 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKenza Bouzid
RAD-DINO: Exploring Scalable Medical Image Encoders Beyond Text Supervision
Jan 19, 2024
Language-supervised pre-training has proven to be a valuable method for extracting semantically meaningful features from images, serving as a foundational element in multimodal systems within the computer vision and medical imaging domains. However, resulting features are limited by the information contained within the text. This is particularly problematic in medical imaging, where radiologists' written findings focus on specific observations; a challenge compounded by the scarcity of paired imaging-text data due to concerns over leakage of personal health information. In this work, we fundamentally challenge the prevailing reliance on language supervision for learning general purpose biomedical imaging encoders. We introduce RAD-DINO, a biomedical image encoder pre-trained solely on unimodal biomedical imaging data that obtains similar or greater performance than state-of-the-art biomedical language supervised models on a diverse range of benchmarks. Specifically, the quality of learned representations is evaluated on standard imaging tasks (classification and semantic segmentation), and a vision-language alignment task (text report generation from images). To further demonstrate the drawback of language supervision, we show that features from RAD-DINO correlate with other medical records (e.g., sex or age) better than language-supervised models, which are generally not mentioned in radiology reports. Finally, we conduct a series of ablations determining the factors in RAD-DINO's performance; notably, we observe that RAD-DINO's downstream performance scales well with the quantity and diversity of training data, demonstrating that image-only supervision is a scalable approach for training a foundational biomedical image encoder.
MAIRA-1: A specialised large multimodal model for radiology report generation
Nov 22, 2023We present a radiology-specific multimodal model for the task for generating radiological reports from chest X-rays (CXRs). Our work builds on the idea that large language model(s) can be equipped with multimodal capabilities through alignment with pre-trained vision encoders. On natural images, this has been shown to allow multimodal models to gain image understanding and description capabilities. Our proposed model (MAIRA-1) leverages a CXR-specific image encoder in conjunction with a fine-tuned large language model based on Vicuna-7B, and text-based data augmentation, to produce reports with state-of-the-art quality. In particular, MAIRA-1 significantly improves on the radiologist-aligned RadCliQ metric and across all lexical metrics considered. Manual review of model outputs demonstrates promising fluency and accuracy of generated reports while uncovering failure modes not captured by existing evaluation practices. More information and resources can be found on the project website: https://aka.ms/maira.
Exploring the Boundaries of GPT-4 in Radiology
Oct 23, 2023The recent success of general-domain large language models (LLMs) has significantly changed the natural language processing paradigm towards a unified foundation model across domains and applications. In this paper, we focus on assessing the performance of GPT-4, the most capable LLM so far, on the text-based applications for radiology reports, comparing against state-of-the-art (SOTA) radiology-specific models. Exploring various prompting strategies, we evaluated GPT-4 on a diverse range of common radiology tasks and we found GPT-4 either outperforms or is on par with current SOTA radiology models. With zero-shot prompting, GPT-4 already obtains substantial gains ($\approx$ 10% absolute improvement) over radiology models in temporal sentence similarity classification (accuracy) and natural language inference ($F_1$). For tasks that require learning dataset-specific style or schema (e.g. findings summarisation), GPT-4 improves with example-based prompting and matches supervised SOTA. Our extensive error analysis with a board-certified radiologist shows GPT-4 has a sufficient level of radiology knowledge with only occasional errors in complex context that require nuanced domain knowledge. For findings summarisation, GPT-4 outputs are found to be overall comparable with existing manually-written impressions.
Learning to Exploit Temporal Structure for Biomedical Vision-Language Processing
Jan 11, 2023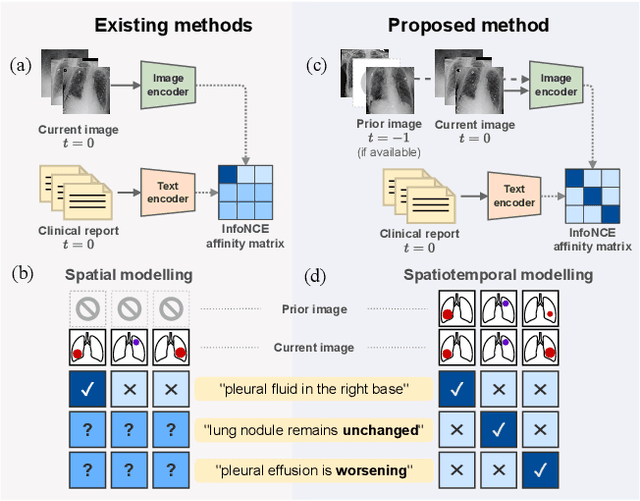
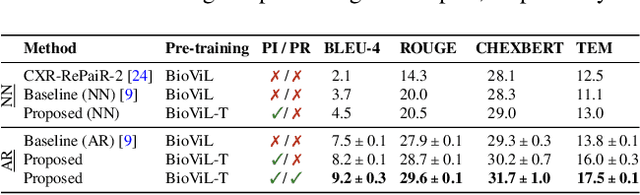
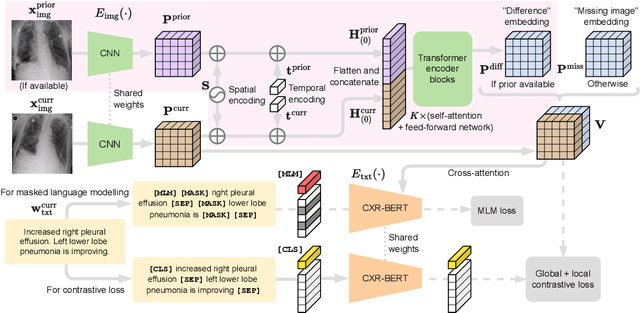
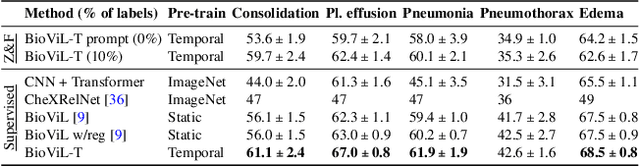
Self-supervised learning in vision-language processing exploits semantic alignment between imaging and text modalities. Prior work in biomedical VLP has mostly relied on the alignment of single image and report pairs even though clinical notes commonly refer to prior images. This does not only introduce poor alignment between the modalities but also a missed opportunity to exploit rich self-supervision through existing temporal content in the data. In this work, we explicitly account for prior images and reports when available during both training and fine-tuning. Our approach, named BioViL-T, uses a CNN-Transformer hybrid multi-image encoder trained jointly with a text model. It is designed to be versatile to arising challenges such as pose variations and missing input images across time. The resulting model excels on downstream tasks both in single- and multi-image setups, achieving state-of-the-art performance on (I) progression classification, (II) phrase grounding, and (III) report generation, whilst offering consistent improvements on disease classification and sentence-similarity tasks. We release a novel multi-modal temporal benchmark dataset, MS-CXR-T, to quantify the quality of vision-language representations in terms of temporal semantics. Our experimental results show the advantages of incorporating prior images and reports to make most use of the data.