 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJialu Wang
WSCLoc: Weakly-Supervised Sparse-View Camera Relocalization
Mar 22, 2024
Despite the advancements in deep learning for camera relocalization tasks, obtaining ground truth pose labels required for the training process remains a costly endeavor. While current weakly supervised methods excel in lightweight label generation, their performance notably declines in scenarios with sparse views. In response to this challenge, we introduce WSCLoc, a system capable of being customized to various deep learning-based relocalization models to enhance their performance under weakly-supervised and sparse view conditions. This is realized with two stages. In the initial stage, WSCLoc employs a multilayer perceptron-based structure called WFT-NeRF to co-optimize image reconstruction quality and initial pose information. To ensure a stable learning process, we incorporate temporal information as input. Furthermore, instead of optimizing SE(3), we opt for $\mathfrak{sim}(3)$ optimization to explicitly enforce a scale constraint. In the second stage, we co-optimize the pre-trained WFT-NeRF and WFT-Pose. This optimization is enhanced by Time-Encoding based Random View Synthesis and supervised by inter-frame geometric constraints that consider pose, depth, and RGB information. We validate our approaches on two publicly available datasets, one outdoor and one indoor. Our experimental results demonstrate that our weakly-supervised relocalization solutions achieve superior pose estimation accuracy in sparse-view scenarios, comparable to state-of-the-art camera relocalization methods. We will make our code publicly available.
Fair Classifiers Without Fair Training: An Influence-Guided Data Sampling Approach
Feb 20, 2024A fair classifier should ensure the benefit of people from different groups, while the group information is often sensitive and unsuitable for model training. Therefore, learning a fair classifier but excluding sensitive attributes in the training dataset is important. In this paper, we study learning fair classifiers without implementing fair training algorithms to avoid possible leakage of sensitive information. Our theoretical analyses validate the possibility of this approach, that traditional training on a dataset with an appropriate distribution shift can reduce both the upper bound for fairness disparity and model generalization error, indicating that fairness and accuracy can be improved simultaneously with simply traditional training. We then propose a tractable solution to progressively shift the original training data during training by sampling influential data, where the sensitive attribute of new data is not accessed in sampling or used in training. Extensive experiments on real-world data demonstrate the effectiveness of our proposed algorithm.
Unmasking and Improving Data Credibility: A Study with Datasets for Training Harmless Language Models
Nov 19, 2023Language models have shown promise in various tasks but can be affected by undesired data during training, fine-tuning, or alignment. For example, if some unsafe conversations are wrongly annotated as safe ones, the model fine-tuned on these samples may be harmful. Therefore, the correctness of annotations, i.e., the credibility of the dataset, is important. This study focuses on the credibility of real-world datasets, including the popular benchmarks Jigsaw Civil Comments, Anthropic Harmless & Red Team, PKU BeaverTails & SafeRLHF, that can be used for training a harmless language model. Given the cost and difficulty of cleaning these datasets by humans, we introduce a systematic framework for evaluating the credibility of datasets, identifying label errors, and evaluating the influence of noisy labels in the curated language data, specifically focusing on unsafe comments and conversation classification. With the framework, we find and fix an average of 6.16% label errors in 11 datasets constructed from the above benchmarks. The data credibility and downstream learning performance can be remarkably improved by directly fixing label errors, indicating the significance of cleaning existing real-world datasets. Open-source: https://github.com/Docta-ai/docta.
T2IAT: Measuring Valence and Stereotypical Biases in Text-to-Image Generation
Jun 01, 2023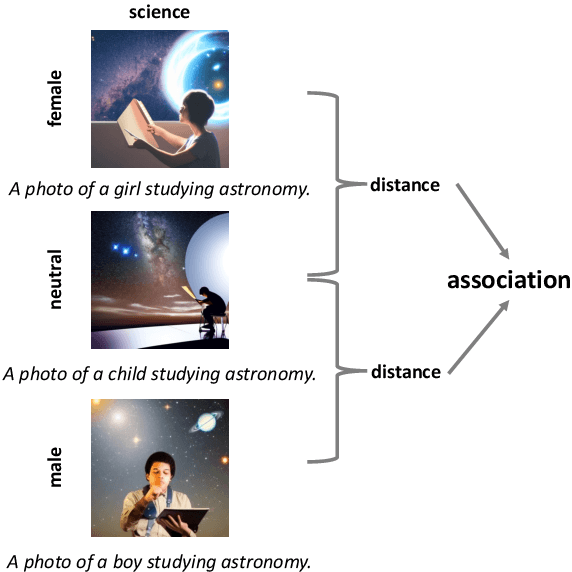


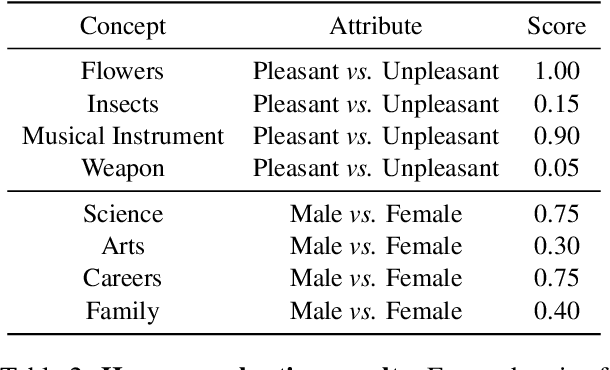
Warning: This paper contains several contents that may be toxic, harmful, or offensive. In the last few years, text-to-image generative models have gained remarkable success in generating images with unprecedented quality accompanied by a breakthrough of inference speed. Despite their rapid progress, human biases that manifest in the training examples, particularly with regard to common stereotypical biases, like gender and skin tone, still have been found in these generative models. In this work, we seek to measure more complex human biases exist in the task of text-to-image generations. Inspired by the well-known Implicit Association Test (IAT) from social psychology, we propose a novel Text-to-Image Association Test (T2IAT) framework that quantifies the implicit stereotypes between concepts and valence, and those in the images. We replicate the previously documented bias tests on generative models, including morally neutral tests on flowers and insects as well as demographic stereotypical tests on diverse social attributes. The results of these experiments demonstrate the presence of complex stereotypical behaviors in image generations.
Parameter-Efficient Cross-lingual Transfer of Vision and Language Models via Translation-based Alignment
May 02, 2023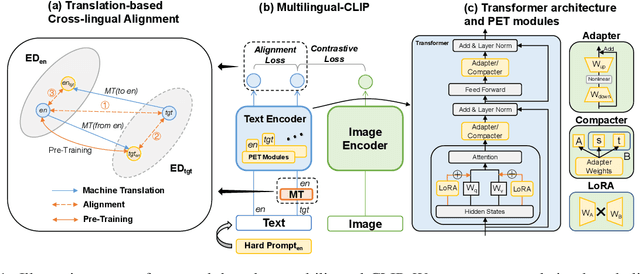
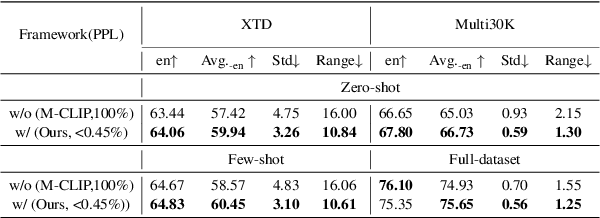
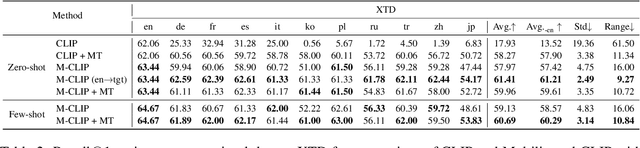
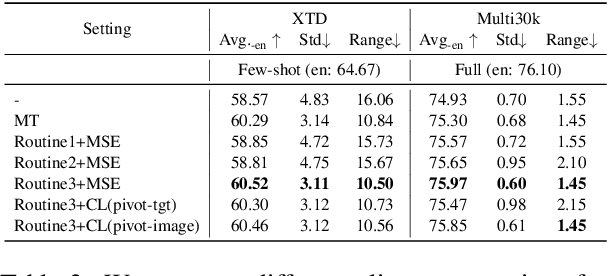
Pre-trained vision and language models such as CLIP have witnessed remarkable success in connecting images and texts with a primary focus on English texts. Despite recent efforts to extend CLIP to support other languages, disparities in performance among different languages have been observed due to uneven resource availability. Additionally, current cross-lingual transfer methods of those pre-trained models would consume excessive resources for a large number of languages. Therefore, we propose a new parameter-efficient cross-lingual transfer learning framework that utilizes a translation-based alignment method to mitigate multilingual disparities and explores parameter-efficient fine-tuning methods for parameter-efficient cross-lingual transfer. Extensive experiments on XTD and Multi30K datasets, covering 11 languages under zero-shot, few-shot, and full-dataset learning scenarios, show that our framework significantly reduces the multilingual disparities among languages and improves cross-lingual transfer results, especially in low-resource scenarios, while only keeping and fine-tuning an extremely small number of parameters compared to the full model (e.g., Our framework only requires 0.16\% additional parameters of a full-model for each language in the few-shot learning scenario).
Deep Learning based Multi-Label Image Classification of Protest Activities
Jan 10, 2023


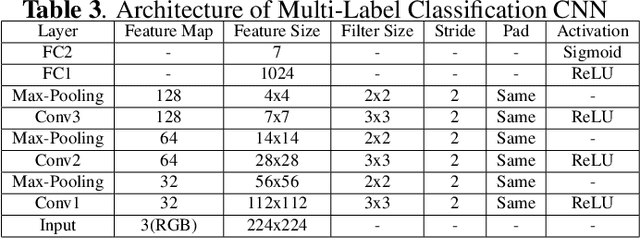
With the rise of internet technology amidst increasing rates of urbanization, sharing information has never been easier thanks to globally-adopted platforms for digital communication. The resulting output of massive amounts of user-generated data can be used to enhance our understanding of significant societal issues particularly for urbanizing areas. In order to better analyze protest behavior, we enhanced the GSR dataset and manually labeled all the images. We used deep learning techniques to analyze social media data to detect social unrest through image classification, which performed good in predict multi-attributes, then also used map visualization to display protest behaviors across the country.
JARVIS: A Neuro-Symbolic Commonsense Reasoning Framework for Conversational Embodied Agents
Aug 30, 2022

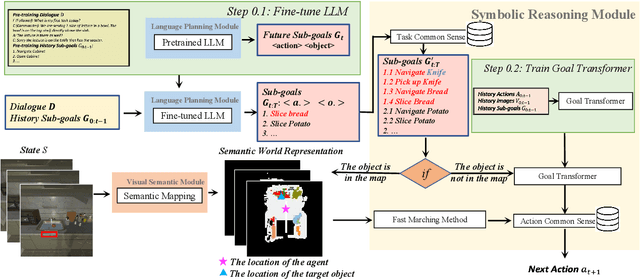

Building a conversational embodied agent to execute real-life tasks has been a long-standing yet quite challenging research goal, as it requires effective human-agent communication, multi-modal understanding, long-range sequential decision making, etc. Traditional symbolic methods have scaling and generalization issues, while end-to-end deep learning models suffer from data scarcity and high task complexity, and are often hard to explain. To benefit from both worlds, we propose a Neuro-Symbolic Commonsense Reasoning (JARVIS) framework for modular, generalizable, and interpretable conversational embodied agents. First, it acquires symbolic representations by prompting large language models (LLMs) for language understanding and sub-goal planning, and by constructing semantic maps from visual observations. Then the symbolic module reasons for sub-goal planning and action generation based on task- and action-level common sense. Extensive experiments on the TEACh dataset validate the efficacy and efficiency of our JARVIS framework, which achieves state-of-the-art (SOTA) results on all three dialog-based embodied tasks, including Execution from Dialog History (EDH), Trajectory from Dialog (TfD), and Two-Agent Task Completion (TATC) (e.g., our method boosts the unseen Success Rate on EDH from 6.1\% to 15.8\%). Moreover, we systematically analyze the essential factors that affect the task performance and also demonstrate the superiority of our method in few-shot settings. Our JARVIS model ranks first in the Alexa Prize SimBot Public Benchmark Challenge.
Understanding Instance-Level Impact of Fairness Constraints
Jun 30, 2022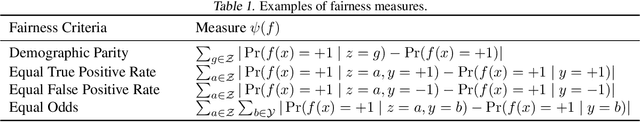
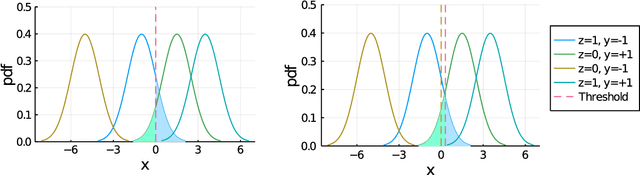
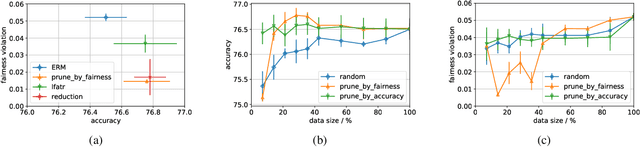
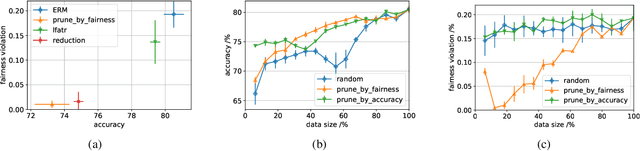
A variety of fairness constraints have been proposed in the literature to mitigate group-level statistical bias. Their impacts have been largely evaluated for different groups of populations corresponding to a set of sensitive attributes, such as race or gender. Nonetheless, the community has not observed sufficient explorations for how imposing fairness constraints fare at an instance level. Building on the concept of influence function, a measure that characterizes the impact of a training example on the target model and its predictive performance, this work studies the influence of training examples when fairness constraints are imposed. We find out that under certain assumptions, the influence function with respect to fairness constraints can be decomposed into a kernelized combination of training examples. One promising application of the proposed fairness influence function is to identify suspicious training examples that may cause model discrimination by ranking their influence scores. We demonstrate with extensive experiments that training on a subset of weighty data examples leads to lower fairness violations with a trade-off of accuracy.
Fairness Transferability Subject to Bounded Distribution Shift
May 31, 2022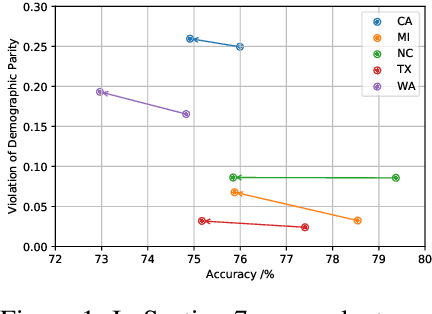

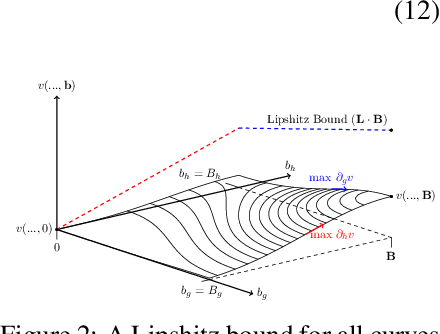
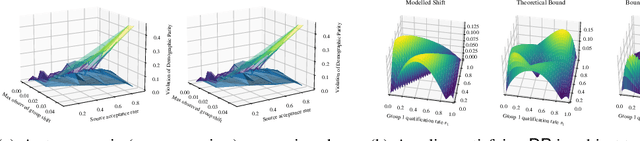
Given an algorithmic predictor that is "fair" on some source distribution, will it still be fair on an unknown target distribution that differs from the source within some bound? In this paper, we study the transferability of statistical group fairness for machine learning predictors (i.e., classifiers or regressors) subject to bounded distribution shift, a phenomenon frequently caused by user adaptation to a deployed model or a dynamic environment. Herein, we develop a bound characterizing such transferability, flagging potentially inappropriate deployments of machine learning for socially consequential tasks. We first develop a framework for bounding violations of statistical fairness subject to distribution shift, formulating a generic upper bound for transferred fairness violation as our primary result. We then develop bounds for specific worked examples, adopting two commonly used fairness definitions (i.e., demographic parity and equalized odds) for two classes of distribution shift (i.e., covariate shift and label shift). Finally, we compare our theoretical bounds to deterministic models of distribution shift as well as real-world data.
Beyond Images: Label Noise Transition Matrix Estimation for Tasks with Lower-Quality Features
Feb 02, 2022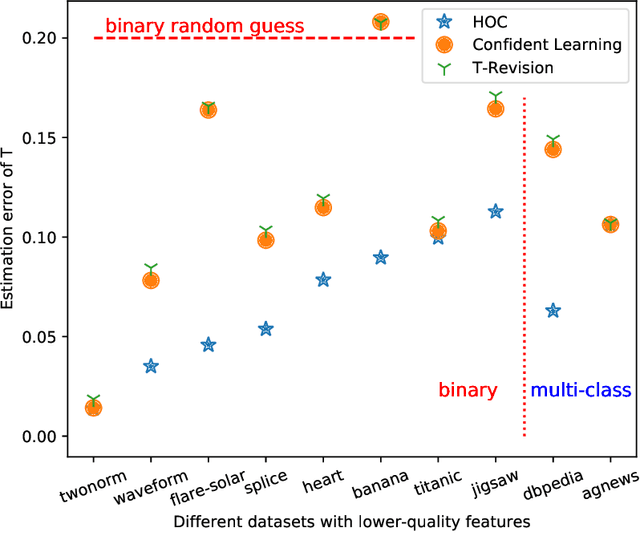
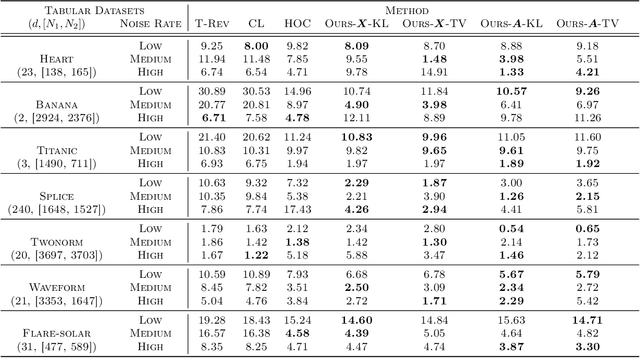
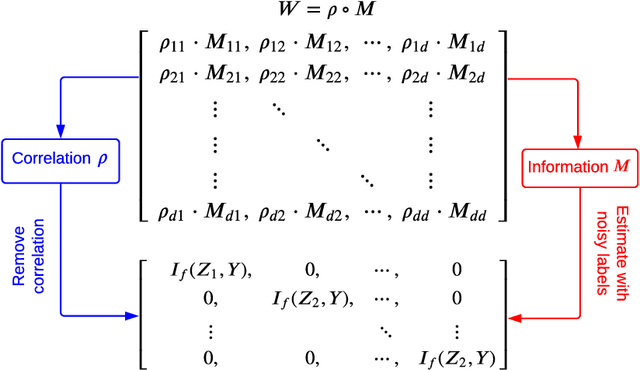
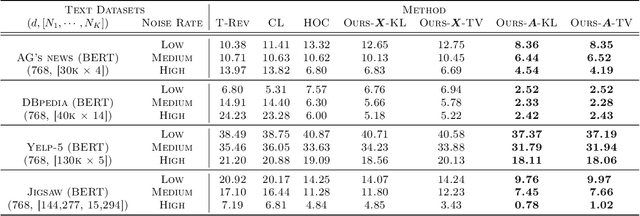
The label noise transition matrix, denoting the transition probabilities from clean labels to noisy labels, is crucial knowledge for designing statistically robust solutions. Existing estimators for noise transition matrices, e.g., using either anchor points or clusterability, focus on computer vision tasks that are relatively easier to obtain high-quality representations. However, for other tasks with lower-quality features, the uninformative variables may obscure the useful counterpart and make anchor-point or clusterability conditions hard to satisfy. We empirically observe the failures of these approaches on a number of commonly used datasets. In this paper, to handle this issue, we propose a generally practical information-theoretic approach to down-weight the less informative parts of the lower-quality features. The salient technical challenge is to compute the relevant information-theoretical metrics using only noisy labels instead of clean ones. We prove that the celebrated $f$-mutual information measure can often preserve the order when calculated using noisy labels. The necessity and effectiveness of the proposed method is also demonstrated by evaluating the estimation error on a varied set of tabular data and text classification tasks with lower-quality features. Code is available at github.com/UCSC-REAL/Est-T-MI.