 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKepeng Xu
Beyond Alignment: Blind Video Face Restoration via Parsing-Guided Temporal-Coherent Transformer
Apr 21, 2024
Multiple complex degradations are coupled in low-quality video faces in the real world. Therefore, blind video face restoration is a highly challenging ill-posed problem, requiring not only hallucinating high-fidelity details but also enhancing temporal coherence across diverse pose variations. Restoring each frame independently in a naive manner inevitably introduces temporal incoherence and artifacts from pose changes and keypoint localization errors. To address this, we propose the first blind video face restoration approach with a novel parsing-guided temporal-coherent transformer (PGTFormer) without pre-alignment. PGTFormer leverages semantic parsing guidance to select optimal face priors for generating temporally coherent artifact-free results. Specifically, we pre-train a temporal-spatial vector quantized auto-encoder on high-quality video face datasets to extract expressive context-rich priors. Then, the temporal parse-guided codebook predictor (TPCP) restores faces in different poses based on face parsing context cues without performing face pre-alignment. This strategy reduces artifacts and mitigates jitter caused by cumulative errors from face pre-alignment. Finally, the temporal fidelity regulator (TFR) enhances fidelity through temporal feature interaction and improves video temporal consistency. Extensive experiments on face videos show that our method outperforms previous face restoration baselines. The code will be released on \href{https://github.com/kepengxu/PGTFormer}{https://github.com/kepengxu/PGTFormer}.
Towards Robust SDRTV-to-HDRTV via Dual Inverse Degradation Network
Jul 07, 2023
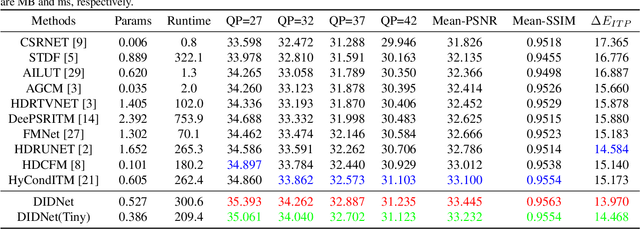

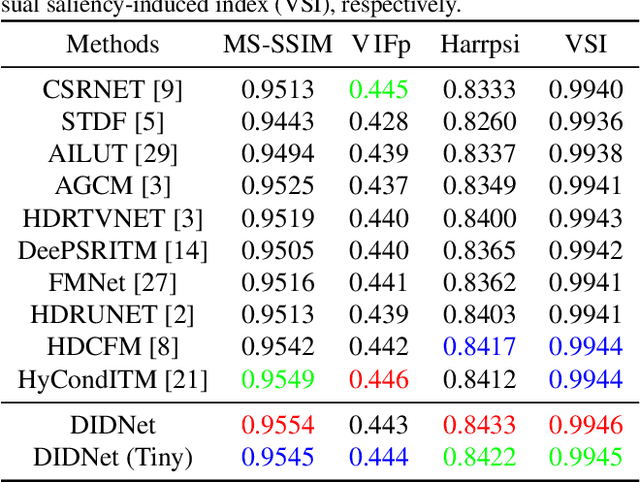
Recently, the transformation of standard dynamic range TV (SDRTV) to high dynamic range TV (HDRTV) is in high demand due to the scarcity of HDRTV content. However, the conversion of SDRTV to HDRTV often amplifies the existing coding artifacts in SDRTV which deteriorate the visual quality of the output. In this study, we propose a dual inverse degradation SDRTV-to-HDRTV network DIDNet to address the issue of coding artifact restoration in converted HDRTV, which has not been previously studied. Specifically, we propose a temporal-spatial feature alignment module and dual modulation convolution to remove coding artifacts and enhance color restoration ability. Furthermore, a wavelet attention module is proposed to improve SDRTV features in the frequency domain. An auxiliary loss is introduced to decouple the learning process for effectively restoring from dual degradation. The proposed method outperforms the current state-of-the-art method in terms of quantitative results, visual quality, and inference times, thus enhancing the performance of the SDRTV-to-HDRTV method in real-world scenarios.
SDRTV-to-HDRTV Conversion via Spatial-Temporal Feature Fusion
Nov 04, 2022



HDR(High Dynamic Range) video can reproduce realistic scenes more realistically, with a wider gamut and broader brightness range. HDR video resources are still scarce, and most videos are still stored in SDR (Standard Dynamic Range) format. Therefore, SDRTV-to-HDRTV Conversion (SDR video to HDR video) can significantly enhance the user's video viewing experience. Since the correlation between adjacent video frames is very high, the method utilizing the information of multiple frames can improve the quality of the converted HDRTV. Therefore, we propose a multi-frame fusion neural network \textbf{DSLNet} for SDRTV to HDRTV conversion. We first propose a dynamic spatial-temporal feature alignment module \textbf{DMFA}, which can align and fuse multi-frame. Then a novel spatial-temporal feature modulation module \textbf{STFM}, STFM extracts spatial-temporal information of adjacent frames for more accurate feature modulation. Finally, we design a quality enhancement module \textbf{LKQE} with large kernels, which can enhance the quality of generated HDR videos. To evaluate the performance of the proposed method, we construct a corresponding multi-frame dataset using HDR video of the HDR10 standard to conduct a comprehensive evaluation of different methods. The experimental results show that our method obtains state-of-the-art performance. The dataset and code will be released.