 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSusan Athey
Machine Learning Who to Nudge: Causal vs Predictive Targeting in a Field Experiment on Student Financial Aid Renewal
Oct 12, 2023


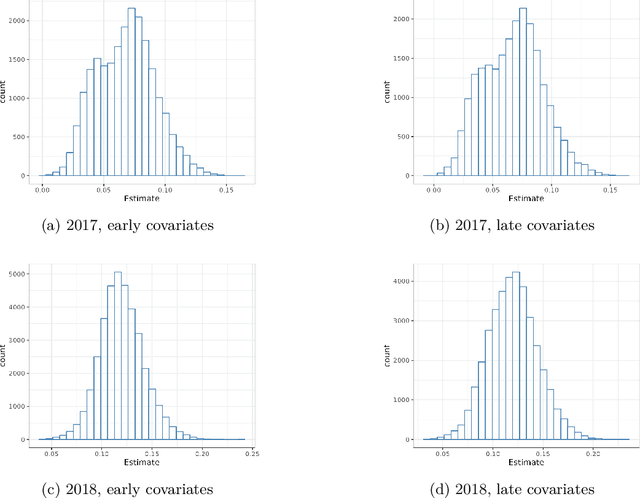
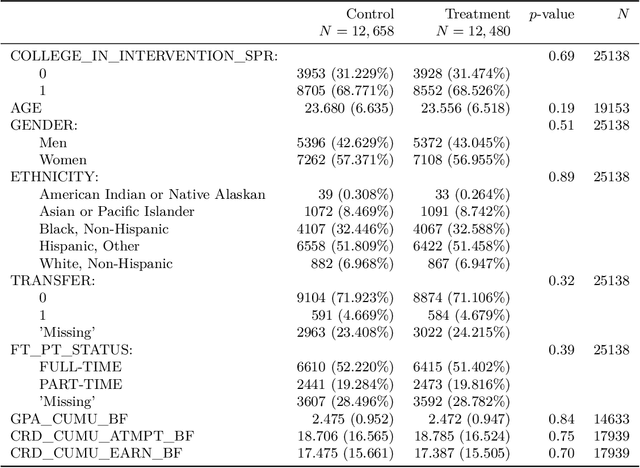
In many settings, interventions may be more effective for some individuals than others, so that targeting interventions may be beneficial. We analyze the value of targeting in the context of a large-scale field experiment with over 53,000 college students, where the goal was to use "nudges" to encourage students to renew their financial-aid applications before a non-binding deadline. We begin with baseline approaches to targeting. First, we target based on a causal forest that estimates heterogeneous treatment effects and then assigns students to treatment according to those estimated to have the highest treatment effects. Next, we evaluate two alternative targeting policies, one targeting students with low predicted probability of renewing financial aid in the absence of the treatment, the other targeting those with high probability. The predicted baseline outcome is not the ideal criterion for targeting, nor is it a priori clear whether to prioritize low, high, or intermediate predicted probability. Nonetheless, targeting on low baseline outcomes is common in practice, for example because the relationship between individual characteristics and treatment effects is often difficult or impossible to estimate with historical data. We propose hybrid approaches that incorporate the strengths of both predictive approaches (accurate estimation) and causal approaches (correct criterion); we show that targeting intermediate baseline outcomes is most effective, while targeting based on low baseline outcomes is detrimental. In one year of the experiment, nudging all students improved early filing by an average of 6.4 percentage points over a baseline average of 37% filing, and we estimate that targeting half of the students using our preferred policy attains around 75% of this benefit.
Proportional Response: Contextual Bandits for Simple and Cumulative Regret Minimization
Jul 05, 2023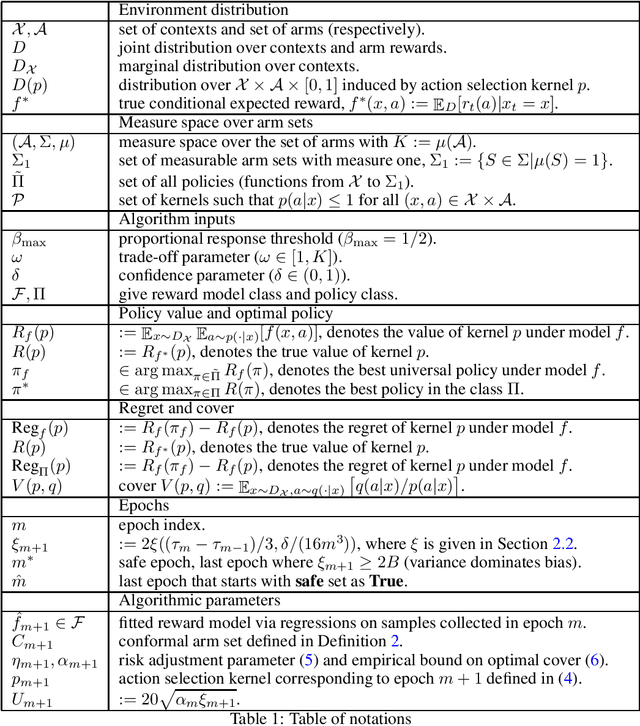
Simple regret minimization is a critical problem in learning optimal treatment assignment policies across various domains, including healthcare and e-commerce. However, it remains understudied in the contextual bandit setting. We propose a new family of computationally efficient bandit algorithms for the stochastic contextual bandit settings, with the flexibility to be adapted for cumulative regret minimization (with near-optimal minimax guarantees) and simple regret minimization (with SOTA guarantees). Furthermore, our algorithms adapt to model misspecification and extend to the continuous arm settings. These advantages come from constructing and relying on "conformal arm sets" (CASs), which provide a set of arms at every context that encompass the context-specific optimal arm with some probability across the context distribution. Our positive results on simple and cumulative regret guarantees are contrasted by a negative result, which shows that an algorithm can't achieve instance-dependent simple regret guarantees while simultaneously achieving minimax optimal cumulative regret guarantees.
Federated Offline Policy Learning with Heterogeneous Observational Data
May 21, 2023


We consider the problem of learning personalized decision policies on observational data from heterogeneous data sources. Moreover, we examine this problem in the federated setting where a central server aims to learn a policy on the data distributed across the heterogeneous sources without exchanging their raw data. We present a federated policy learning algorithm based on aggregation of local policies trained with doubly robust offline policy evaluation and learning strategies. We provide a novel regret analysis for our approach that establishes a finite-sample upper bound on a notion of global regret across a distribution of clients. In addition, for any individual client, we establish a corresponding local regret upper bound characterized by the presence of distribution shift relative to all other clients. We support our theoretical findings with experimental results. Our analysis and experiments provide insights into the value of heterogeneous client participation in federation for policy learning in heterogeneous settings.
Torch-Choice: A PyTorch Package for Large-Scale Choice Modelling with Python
Apr 04, 2023
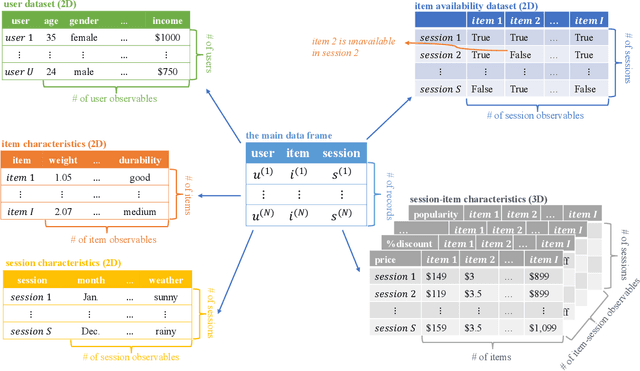


The $\texttt{torch-choice}$ is an open-source library for flexible, fast choice modeling with Python and PyTorch. $\texttt{torch-choice}$ provides a $\texttt{ChoiceDataset}$ data structure to manage databases flexibly and memory-efficiently. The paper demonstrates constructing a $\texttt{ChoiceDataset}$ from databases of various formats and functionalities of $\texttt{ChoiceDataset}$. The package implements two widely used models, namely the multinomial logit and nested logit models, and supports regularization during model estimation. The package incorporates the option to take advantage of GPUs for estimation, allowing it to scale to massive datasets while being computationally efficient. Models can be initialized using either R-style formula strings or Python dictionaries. We conclude with a comparison of the computational efficiencies of $\texttt{torch-choice}$ and $\texttt{mlogit}$ in R as (1) the number of observations increases, (2) the number of covariates increases, and (3) the expansion of item sets. Finally, we demonstrate the scalability of $\texttt{torch-choice}$ on large-scale datasets.
Contextual Bandits in a Survey Experiment on Charitable Giving: Within-Experiment Outcomes versus Policy Learning
Nov 22, 2022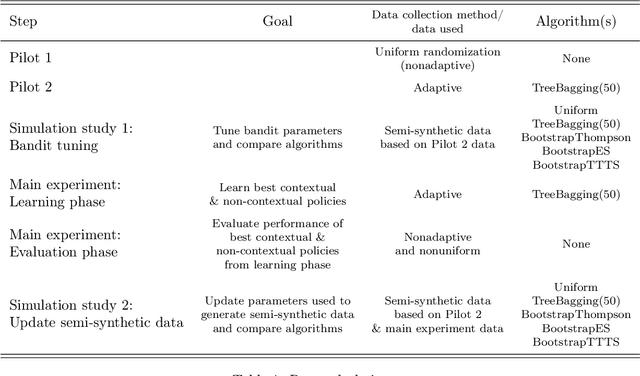
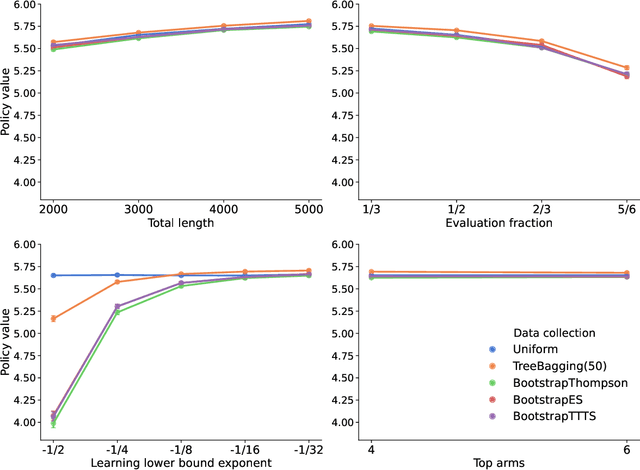

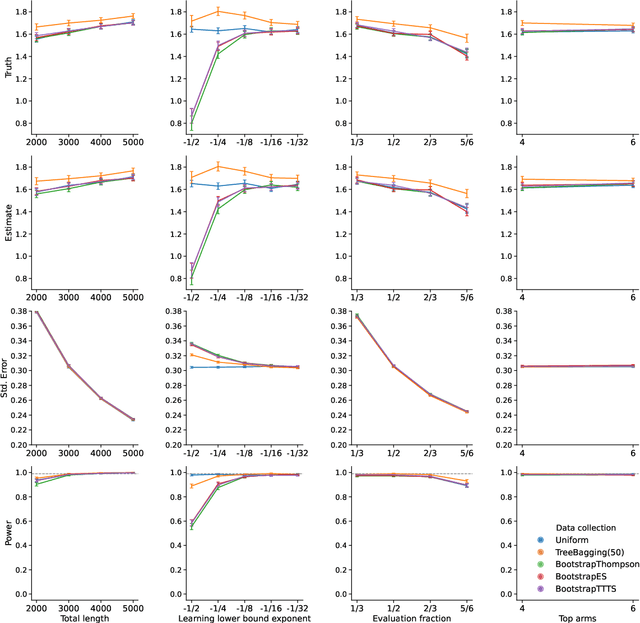
We design and implement an adaptive experiment (a ``contextual bandit'') to learn a targeted treatment assignment policy, where the goal is to use a participant's survey responses to determine which charity to expose them to in a donation solicitation. The design balances two competing objectives: optimizing the outcomes for the subjects in the experiment (``cumulative regret minimization'') and gathering data that will be most useful for policy learning, that is, for learning an assignment rule that will maximize welfare if used after the experiment (``simple regret minimization''). We evaluate alternative experimental designs by collecting pilot data and then conducting a simulation study. Next, we implement our selected algorithm. Finally, we perform a second simulation study anchored to the collected data that evaluates the benefits of the algorithm we chose. Our first result is that the value of a learned policy in this setting is higher when data is collected via a uniform randomization rather than collected adaptively using standard cumulative regret minimization or policy learning algorithms. We propose a simple heuristic for adaptive experimentation that improves upon uniform randomization from the perspective of policy learning at the expense of increasing cumulative regret relative to alternative bandit algorithms. The heuristic modifies an existing contextual bandit algorithm by (i) imposing a lower bound on assignment probabilities that decay slowly so that no arm is discarded too quickly, and (ii) after adaptively collecting data, restricting policy learning to select from arms where sufficient data has been gathered.
Flexible and Efficient Contextual Bandits with Heterogeneous Treatment Effect Oracle
Mar 30, 2022
Many popular contextual bandit algorithms estimate reward models to inform decision making. However, true rewards can contain action-independent redundancies that are not relevant for decision making and only increase the statistical complexity of accurate estimation. It is sufficient and more data-efficient to estimate the simplest function that explains the reward differences between actions, that is, the heterogeneous treatment effect, commonly understood to be more structured and simpler than the reward. Motivated by this observation, building on recent work on oracle-based algorithms, we design a statistically optimal and computationally efficient algorithm using heterogeneous treatment effect estimation oracles. Our results provide the first universal reduction of contextual bandits to a general-purpose heterogeneous treatment effect estimation method. We show that our approach is more robust to model misspecification than reward estimation methods based on squared error regression oracles. Experimentally, we show the benefits of heterogeneous treatment effect estimation in contextual bandits over reward estimation.
Learning Transferrable Representations of Career Trajectories for Economic Prediction
Mar 10, 2022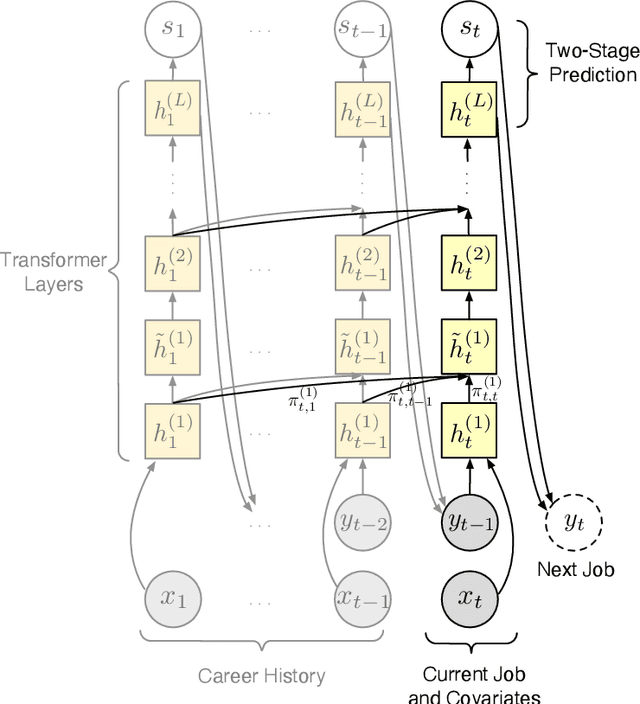
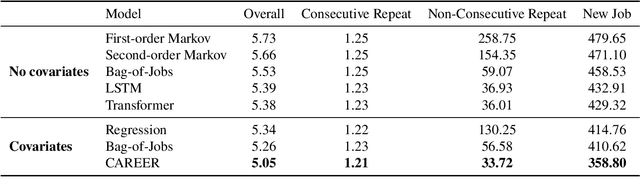

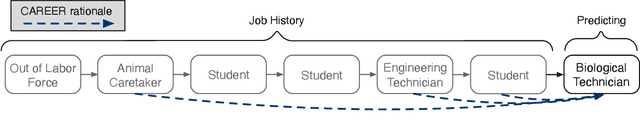
Understanding career trajectories -- the sequences of jobs that individuals hold over their working lives -- is important to economists for studying labor markets. In the past, economists have estimated relevant quantities by fitting predictive models to small surveys, but in recent years large datasets of online resumes have also become available. These new datasets provide job sequences of many more individuals, but they are too large and complex for standard econometric modeling. To this end, we adapt ideas from modern language modeling to the analysis of large-scale job sequence data. We develop CAREER, a transformer-based model that learns a low-dimensional representation of an individual's job history. This representation can be used to predict jobs directly on a large dataset, or can be "transferred" to represent jobs in smaller and better-curated datasets. We fit the model to a large dataset of resumes, 24 million people who are involved in more than a thousand unique occupations. It forms accurate predictions on held-out data, and it learns useful career representations that can be fine-tuned to make accurate predictions on common economics datasets.
Federated Causal Inference in Heterogeneous Observational Data
Aug 10, 2021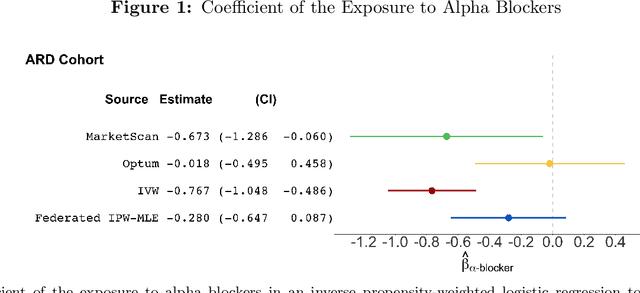



Analyzing observational data from multiple sources can be useful for increasing statistical power to detect a treatment effect; however, practical constraints such as privacy considerations may restrict individual-level information sharing across data sets. This paper develops federated methods that only utilize summary-level information from heterogeneous data sets. Our federated methods provide doubly-robust point estimates of treatment effects as well as variance estimates. We derive the asymptotic distributions of our federated estimators, which are shown to be asymptotically equivalent to the corresponding estimators from the combined, individual-level data. We show that to achieve these properties, federated methods should be adjusted based on conditions such as whether models are correctly specified and stable across heterogeneous data sets.
Optimal Model Selection in Contextual Bandits with Many Classes via Offline Oracles
Jun 11, 2021We study the problem of model selection for contextual bandits, in which the algorithm must balance the bias-variance trade-off for model estimation while also balancing the exploration-exploitation trade-off. In this paper, we propose the first reduction of model selection in contextual bandits to offline model selection oracles, allowing for flexible general purpose algorithms with computational requirements no worse than those for model selection for regression. Our main result is a new model selection guarantee for stochastic contextual bandits. When one of the classes in our set is realizable, up to a logarithmic dependency on the number of classes, our algorithm attains optimal realizability-based regret bounds for that class under one of two conditions: if the time-horizon is large enough, or if an assumption that helps with detecting misspecification holds. Hence our algorithm adapts to the complexity of this unknown class. Even when this realizable class is known, we prove improved regret guarantees in early rounds by relying on simpler model classes for those rounds and hence further establish the importance of model selection in contextual bandits.
Off-Policy Evaluation via Adaptive Weighting with Data from Contextual Bandits
Jun 10, 2021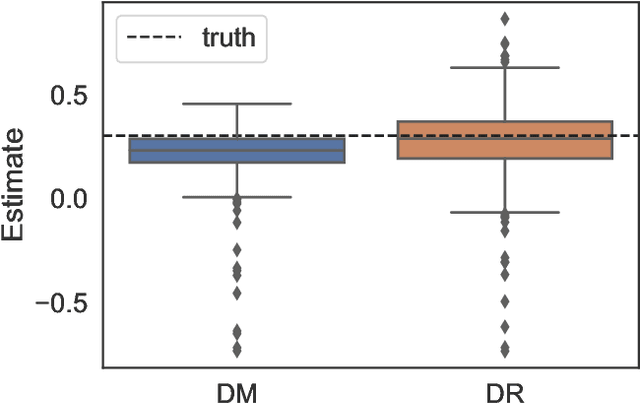


It has become increasingly common for data to be collected adaptively, for example using contextual bandits. Historical data of this type can be used to evaluate other treatment assignment policies to guide future innovation or experiments. However, policy evaluation is challenging if the target policy differs from the one used to collect data, and popular estimators, including doubly robust (DR) estimators, can be plagued by bias, excessive variance, or both. In particular, when the pattern of treatment assignment in the collected data looks little like the pattern generated by the policy to be evaluated, the importance weights used in DR estimators explode, leading to excessive variance. In this paper, we improve the DR estimator by adaptively weighting observations to control its variance. We show that a t-statistic based on our improved estimator is asymptotically normal under certain conditions, allowing us to form confidence intervals and test hypotheses. Using synthetic data and public benchmarks, we provide empirical evidence for our estimator's improved accuracy and inferential properties relative to existing alternatives.