 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKaizhi Zheng
MiniGPT-5: Interleaved Vision-and-Language Generation via Generative Vokens
Oct 05, 2023
Large Language Models (LLMs) have garnered significant attention for their advancements in natural language processing, demonstrating unparalleled prowess in text comprehension and generation. Yet, the simultaneous generation of images with coherent textual narratives remains an evolving frontier. In response, we introduce an innovative interleaved vision-and-language generation technique anchored by the concept of "generative vokens," acting as the bridge for harmonized image-text outputs. Our approach is characterized by a distinctive two-staged training strategy focusing on description-free multimodal generation, where the training requires no comprehensive descriptions of images. To bolster model integrity, classifier-free guidance is incorporated, enhancing the effectiveness of vokens on image generation. Our model, MiniGPT-5, exhibits substantial improvement over the baseline Divter model on the MMDialog dataset and consistently delivers superior or comparable multimodal outputs in human evaluations on the VIST dataset, highlighting its efficacy across diverse benchmarks.
R2H: Building Multimodal Navigation Helpers that Respond to Help
May 23, 2023



The ability to assist humans during a navigation task in a supportive role is crucial for intelligent agents. Such agents, equipped with environment knowledge and conversational abilities, can guide individuals through unfamiliar terrains by generating natural language responses to their inquiries, grounded in the visual information of their surroundings. However, these multimodal conversational navigation helpers are still underdeveloped. This paper proposes a new benchmark, Respond to Help (R2H), to build multimodal navigation helpers that can respond to help, based on existing dialog-based embodied datasets. R2H mainly includes two tasks: (1) Respond to Dialog History (RDH), which assesses the helper agent's ability to generate informative responses based on a given dialog history, and (2) Respond during Interaction (RdI), which evaluates the helper agent's ability to maintain effective and consistent cooperation with a task performer agent during navigation in real-time. Furthermore, we propose a novel task-oriented multimodal response generation model that can see and respond, named SeeRee, as the navigation helper to guide the task performer in embodied tasks. Through both automatic and human evaluations, we show that SeeRee produces more effective and informative responses than baseline methods in assisting the task performer with different navigation tasks. Project website: https://sites.google.com/view/respond2help/home.
ESC: Exploration with Soft Commonsense Constraints for Zero-shot Object Navigation
Jan 30, 2023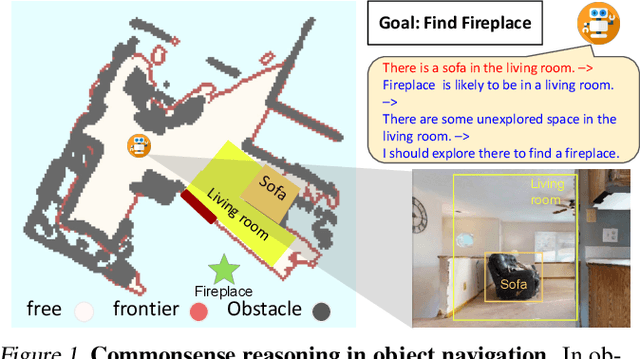
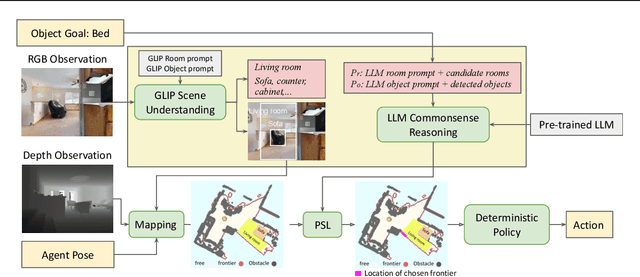
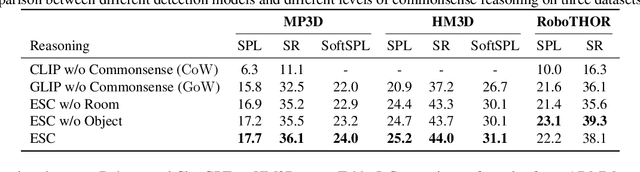
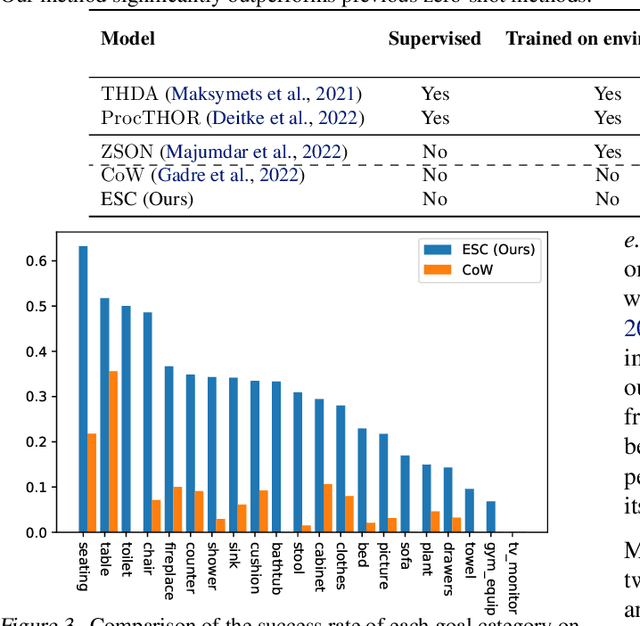
The ability to accurately locate and navigate to a specific object is a crucial capability for embodied agents that operate in the real world and interact with objects to complete tasks. Such object navigation tasks usually require large-scale training in visual environments with labeled objects, which generalizes poorly to novel objects in unknown environments. In this work, we present a novel zero-shot object navigation method, Exploration with Soft Commonsense constraints (ESC), that transfers commonsense knowledge in pre-trained models to open-world object navigation without any navigation experience nor any other training on the visual environments. First, ESC leverages a pre-trained vision and language model for open-world prompt-based grounding and a pre-trained commonsense language model for room and object reasoning. Then ESC converts commonsense knowledge into navigation actions by modeling it as soft logic predicates for efficient exploration. Extensive experiments on MP3D, HM3D, and RoboTHOR benchmarks show that our ESC method improves significantly over baselines, and achieves new state-of-the-art results for zero-shot object navigation (e.g., 225\% relative Success Rate improvement than CoW on MP3D).
JARVIS: A Neuro-Symbolic Commonsense Reasoning Framework for Conversational Embodied Agents
Aug 30, 2022

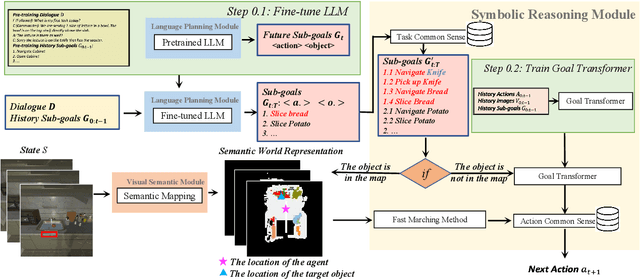

Building a conversational embodied agent to execute real-life tasks has been a long-standing yet quite challenging research goal, as it requires effective human-agent communication, multi-modal understanding, long-range sequential decision making, etc. Traditional symbolic methods have scaling and generalization issues, while end-to-end deep learning models suffer from data scarcity and high task complexity, and are often hard to explain. To benefit from both worlds, we propose a Neuro-Symbolic Commonsense Reasoning (JARVIS) framework for modular, generalizable, and interpretable conversational embodied agents. First, it acquires symbolic representations by prompting large language models (LLMs) for language understanding and sub-goal planning, and by constructing semantic maps from visual observations. Then the symbolic module reasons for sub-goal planning and action generation based on task- and action-level common sense. Extensive experiments on the TEACh dataset validate the efficacy and efficiency of our JARVIS framework, which achieves state-of-the-art (SOTA) results on all three dialog-based embodied tasks, including Execution from Dialog History (EDH), Trajectory from Dialog (TfD), and Two-Agent Task Completion (TATC) (e.g., our method boosts the unseen Success Rate on EDH from 6.1\% to 15.8\%). Moreover, we systematically analyze the essential factors that affect the task performance and also demonstrate the superiority of our method in few-shot settings. Our JARVIS model ranks first in the Alexa Prize SimBot Public Benchmark Challenge.
VLMbench: A Compositional Benchmark for Vision-and-Language Manipulation
Jun 17, 2022



Benefiting from language flexibility and compositionality, humans naturally intend to use language to command an embodied agent for complex tasks such as navigation and object manipulation. In this work, we aim to fill the blank of the last mile of embodied agents -- object manipulation by following human guidance, e.g., "move the red mug next to the box while keeping it upright." To this end, we introduce an Automatic Manipulation Solver (AMSolver) simulator and build a Vision-and-Language Manipulation benchmark (VLMbench) based on it, containing various language instructions on categorized robotic manipulation tasks. Specifically, modular rule-based task templates are created to automatically generate robot demonstrations with language instructions, consisting of diverse object shapes and appearances, action types, and motion constraints. We also develop a keypoint-based model 6D-CLIPort to deal with multi-view observations and language input and output a sequence of 6 degrees of freedom (DoF) actions. We hope the new simulator and benchmark will facilitate future research on language-guided robotic manipulation.
Manipulation-Oriented Object Perception in Clutter through Affordance Coordinate Frames
Oct 16, 2020



In order to enable robust operation in unstructured environments, robots should be able to generalize manipulation actions to novel object instances. For example, to pour and serve a drink, a robot should be able to recognize novel containers which afford the task. Most importantly, robots should be able to manipulate these novel containers to fulfill the task. To achieve this, we aim to provide robust and generalized perception of object affordances and their associated manipulation poses for reliable manipulation. In this work, we combine the notions of affordance and category-level pose, and introduce the Affordance Coordinate Frame (ACF). With ACF, we represent each object class in terms of individual affordance parts and the compatibility between them, where each part is associated with a part category-level pose for robot manipulation. In our experiments, we demonstrate that ACF outperforms state-of-the-art methods for object detection, as well as category-level pose estimation for object parts. We further demonstrate the applicability of ACF to robot manipulation tasks through experiments in a simulated environment.