection using various artificial neural networks. The extended ElectrodeNet-CS strategy further incorporates the channel selection (CS). Network models of deep neural network (DNN), convolutional neural network (CNN), and long short-term memory (LSTM) were trained using the Fast Fourier Transformed bins and channel envelopes obtained from the processing of clean speech by the ACE strategy. Objective speech understanding using short-time objective intelligibility (STOI) and normalized covariance metric (NCM) was estimated for ElectrodeNet using CI simulations. Sentence recognition tests for vocoded Mandarin speech were conducted with normal-hearing listeners. DNN, CNN, and LSTM based ElectrodeNets exhibited strong correlations to ACE in objective and subjective scores using mean squared error (MSE), linear correlation coefficient (LCC) and Spearman's rank correlation coefficient (SRCC). The ElectrodeNet-CS strategy was capable of producing N-of-M compatible electrode patterns using a modified DNN network to embed maxima selection, and to perform in similar or even slightly higher average in STOI and sentence recognition compared to ACE. The methods and findings demonstrated the feasibility and potential of using deep learning in CI coding strategy.
Perceptual Contrast Stretching on Target Feature for Speech Enhancement
Apr 01, 2022
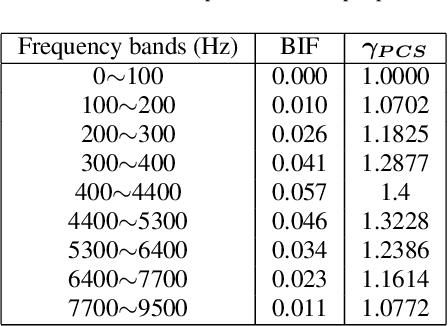
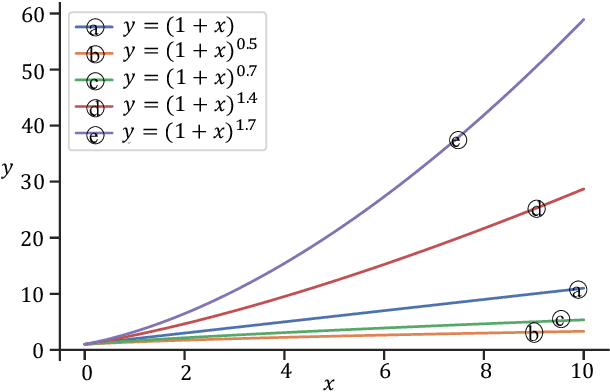
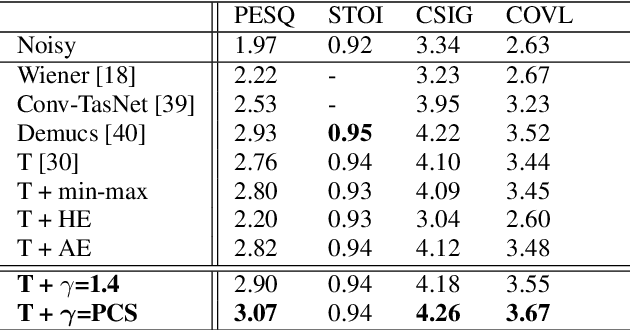
Speech enhancement (SE) performance has improved considerably since the use of deep learning (DL) models as a base function. In this study, we propose a perceptual contrast stretching (PCS) approach to further improve SE performance. PCS is derived based on the critical band importance function and applied to modify the targets of the SE model. Specifically, PCS stretches the contract of target features according to perceptual importance, thereby improving the overall SE performance. Compared to post-processing based implementations, incorporating PCS into the training phase preserves performance and reduces online computation. It is also worth noting that PCS can be suitably combined with different SE model architectures and training criteria. Meanwhile, PCS does not affect the causality or convergence of the SE model training. Experimental results on the VoiceBank-DEMAND dataset showed that the proposed method can achieve state-of-the-art performance on both causal (PESQ=3.07) and non-causal (PESQ=3.35) SE tasks.