 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKeyon Vafa
Revisiting Topic-Guided Language Models
Dec 04, 2023
A recent line of work in natural language processing has aimed to combine language models and topic models. These topic-guided language models augment neural language models with topic models, unsupervised learning methods that can discover document-level patterns of word use. This paper compares the effectiveness of these methods in a standardized setting. We study four topic-guided language models and two baselines, evaluating the held-out predictive performance of each model on four corpora. Surprisingly, we find that none of these methods outperform a standard LSTM language model baseline, and most fail to learn good topics. Further, we train a probe of the neural language model that shows that the baseline's hidden states already encode topic information. We make public all code used for this study.
An Invariant Learning Characterization of Controlled Text Generation
May 31, 2023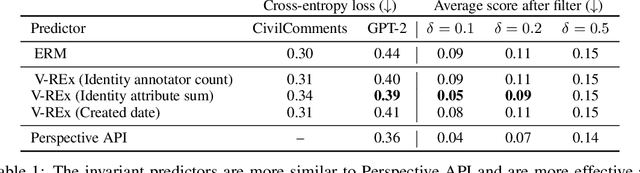
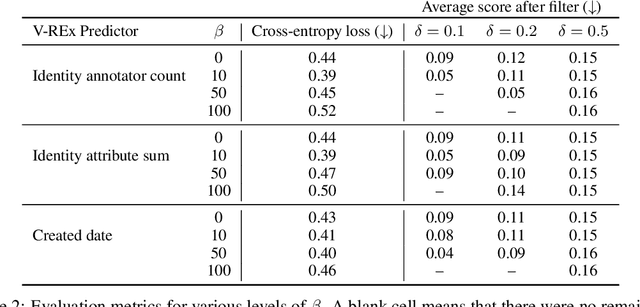
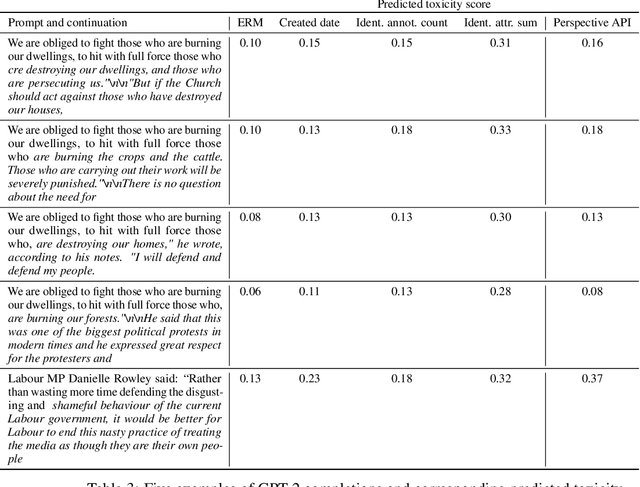
Controlled generation refers to the problem of creating text that contains stylistic or semantic attributes of interest. Many approaches reduce this problem to training a predictor of the desired attribute. For example, researchers hoping to deploy a large language model to produce non-toxic content may use a toxicity classifier to filter generated text. In practice, the generated text to classify, which is determined by user prompts, may come from a wide range of distributions. In this paper, we show that the performance of controlled generation may be poor if the distributions of text in response to user prompts differ from the distribution the predictor was trained on. To address this problem, we cast controlled generation under distribution shift as an invariant learning problem: the most effective predictor should be invariant across multiple text environments. We then discuss a natural solution that arises from this characterization and propose heuristics for selecting natural environments. We study this characterization and the proposed method empirically using both synthetic and real data. Experiments demonstrate both the challenge of distribution shift in controlled generation and the potential of invariance methods in this setting.
Learning Transferrable Representations of Career Trajectories for Economic Prediction
Mar 10, 2022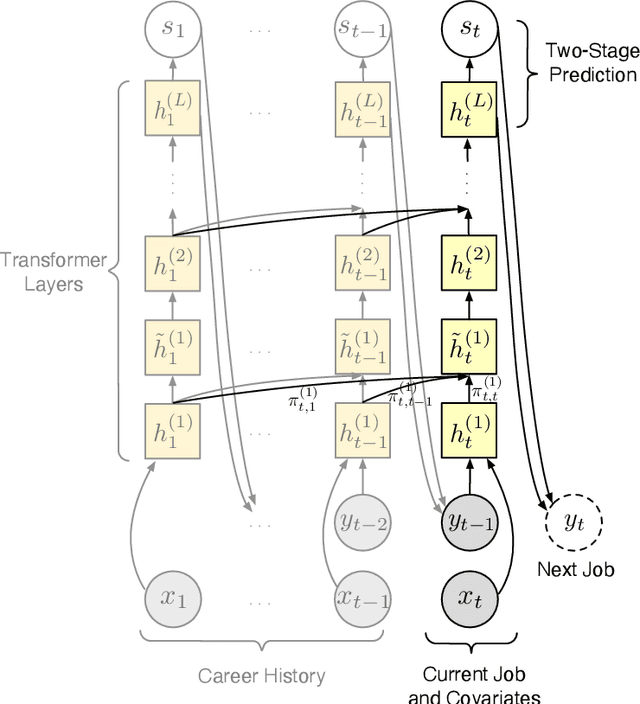
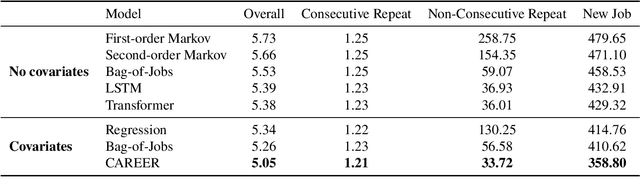

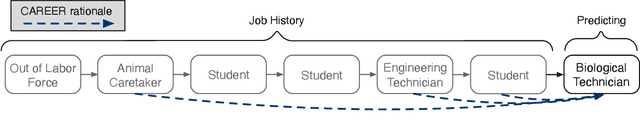
Understanding career trajectories -- the sequences of jobs that individuals hold over their working lives -- is important to economists for studying labor markets. In the past, economists have estimated relevant quantities by fitting predictive models to small surveys, but in recent years large datasets of online resumes have also become available. These new datasets provide job sequences of many more individuals, but they are too large and complex for standard econometric modeling. To this end, we adapt ideas from modern language modeling to the analysis of large-scale job sequence data. We develop CAREER, a transformer-based model that learns a low-dimensional representation of an individual's job history. This representation can be used to predict jobs directly on a large dataset, or can be "transferred" to represent jobs in smaller and better-curated datasets. We fit the model to a large dataset of resumes, 24 million people who are involved in more than a thousand unique occupations. It forms accurate predictions on held-out data, and it learns useful career representations that can be fine-tuned to make accurate predictions on common economics datasets.
Rationales for Sequential Predictions
Sep 14, 2021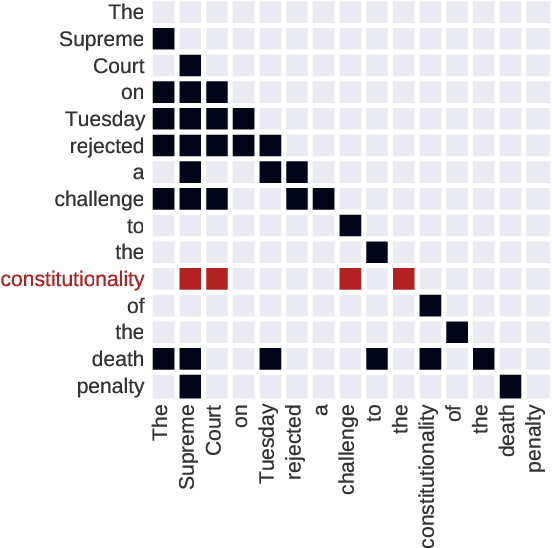



Sequence models are a critical component of modern NLP systems, but their predictions are difficult to explain. We consider model explanations though rationales, subsets of context that can explain individual model predictions. We find sequential rationales by solving a combinatorial optimization: the best rationale is the smallest subset of input tokens that would predict the same output as the full sequence. Enumerating all subsets is intractable, so we propose an efficient greedy algorithm to approximate this objective. The algorithm, which is called greedy rationalization, applies to any model. For this approach to be effective, the model should form compatible conditional distributions when making predictions on incomplete subsets of the context. This condition can be enforced with a short fine-tuning step. We study greedy rationalization on language modeling and machine translation. Compared to existing baselines, greedy rationalization is best at optimizing the combinatorial objective and provides the most faithful rationales. On a new dataset of annotated sequential rationales, greedy rationales are most similar to human rationales.
Text-Based Ideal Points
May 08, 2020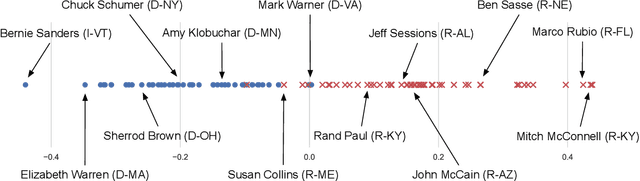

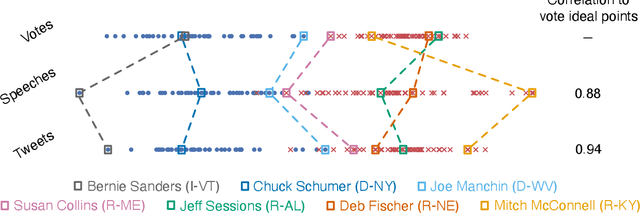
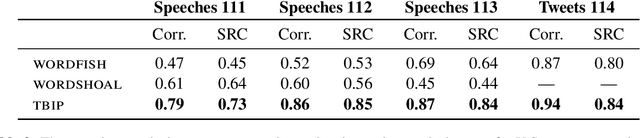
Ideal point models analyze lawmakers' votes to quantify their political positions, or ideal points. But votes are not the only way to express a political position. Lawmakers also give speeches, release press statements, and post tweets. In this paper, we introduce the text-based ideal point model (TBIP), an unsupervised probabilistic topic model that analyzes texts to quantify the political positions of its authors. We demonstrate the TBIP with two types of politicized text data: U.S. Senate speeches and senator tweets. Though the model does not analyze their votes or political affiliations, the TBIP separates lawmakers by party, learns interpretable politicized topics, and infers ideal points close to the classical vote-based ideal points. One benefit of analyzing texts, as opposed to votes, is that the TBIP can estimate ideal points of anyone who authors political texts, including non-voting actors. To this end, we use it to study tweets from the 2020 Democratic presidential candidates. Using only the texts of their tweets, it identifies them along an interpretable progressive-to-moderate spectrum.
Discrete Flows: Invertible Generative Models of Discrete Data
May 24, 2019

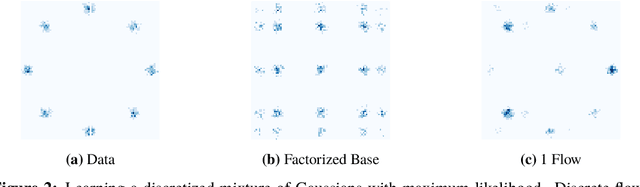
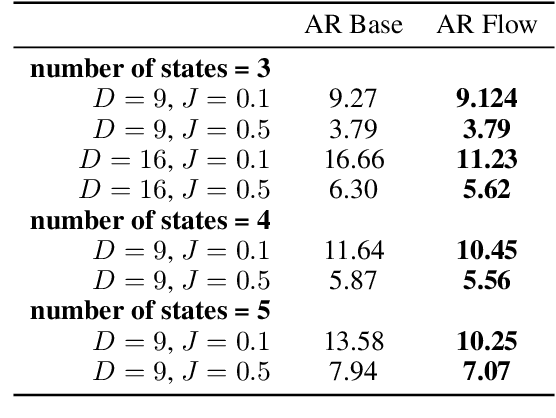
While normalizing flows have led to significant advances in modeling high-dimensional continuous distributions, their applicability to discrete distributions remains unknown. In this paper, we show that flows can in fact be extended to discrete events---and under a simple change-of-variables formula not requiring log-determinant-Jacobian computations. Discrete flows have numerous applications. We consider two flow architectures: discrete autoregressive flows that enable bidirectionality, allowing, for example, tokens in text to depend on both left-to-right and right-to-left contexts in an exact language model; and discrete bipartite flows that enable efficient non-autoregressive generation as in RealNVP. Empirically, we find that discrete autoregressive flows outperform autoregressive baselines on synthetic discrete distributions, an addition task, and Potts models; and bipartite flows can obtain competitive performance with autoregressive baselines on character-level language modeling for Penn Tree Bank and text8.