 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKe Liu
Image change detection with only a few samples
Nov 07, 2023
This paper considers image change detection with only a small number of samples, which is a significant problem in terms of a few annotations available. A major impediment of image change detection task is the lack of large annotated datasets covering a wide variety of scenes. Change detection models trained on insufficient datasets have shown poor generalization capability. To address the poor generalization issue, we propose using simple image processing methods for generating synthetic but informative datasets, and design an early fusion network based on object detection which could outperform the siamese neural network. Our key insight is that the synthetic data enables the trained model to have good generalization ability for various scenarios. We compare the model trained on the synthetic data with that on the real-world data captured from a challenging dataset, CDNet, using six different test sets. The results demonstrate that the synthetic data is informative enough to achieve higher generalization ability than the insufficient real-world data. Besides, the experiment shows that utilizing a few (often tens of) samples to fine-tune the model trained on the synthetic data will achieve excellent results.
Partition Speeds Up Learning Implicit Neural Representations Based on Exponential-Increase Hypothesis
Oct 22, 2023
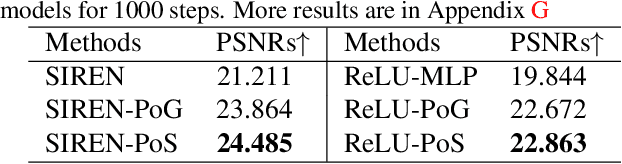
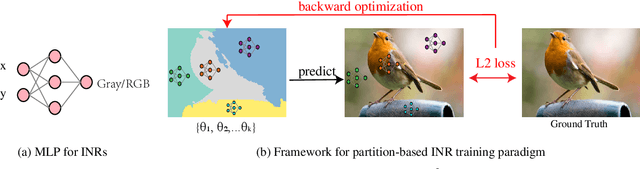

$\textit{Implicit neural representations}$ (INRs) aim to learn a $\textit{continuous function}$ (i.e., a neural network) to represent an image, where the input and output of the function are pixel coordinates and RGB/Gray values, respectively. However, images tend to consist of many objects whose colors are not perfectly consistent, resulting in the challenge that image is actually a $\textit{discontinuous piecewise function}$ and cannot be well estimated by a continuous function. In this paper, we empirically investigate that if a neural network is enforced to fit a discontinuous piecewise function to reach a fixed small error, the time costs will increase exponentially with respect to the boundaries in the spatial domain of the target signal. We name this phenomenon the $\textit{exponential-increase}$ hypothesis. Under the $\textit{exponential-increase}$ hypothesis, learning INRs for images with many objects will converge very slowly. To address this issue, we first prove that partitioning a complex signal into several sub-regions and utilizing piecewise INRs to fit that signal can significantly speed up the convergence. Based on this fact, we introduce a simple partition mechanism to boost the performance of two INR methods for image reconstruction: one for learning INRs, and the other for learning-to-learn INRs. In both cases, we partition an image into different sub-regions and dedicate smaller networks for each part. In addition, we further propose two partition rules based on regular grids and semantic segmentation maps, respectively. Extensive experiments validate the effectiveness of the proposed partitioning methods in terms of learning INR for a single image (ordinary learning framework) and the learning-to-learn framework.
Unified Matrix Factorization with Dynamic Multi-view Clustering
Aug 13, 2023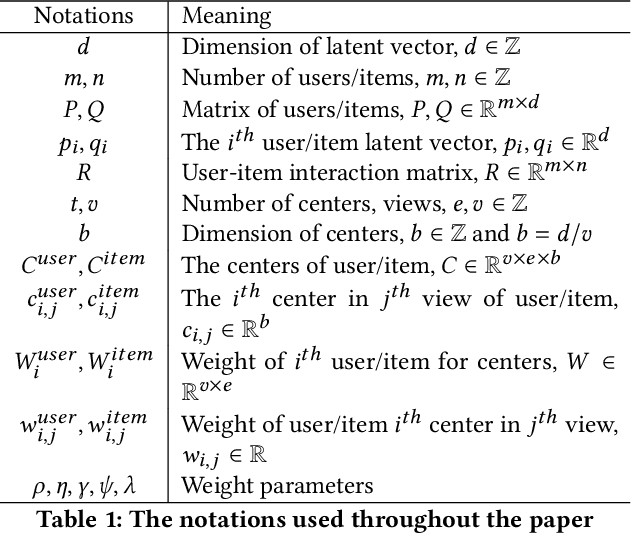
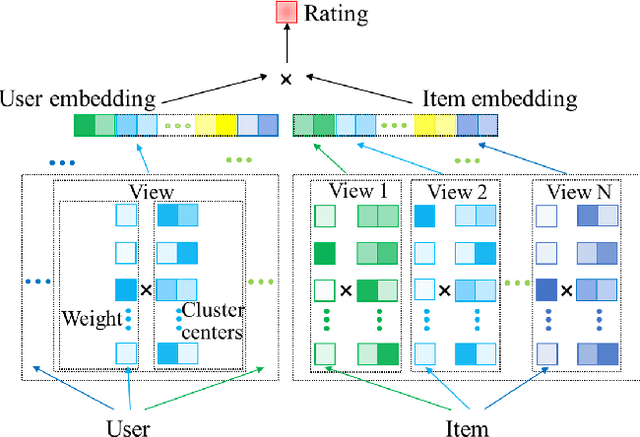
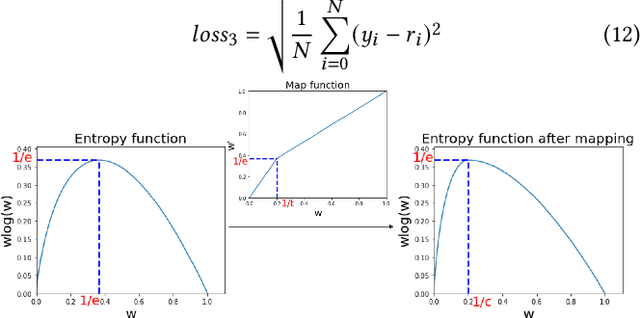
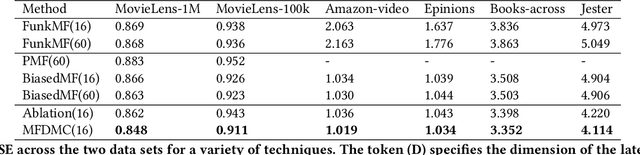
Matrix factorization (MF) is a classical collaborative filtering algorithm for recommender systems. It decomposes the user-item interaction matrix into a product of low-dimensional user representation matrix and item representation matrix. In typical recommendation scenarios, the user-item interaction paradigm is usually a two-stage process and requires static clustering analysis of the obtained user and item representations. The above process, however, is time and computationally intensive, making it difficult to apply in real-time to e-commerce or Internet of Things environments with billions of users and trillions of items. To address this, we propose a unified matrix factorization method based on dynamic multi-view clustering (MFDMC) that employs an end-to-end training paradigm. Specifically, in each view, a user/item representation is regarded as a weighted projection of all clusters. The representation of each cluster is learnable, enabling the dynamic discarding of bad clusters. Furthermore, we employ multi-view clustering to represent multiple roles of users/items, effectively utilizing the representation space and improving the interpretability of the user/item representations for downstream tasks. Extensive experiments show that our proposed MFDMC achieves state-of-the-art performance on real-world recommendation datasets. Additionally, comprehensive visualization and ablation studies interpretably confirm that our method provides meaningful representations for downstream tasks of users/items.
Contrastive Knowledge Amalgamation for Unsupervised Image Classification
Jul 27, 2023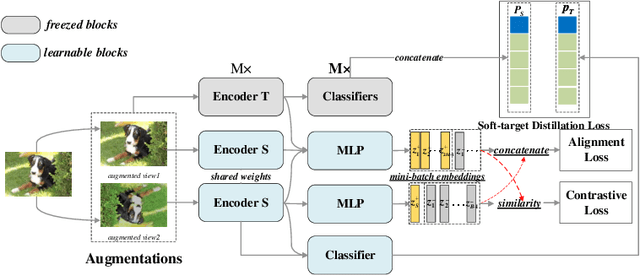
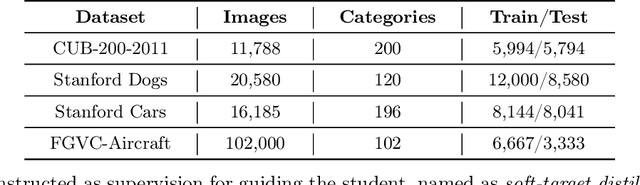
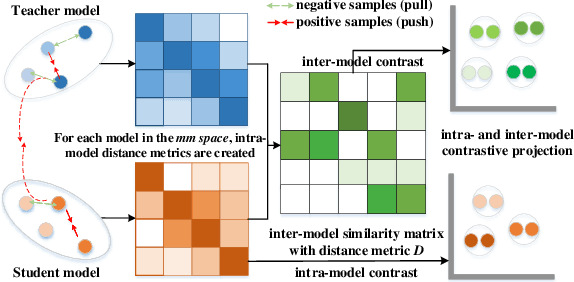
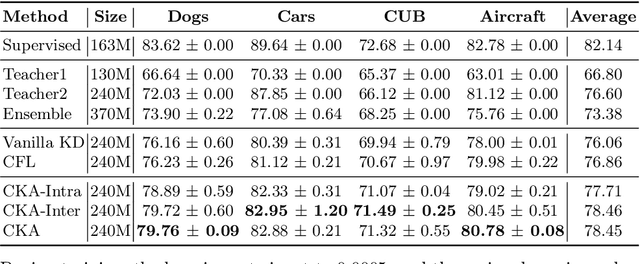
Knowledge amalgamation (KA) aims to learn a compact student model to handle the joint objective from multiple teacher models that are are specialized for their own tasks respectively. Current methods focus on coarsely aligning teachers and students in the common representation space, making it difficult for the student to learn the proper decision boundaries from a set of heterogeneous teachers. Besides, the KL divergence in previous works only minimizes the probability distribution difference between teachers and the student, ignoring the intrinsic characteristics of teachers. Therefore, we propose a novel Contrastive Knowledge Amalgamation (CKA) framework, which introduces contrastive losses and an alignment loss to achieve intra-class cohesion and inter-class separation.Contrastive losses intra- and inter- models are designed to widen the distance between representations of different classes. The alignment loss is introduced to minimize the sample-level distribution differences of teacher-student models in the common representation space.Furthermore, the student learns heterogeneous unsupervised classification tasks through soft targets efficiently and flexibly in the task-level amalgamation. Extensive experiments on benchmarks demonstrate the generalization capability of CKA in the amalgamation of specific task as well as multiple tasks. Comprehensive ablation studies provide a further insight into our CKA.
$E(2)$-Equivariant Vision Transformer
Jul 04, 2023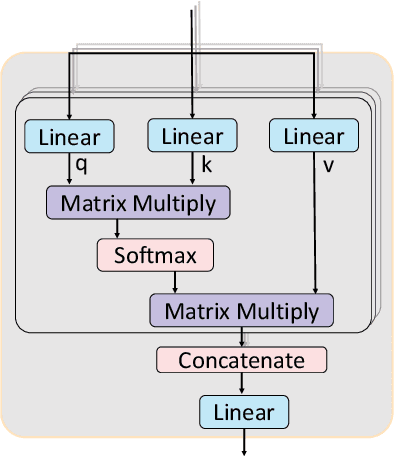
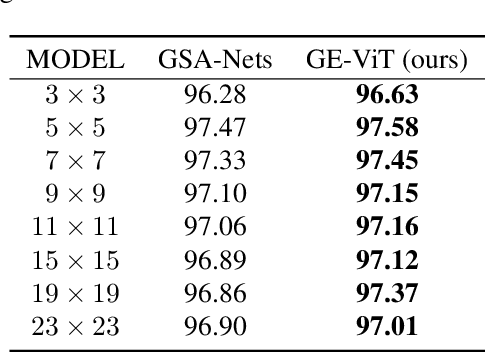
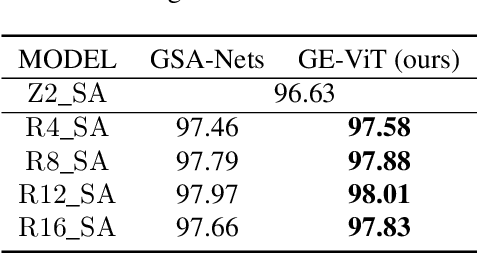
Vision Transformer (ViT) has achieved remarkable performance in computer vision. However, positional encoding in ViT makes it substantially difficult to learn the intrinsic equivariance in data. Initial attempts have been made on designing equivariant ViT but are proved defective in some cases in this paper. To address this issue, we design a Group Equivariant Vision Transformer (GE-ViT) via a novel, effective positional encoding operator. We prove that GE-ViT meets all the theoretical requirements of an equivariant neural network. Comprehensive experiments are conducted on standard benchmark datasets, demonstrating that GE-ViT significantly outperforms non-equivariant self-attention networks. The code is available at https://github.com/ZJUCDSYangKaifan/GEVit.
S2SNet: A Pretrained Neural Network for Superconductivity Discovery
Jun 28, 2023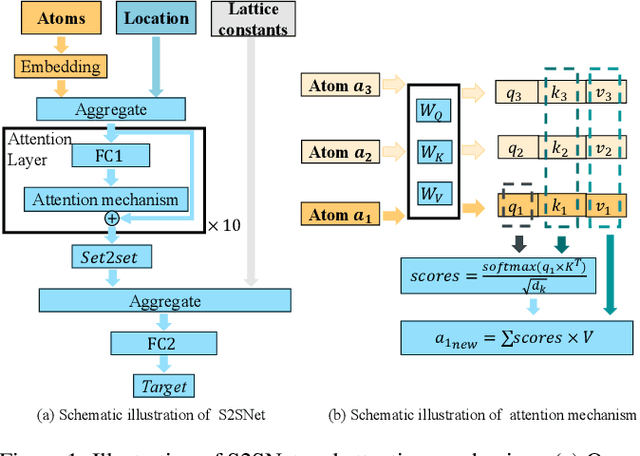

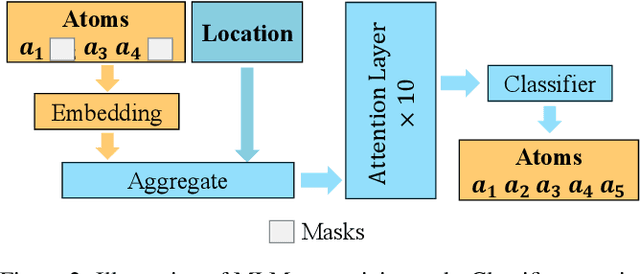
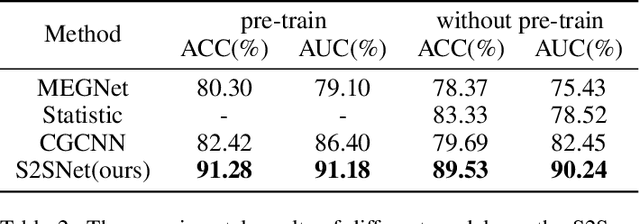
Superconductivity allows electrical current to flow without any energy loss, and thus making solids superconducting is a grand goal of physics, material science, and electrical engineering. More than 16 Nobel Laureates have been awarded for their contribution to superconductivity research. Superconductors are valuable for sustainable development goals (SDGs), such as climate change mitigation, affordable and clean energy, industry, innovation and infrastructure, and so on. However, a unified physics theory explaining all superconductivity mechanism is still unknown. It is believed that superconductivity is microscopically due to not only molecular compositions but also the geometric crystal structure. Hence a new dataset, S2S, containing both crystal structures and superconducting critical temperature, is built upon SuperCon and Material Project. Based on this new dataset, we propose a novel model, S2SNet, which utilizes the attention mechanism for superconductivity prediction. To overcome the shortage of data, S2SNet is pre-trained on the whole Material Project dataset with Masked-Language Modeling (MLM). S2SNet makes a new state-of-the-art, with out-of-sample accuracy of 92% and Area Under Curve (AUC) of 0.92. To the best of our knowledge, S2SNet is the first work to predict superconductivity with only information of crystal structures. This work is beneficial to superconductivity discovery and further SDGs. Code and datasets are available in https://github.com/zjuKeLiu/S2SNet
Supervised Deep Hashing for High-dimensional and Heterogeneous Case-based Reasoning
Jun 29, 2022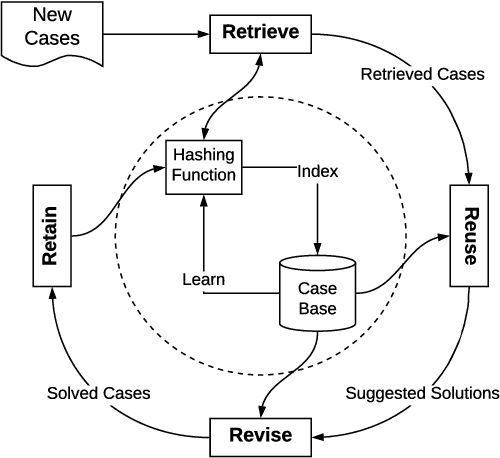
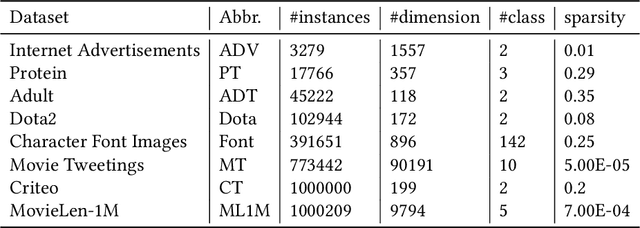
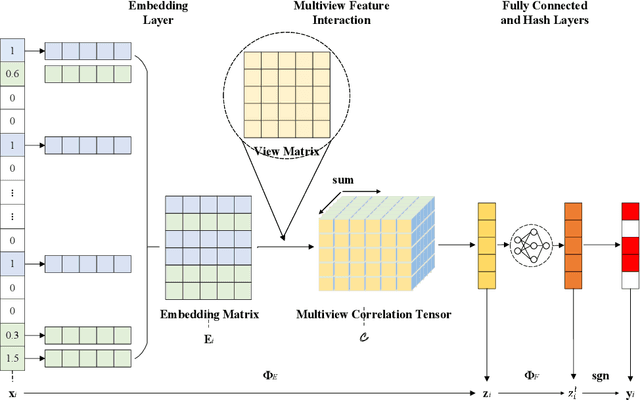
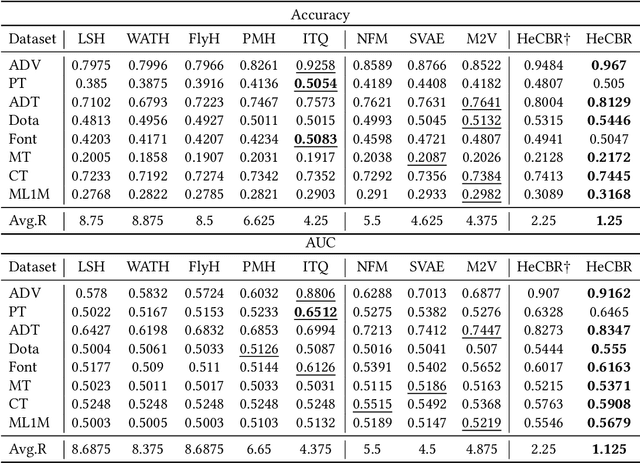
Case-based Reasoning (CBR) on high-dimensional and heterogeneous data is a trending yet challenging and computationally expensive task in the real world. A promising approach is to obtain low-dimensional hash codes representing cases and perform a similarity retrieval of cases in Hamming space. However, previous methods based on data-independent hashing rely on random projections or manual construction, inapplicable to address specific data issues (e.g., high-dimensionality and heterogeneity) due to their insensitivity to data characteristics. To address these issues, this work introduces a novel deep hashing network to learn similarity-preserving compact hash codes for efficient case retrieval and proposes a deep-hashing-enabled CBR model HeCBR. Specifically, we introduce position embedding to represent heterogeneous features and utilize a multilinear interaction layer to obtain case embeddings, which effectively filtrates zero-valued features to tackle high-dimensionality and sparsity and captures inter-feature couplings. Then, we feed the case embeddings into fully-connected layers, and subsequently a hash layer generates hash codes with a quantization regularizer to control the quantization loss during relaxation. To cater to incremental learning of CBR, we further propose an adaptive learning strategy to update the hash function. Extensive experiments on public datasets show that HeCBR greatly reduces storage and significantly accelerates case retrieval. HeCBR achieves desirable performance compared with the state-of-the-art CBR methods and performs significantly better than hashing-based CBR methods in classification.
Learning Universal User Representations via Self-Supervised Lifelong Behaviors Modeling
Oct 25, 2021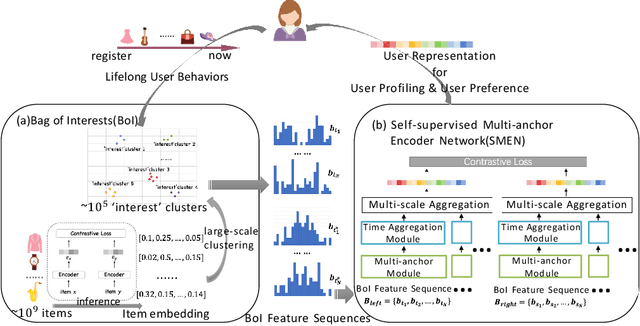

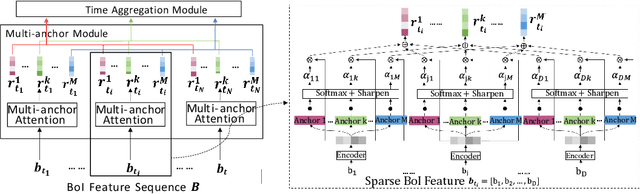
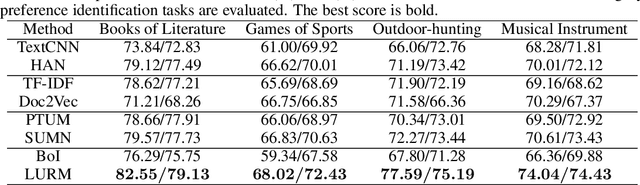
Universal user representation is an important research topic in industry, and is widely used in diverse downstream user analysis tasks, such as user profiling and user preference prediction. With the rapid development of Internet service platforms, extremely long user behavior sequences have been accumulated. However, existing researches have little ability to model universal user representation based on lifelong sequences of user behavior since registration. In this study, we propose a novel framework called Lifelong User Representation Model (LURM) to tackle this challenge. Specifically, LURM consists of two cascaded sub-models: (i) Bag of Interests (BoI) encodes user behaviors in any time period into a sparse vector with super-high dimension (e.g.,105); (ii) Self-supervised Multi-anchor EncoderNetwork (SMEN) maps sequences of BoI features to multiple low-dimensional user representations by contrastive learning. SMEN achieves almost lossless dimensionality reduction, benefiting from a novel multi-anchor module which can learn different aspects of user preferences. Experiments on several benchmark datasets show that our approach outperforms state-of-the-art unsupervised representation methods in downstream tasks
Focusing on Persons: Colorizing Old Images Learning from Modern Historical Movies
Aug 14, 2021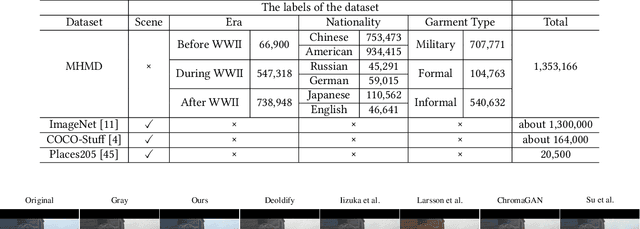
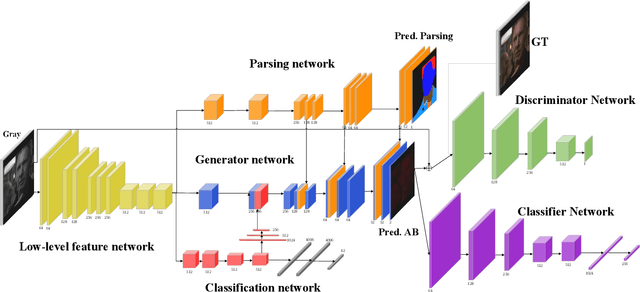
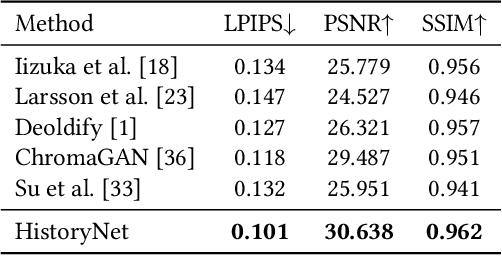
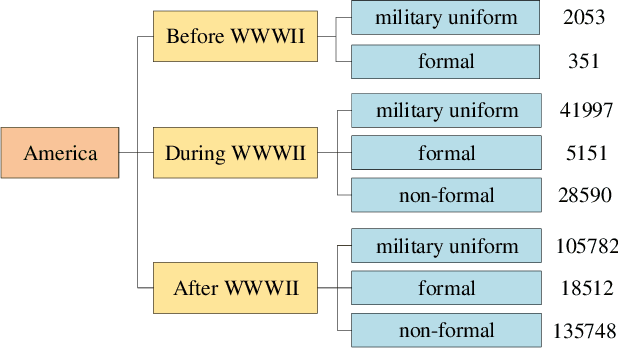
In industry, there exist plenty of scenarios where old gray photos need to be automatically colored, such as video sites and archives. In this paper, we present the HistoryNet focusing on historical person's diverse high fidelity clothing colorization based on fine grained semantic understanding and prior. Colorization of historical persons is realistic and practical, however, existing methods do not perform well in the regards. In this paper, a HistoryNet including three parts, namely, classification, fine grained semantic parsing and colorization, is proposed. Classification sub-module supplies classifying of images according to the eras, nationalities and garment types; Parsing sub-network supplies the semantic for person contours, clothing and background in the image to achieve more accurate colorization of clothes and persons and prevent color overflow. In the training process, we integrate classification and semantic parsing features into the coloring generation network to improve colorization. Through the design of classification and parsing subnetwork, the accuracy of image colorization can be improved and the boundary of each part of image can be more clearly. Moreover, we also propose a novel Modern Historical Movies Dataset (MHMD) containing 1,353,166 images and 42 labels of eras, nationalities, and garment types for automatic colorization from 147 historical movies or TV series made in modern time. Various quantitative and qualitative comparisons demonstrate that our method outperforms the state-of-the-art colorization methods, especially on military uniforms, which has correct colors according to the historical literatures.
ChemiRise: a data-driven retrosynthesis engine
Aug 09, 2021
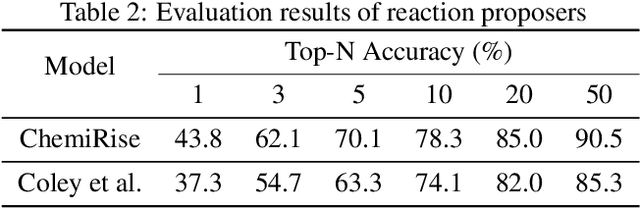

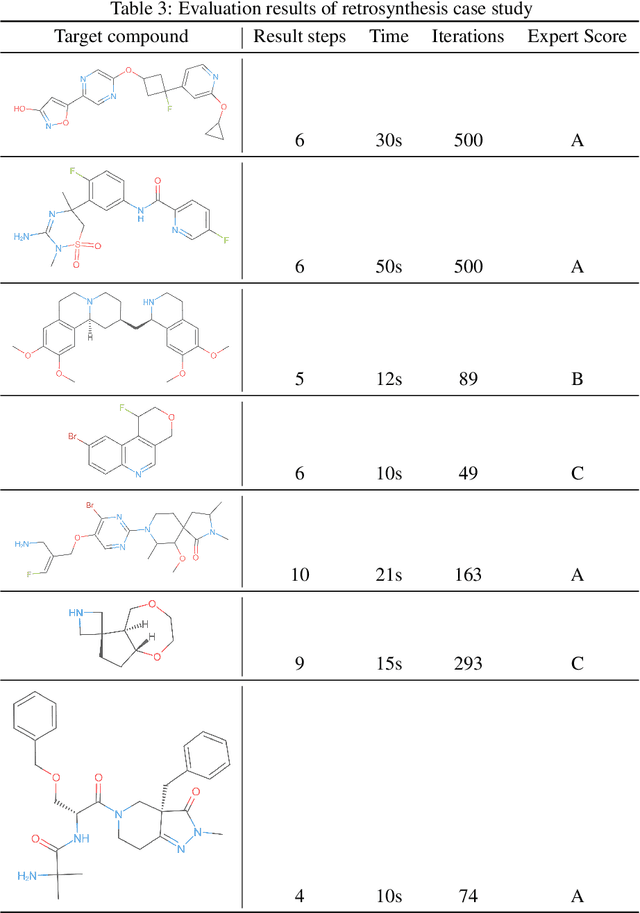
We have developed an end-to-end, retrosynthesis system, named ChemiRise, that can propose complete retrosynthesis routes for organic compounds rapidly and reliably. The system was trained on a processed patent database of over 3 million organic reactions. Experimental reactions were atom-mapped, clustered, and extracted into reaction templates. We then trained a graph convolutional neural network-based one-step reaction proposer using template embeddings and developed a guiding algorithm on the directed acyclic graph (DAG) of chemical compounds to find the best candidate to explore. The atom-mapping algorithm and the one-step reaction proposer were benchmarked against previous studies and showed better results. The final product was demonstrated by retrosynthesis routes reviewed and rated by human experts, showing satisfying functionality and a potential productivity boost in real-life use cases.