 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKazuki Hayashi
Artwork Explanation in Large-scale Vision Language Models
Feb 29, 2024


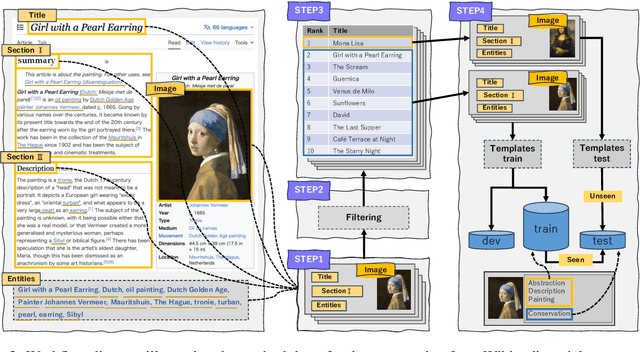
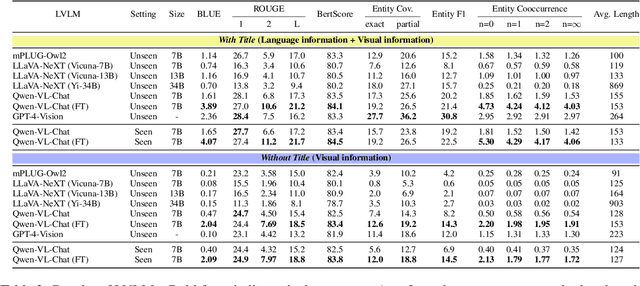
Large-scale vision-language models (LVLMs) output text from images and instructions, demonstrating advanced capabilities in text generation and comprehension. However, it has not been clarified to what extent LVLMs understand the knowledge necessary for explaining images, the complex relationships between various pieces of knowledge, and how they integrate these understandings into their explanations. To address this issue, we propose a new task: the artwork explanation generation task, along with its evaluation dataset and metric for quantitatively assessing the understanding and utilization of knowledge about artworks. This task is apt for image description based on the premise that LVLMs are expected to have pre-existing knowledge of artworks, which are often subjects of wide recognition and documented information. It consists of two parts: generating explanations from both images and titles of artworks, and generating explanations using only images, thus evaluating the LVLMs' language-based and vision-based knowledge. Alongside, we release a training dataset for LVLMs to learn explanations that incorporate knowledge about artworks. Our findings indicate that LVLMs not only struggle with integrating language and visual information but also exhibit a more pronounced limitation in acquiring knowledge from images alone. The datasets (ExpArt=Explain Artworks) are available at https://huggingface.co/datasets/naist-nlp/ExpArt.
Evaluating Image Review Ability of Vision Language Models
Feb 19, 2024Large-scale vision language models (LVLMs) are language models that are capable of processing images and text inputs by a single model. This paper explores the use of LVLMs to generate review texts for images. The ability of LVLMs to review images is not fully understood, highlighting the need for a methodical evaluation of their review abilities. Unlike image captions, review texts can be written from various perspectives such as image composition and exposure. This diversity of review perspectives makes it difficult to uniquely determine a single correct review for an image. To address this challenge, we introduce an evaluation method based on rank correlation analysis, in which review texts are ranked by humans and LVLMs, then, measures the correlation between these rankings. We further validate this approach by creating a benchmark dataset aimed at assessing the image review ability of recent LVLMs. Our experiments with the dataset reveal that LVLMs, particularly those with proven superiority in other evaluative contexts, excel at distinguishing between high-quality and substandard image reviews.
An Independently Learnable Hierarchical Model for Bilateral Control-Based Imitation Learning Applications
Mar 16, 2022



Recently, motion generation by machine learning has been actively researched to automate various tasks. Imitation learning is one such method that learns motions from data collected in advance. However, executing long-term tasks remains challenging. Therefore, a novel framework for imitation learning is proposed to solve this problem. The proposed framework comprises upper and lower layers, where the upper layer model, whose timescale is long, and lower layer model, whose timescale is short, can be independently trained. In this model, the upper layer learns long-term task planning, and the lower layer learns motion primitives. The proposed method was experimentally compared to hierarchical RNN-based methods to validate its effectiveness. Consequently, the proposed method showed a success rate equal to or greater than that of conventional methods. In addition, the proposed method required less than 1/20 of the training time compared to conventional methods. Moreover, it succeeded in executing unlearned tasks by reusing the trained lower layer.
A New Autoregressive Neural Network Model with Command Compensation for Imitation Learning Based on Bilateral Control
Mar 16, 2021



In the near future, robots are expected to work with humans or operate alone and may replace human workers in various fields such as homes and factories. In a previous study, we proposed bilateral control-based imitation learning that enables robots to utilize force information and operate almost simultaneously with an expert's demonstration. In addition, we recently proposed an autoregressive neural network model (SM2SM) for bilateral control-based imitation learning to obtain long-term inferences. In the SM2SM model, both master and slave states must be input, but the master states are obtained from the previous outputs of the SM2SM model, resulting in destabilized estimation under large environmental variations. Hence, a new autoregressive neural network model (S2SM) is proposed in this study. This model requires only the slave state as input and its outputs are the next slave and master states, thereby improving the task success rates. In addition, a new feedback controller that utilizes the error between the responses and estimates of the slave is proposed, which shows better reproducibility.