 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYusuke Sakai
Simultaneous Interpretation Corpus Construction by Large Language Models in Distant Language Pair
Apr 18, 2024
In Simultaneous Machine Translation (SiMT) systems, training with a simultaneous interpretation (SI) corpus is an effective method for achieving high-quality yet low-latency systems. However, it is very challenging to curate such a corpus due to limitations in the abilities of annotators, and hence, existing SI corpora are limited. Therefore, we propose a method to convert existing speech translation corpora into interpretation-style data, maintaining the original word order and preserving the entire source content using Large Language Models (LLM-SI-Corpus). We demonstrate that fine-tuning SiMT models in text-to-text and speech-to-text settings with the LLM-SI-Corpus reduces latencies while maintaining the same level of quality as the models trained with offline datasets. The LLM-SI-Corpus is available at \url{https://github.com/yusuke1997/LLM-SI-Corpus}.
Artwork Explanation in Large-scale Vision Language Models
Feb 29, 2024

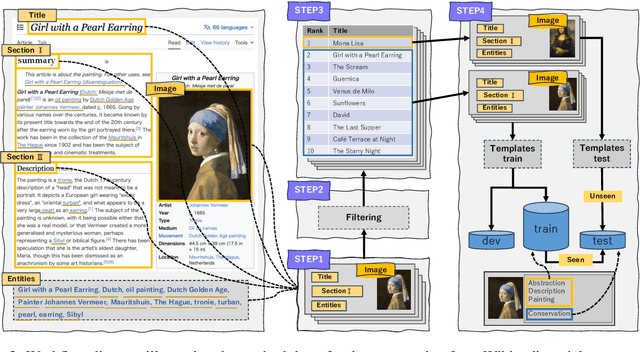
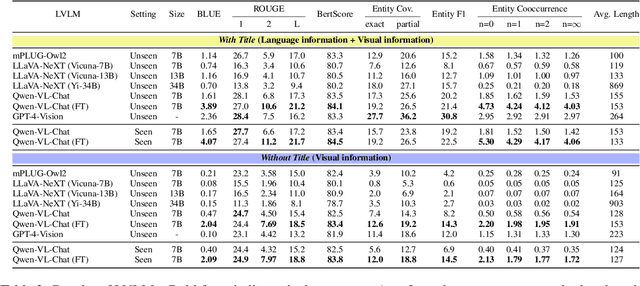
Large-scale vision-language models (LVLMs) output text from images and instructions, demonstrating advanced capabilities in text generation and comprehension. However, it has not been clarified to what extent LVLMs understand the knowledge necessary for explaining images, the complex relationships between various pieces of knowledge, and how they integrate these understandings into their explanations. To address this issue, we propose a new task: the artwork explanation generation task, along with its evaluation dataset and metric for quantitatively assessing the understanding and utilization of knowledge about artworks. This task is apt for image description based on the premise that LVLMs are expected to have pre-existing knowledge of artworks, which are often subjects of wide recognition and documented information. It consists of two parts: generating explanations from both images and titles of artworks, and generating explanations using only images, thus evaluating the LVLMs' language-based and vision-based knowledge. Alongside, we release a training dataset for LVLMs to learn explanations that incorporate knowledge about artworks. Our findings indicate that LVLMs not only struggle with integrating language and visual information but also exhibit a more pronounced limitation in acquiring knowledge from images alone. The datasets (ExpArt=Explain Artworks) are available at https://huggingface.co/datasets/naist-nlp/ExpArt.
Evaluating Image Review Ability of Vision Language Models
Feb 19, 2024Large-scale vision language models (LVLMs) are language models that are capable of processing images and text inputs by a single model. This paper explores the use of LVLMs to generate review texts for images. The ability of LVLMs to review images is not fully understood, highlighting the need for a methodical evaluation of their review abilities. Unlike image captions, review texts can be written from various perspectives such as image composition and exposure. This diversity of review perspectives makes it difficult to uniquely determine a single correct review for an image. To address this challenge, we introduce an evaluation method based on rank correlation analysis, in which review texts are ranked by humans and LVLMs, then, measures the correlation between these rankings. We further validate this approach by creating a benchmark dataset aimed at assessing the image review ability of recent LVLMs. Our experiments with the dataset reveal that LVLMs, particularly those with proven superiority in other evaluative contexts, excel at distinguishing between high-quality and substandard image reviews.
Centroid-Based Efficient Minimum Bayes Risk Decoding
Feb 17, 2024
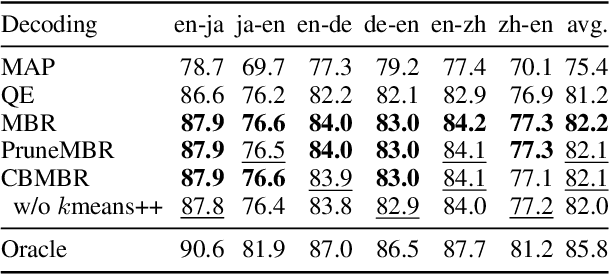

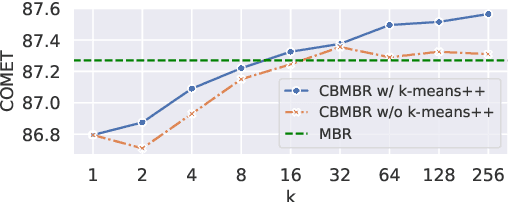
Minimum Bayes risk (MBR) decoding achieved state-of-the-art translation performance by using COMET, a neural metric that has a high correlation with human evaluation. However, MBR decoding requires quadratic time since it computes the expected score between a translation hypothesis and all reference translations. We propose centroid-based MBR (CBMBR) decoding to improve the speed of MBR decoding. Our method clusters the reference translations in the feature space, and then calculates the score using the centroids of each cluster. The experimental results show that our CBMBR not only improved the decoding speed of the expected score calculation 6.9 times, but also outperformed vanilla MBR decoding in translation quality by up to 0.5 COMET in the WMT'22 En$\leftrightarrow$Ja, En$\leftrightarrow$De, En$\leftrightarrow$Zh, and WMT'23 En$\leftrightarrow$Ja translation tasks.
Does Pre-trained Language Model Actually Infer Unseen Links in Knowledge Graph Completion?
Nov 15, 2023Knowledge graphs (KGs) consist of links that describe relationships between entities. Due to the difficulty of manually enumerating all relationships between entities, automatically completing them is essential for KGs. Knowledge Graph Completion (KGC) is a task that infers unseen relationships between entities in a KG. Traditional embedding-based KGC methods, such as RESCAL, TransE, DistMult, ComplEx, RotatE, HAKE, HousE, etc., infer missing links using only the knowledge from training data. In contrast, the recent Pre-trained Language Model (PLM)-based KGC utilizes knowledge obtained during pre-training. Therefore, PLM-based KGC can estimate missing links between entities by reusing memorized knowledge from pre-training without inference. This approach is problematic because building KGC models aims to infer unseen links between entities. However, conventional evaluations in KGC do not consider inference and memorization abilities separately. Thus, a PLM-based KGC method, which achieves high performance in current KGC evaluations, may be ineffective in practical applications. To address this issue, we analyze whether PLM-based KGC methods make inferences or merely access memorized knowledge. For this purpose, we propose a method for constructing synthetic datasets specified in this analysis and conclude that PLMs acquire the inference abilities required for KGC through pre-training, even though the performance improvements mostly come from textual information of entities and relations.
Universal Automatic Phonetic Transcription into the International Phonetic Alphabet
Aug 07, 2023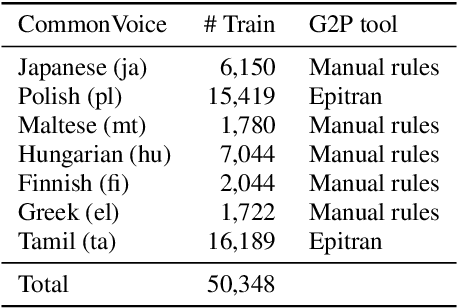

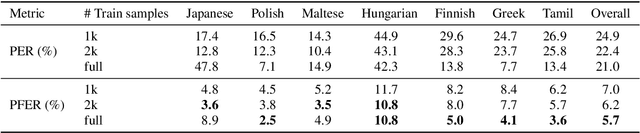
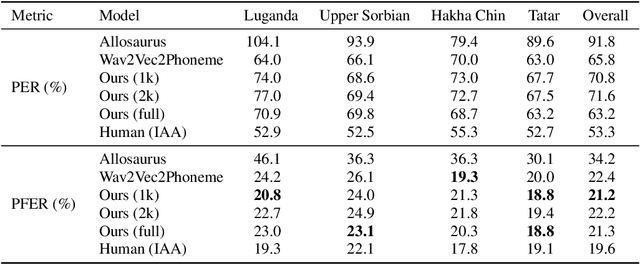
This paper presents a state-of-the-art model for transcribing speech in any language into the International Phonetic Alphabet (IPA). Transcription of spoken languages into IPA is an essential yet time-consuming process in language documentation, and even partially automating this process has the potential to drastically speed up the documentation of endangered languages. Like the previous best speech-to-IPA model (Wav2Vec2Phoneme), our model is based on wav2vec 2.0 and is fine-tuned to predict IPA from audio input. We use training data from seven languages from CommonVoice 11.0, transcribed into IPA semi-automatically. Although this training dataset is much smaller than Wav2Vec2Phoneme's, its higher quality lets our model achieve comparable or better results. Furthermore, we show that the quality of our universal speech-to-IPA models is close to that of human annotators.
FG-SSA: Features Gradient-based Signals Selection Algorithm of Linear Complexity for Convolutional Neural Networks
Feb 23, 2023



Recently, many convolutional neural networks (CNNs) for classification by time domain data of multisignals have been developed. Although some signals are important for correct classification, others are not. When data that do not include important signals for classification are taken as the CNN input layer, the calculation, memory, and data collection costs increase. Therefore, identifying and eliminating nonimportant signals from the input layer are important. In this study, we proposed features gradient-based signals selection algorithm (FG-SSA), which can be used for finding and removing nonimportant signals for classification by utilizing features gradient obtained by the calculation process of grad-CAM. When we define N as the number of signals, the computational complexity of the proposed algorithm is linear time O(N), that is, it has a low calculation cost. We verified the effectiveness of the algorithm using the OPPORTUNITY Activity Recognition dataset, which is an open dataset comprising acceleration signals of human activities. In addition, we checked the average 6.55 signals from a total of 15 acceleration signals (five triaxial sensors) that were removed by FG-SSA while maintaining high generalization scores of classification. Therefore, the proposed algorithm FG-SSA has an effect on finding and removing signals that are not important for CNN-based classification.
Training Process of Unsupervised Learning Architecture for Gravity Spy Dataset
Aug 07, 2022



Transient noise appearing in the data from gravitational-wave detectors frequently causes problems, such as instability of the detectors and overlapping or mimicking gravitational-wave signals. Because transient noise is considered to be associated with the environment and instrument, its classification would help to understand its origin and improve the detector's performance. In a previous study, an architecture for classifying transient noise using a time-frequency 2D image (spectrogram) is proposed, which uses unsupervised deep learning combined with variational autoencoder and invariant information clustering. The proposed unsupervised-learning architecture is applied to the Gravity Spy dataset, which consists of Advanced Laser Interferometer Gravitational-Wave Observatory (Advanced LIGO) transient noises with their associated metadata to discuss the potential for online or offline data analysis. In this study, focused on the Gravity Spy dataset, the training process of unsupervised-learning architecture of the previous study is examined and reported.
* 17 pages, 10 figures, Matches version published in Annalen der Physik