 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRuoxuan Xiong
Contrastive Balancing Representation Learning for Heterogeneous Dose-Response Curves Estimation
Mar 21, 2024
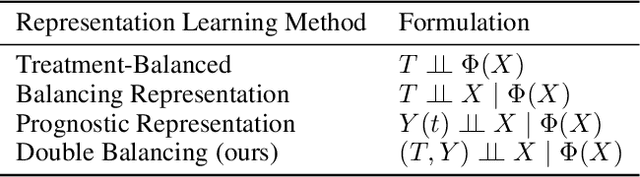
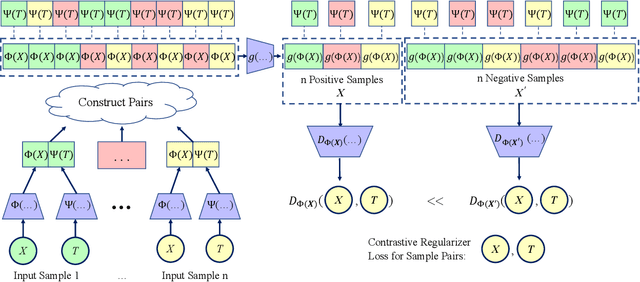
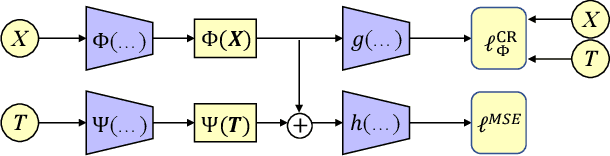
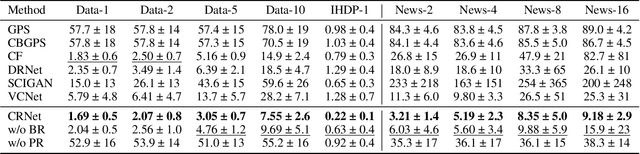
Estimating the individuals' potential response to varying treatment doses is crucial for decision-making in areas such as precision medicine and management science. Most recent studies predict counterfactual outcomes by learning a covariate representation that is independent of the treatment variable. However, such independence constraints neglect much of the covariate information that is useful for counterfactual prediction, especially when the treatment variables are continuous. To tackle the above issue, in this paper, we first theoretically demonstrate the importance of the balancing and prognostic representations for unbiased estimation of the heterogeneous dose-response curves, that is, the learned representations are constrained to satisfy the conditional independence between the covariates and both of the treatment variables and the potential responses. Based on this, we propose a novel Contrastive balancing Representation learning Network using a partial distance measure, called CRNet, for estimating the heterogeneous dose-response curves without losing the continuity of treatments. Extensive experiments are conducted on synthetic and real-world datasets demonstrating that our proposal significantly outperforms previous methods.
Pareto-Optimal Estimation and Policy Learning on Short-term and Long-term Treatment Effects
Mar 12, 2024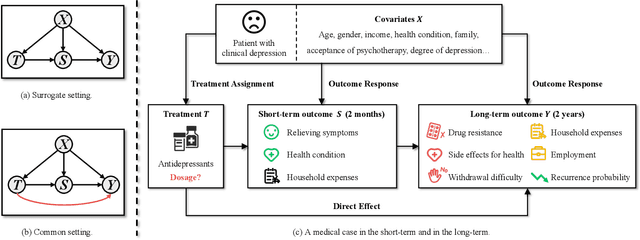
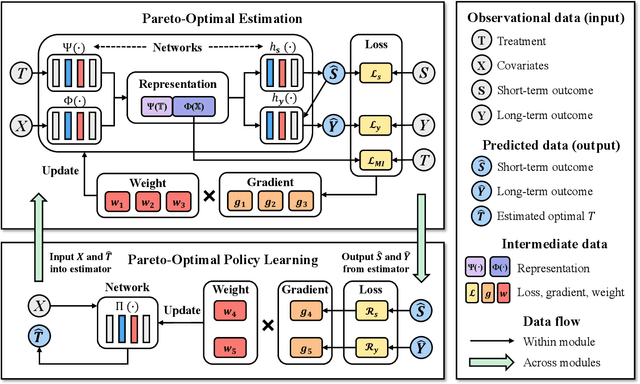
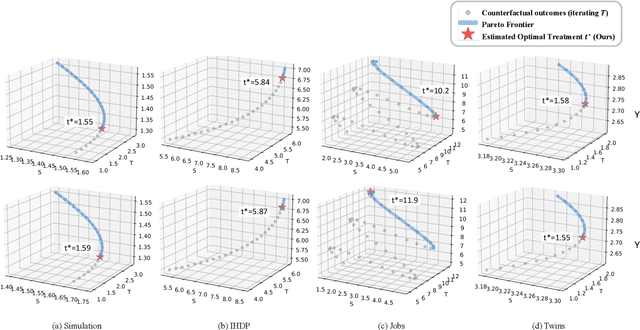
This paper focuses on developing Pareto-optimal estimation and policy learning to identify the most effective treatment that maximizes the total reward from both short-term and long-term effects, which might conflict with each other. For example, a higher dosage of medication might increase the speed of a patient's recovery (short-term) but could also result in severe long-term side effects. Although recent works have investigated the problems about short-term or long-term effects or the both, how to trade-off between them to achieve optimal treatment remains an open challenge. Moreover, when multiple objectives are directly estimated using conventional causal representation learning, the optimization directions among various tasks can conflict as well. In this paper, we systematically investigate these issues and introduce a Pareto-Efficient algorithm, comprising Pareto-Optimal Estimation (POE) and Pareto-Optimal Policy Learning (POPL), to tackle them. POE incorporates a continuous Pareto module with representation balancing, enhancing estimation efficiency across multiple tasks. As for POPL, it involves deriving short-term and long-term outcomes linked with various treatment levels, facilitating an exploration of the Pareto frontier emanating from these outcomes. Results on both the synthetic and real-world datasets demonstrate the superiority of our method.
Instrumental Variables in Causal Inference and Machine Learning: A Survey
Dec 12, 2022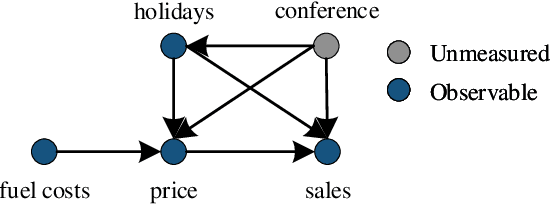

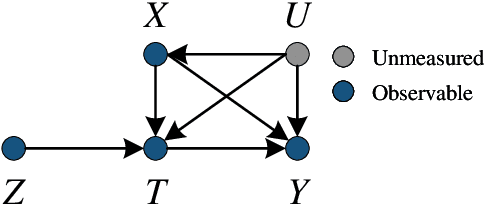
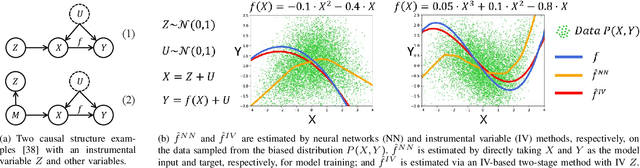
Causal inference is the process of using assumptions, study designs, and estimation strategies to draw conclusions about the causal relationships between variables based on data. This allows researchers to better understand the underlying mechanisms at work in complex systems and make more informed decisions. In many settings, we may not fully observe all the confounders that affect both the treatment and outcome variables, complicating the estimation of causal effects. To address this problem, a growing literature in both causal inference and machine learning proposes to use Instrumental Variables (IV). This paper serves as the first effort to systematically and comprehensively introduce and discuss the IV methods and their applications in both causal inference and machine learning. First, we provide the formal definition of IVs and discuss the identification problem of IV regression methods under different assumptions. Second, we categorize the existing work on IV methods into three streams according to the focus on the proposed methods, including two-stage least squares with IVs, control function with IVs, and evaluation of IVs. For each stream, we present both the classical causal inference methods, and recent developments in the machine learning literature. Then, we introduce a variety of applications of IV methods in real-world scenarios and provide a summary of the available datasets and algorithms. Finally, we summarize the literature, discuss the open problems and suggest promising future research directions for IV methods and their applications. We also develop a toolkit of IVs methods reviewed in this survey at https://github.com/causal-machine-learning-lab/mliv.
Confounder Balancing for Instrumental Variable Regression with Latent Variable
Nov 18, 2022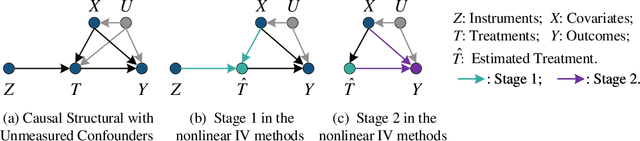
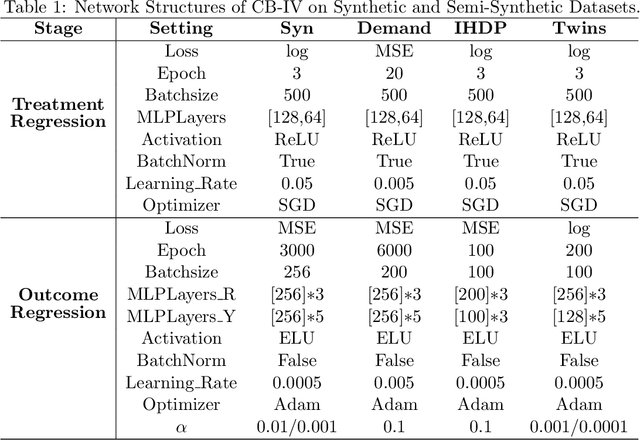
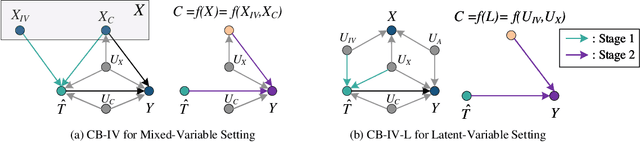
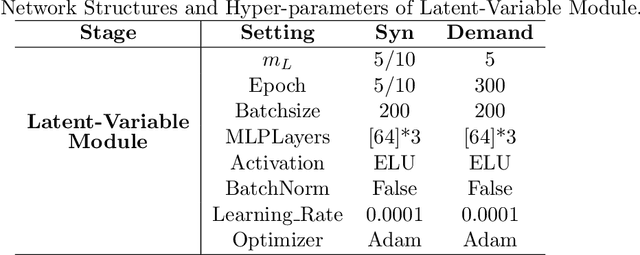
This paper studies the confounding effects from the unmeasured confounders and the imbalance of observed confounders in IV regression and aims at unbiased causal effect estimation. Recently, nonlinear IV estimators were proposed to allow for nonlinear model in both stages. However, the observed confounders may be imbalanced in stage 2, which could still lead to biased treatment effect estimation in certain cases. To this end, we propose a Confounder Balanced IV Regression (CB-IV) algorithm to jointly remove the bias from the unmeasured confounders and the imbalance of observed confounders. Theoretically, by redefining and solving an inverse problem for potential outcome function, we show that our CB-IV algorithm can unbiasedly estimate treatment effects and achieve lower variance. The IV methods have a major disadvantage in that little prior or theory is currently available to pre-define a valid IV in real-world scenarios. Thus, we study two more challenging settings without pre-defined valid IVs: (1) indistinguishable IVs implicitly present in observations, i.e., mixed-variable challenge, and (2) latent IVs don't appear in observations, i.e., latent-variable challenge. To address these two challenges, we extend our CB-IV by a latent-variable module, namely CB-IV-L algorithm. Extensive experiments demonstrate that our CB-IV(-L) outperforms the existing approaches.
Learning Individual Treatment Effects under Heterogeneous Interference in Networks
Oct 25, 2022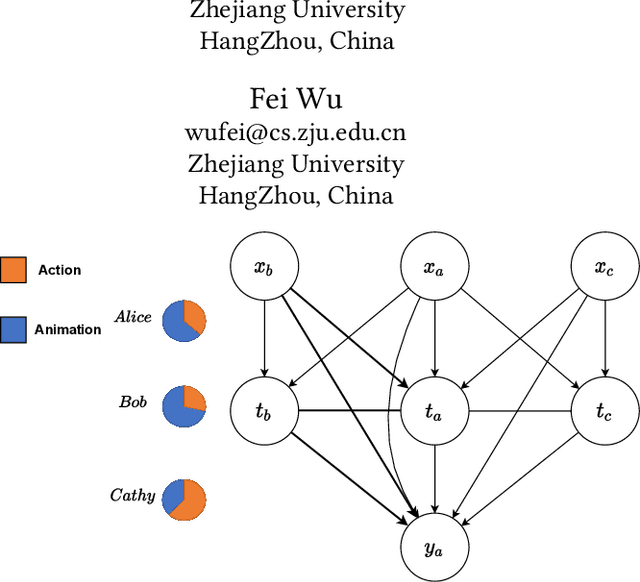
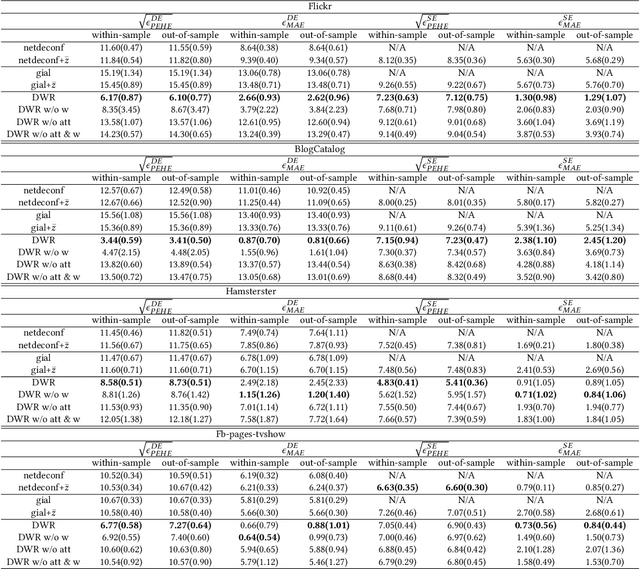
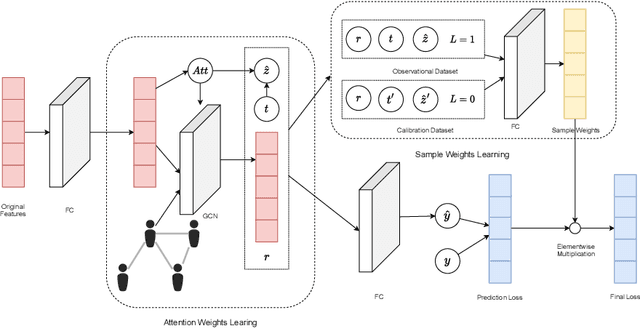
Estimates of individual treatment effects from networked observational data are attracting increasing attention these days. One major challenge in network scenarios is the violation of the stable unit treatment value assumption (SUTVA), which assumes that the treatment assignment of a unit does not influence others' outcomes. In network data, due to interference, the outcome of a unit is influenced not only by its treatment (i.e., direct effects) but also by others' treatments (i.e., spillover effects). Furthermore, the influences from other units are always heterogeneous (e.g., friends with similar interests affect a person differently than friends with different interests). In this paper, we focus on the problem of estimating individual treatment effects (both direct and spillover effects) under heterogeneous interference. To address this issue, we propose a novel Dual Weighting Regression (DWR) algorithm by simultaneously learning attention weights that capture the heterogeneous interference and sample weights to eliminate the complex confounding bias in networks. We formulate the entire learning process as a bi-level optimization problem. In theory, we present generalization error bounds for individual treatment effect estimation. Extensive experiments on four benchmark datasets demonstrate that the proposed DWR algorithm outperforms state-of-the-art methods for estimating individual treatment effects under heterogeneous interference.
Treatment Effect Estimation with Unmeasured Confounders in Data Fusion
Aug 23, 2022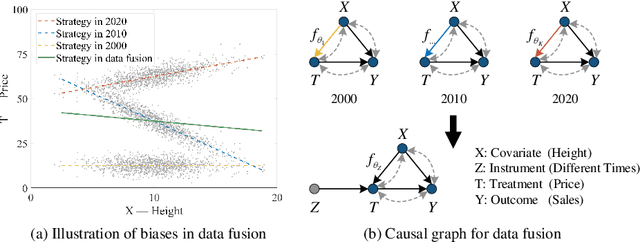
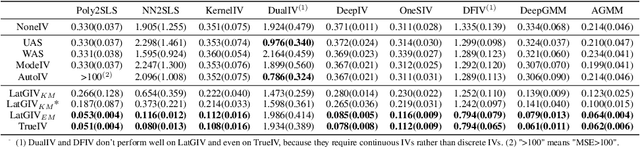
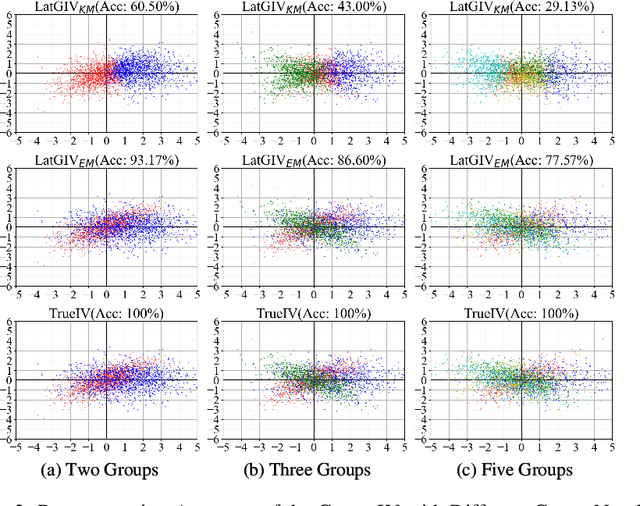

In the presence of unmeasured confounders, we address the problem of treatment effect estimation from data fusion, that is, multiple datasets collected under different treatment assignment mechanisms. For example, marketers may assign different advertising strategies to the same products at different times/places. To handle the bias induced by unmeasured confounders and data fusion, we propose to separate the observational data into multiple groups (each group with an independent treatment assignment mechanism), and then explicitly model the group indicator as a Latent Group Instrumental Variable (LatGIV) to implement IV-based Regression. In this paper, we conceptualize this line of thought and develop a unified framework to (1) estimate the distribution differences of observed variables across groups; (2) model the LatGIVs from the different treatment assignment mechanisms; and (3) plug LatGIVs to estimate the treatment-response function. Empirical results demonstrate the advantages of the LatGIV compared with state-of-the-art methods.
Learning Domain-Invariant Relationship with Instrumental Variable for Domain Generalization
Oct 04, 2021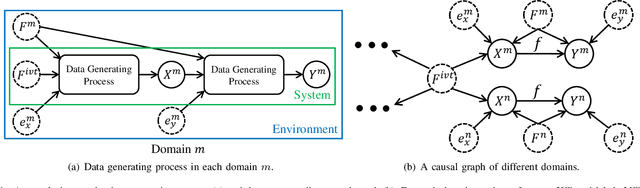
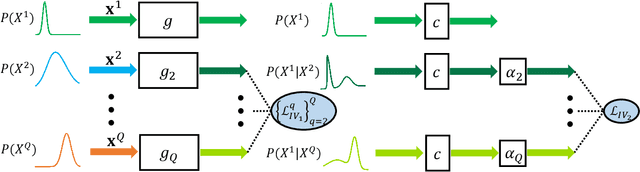
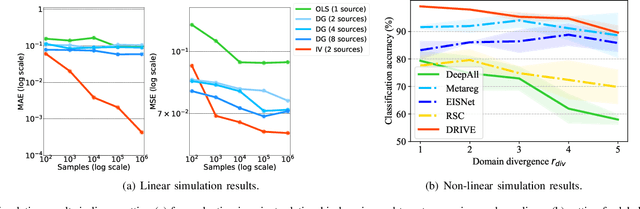
Domain generalization (DG) aims to learn from multiple source domains a model that generalizes well on unseen target domains. Existing methods mainly learn input feature representations with invariant marginal distribution, while the invariance of the conditional distribution is more essential for unknown domain generalization. This paper proposes an instrumental variable-based approach to learn the domain-invariant relationship between input features and labels contained in the conditional distribution. Interestingly, with a causal view on the data generating process, we find that the input features of one domain are valid instrumental variables for other domains. Inspired by this finding, we design a simple yet effective framework to learn the Domain-invariant Relationship with Instrumental VariablE (DRIVE) via a two-stage IV method. Specifically, it first learns the conditional distribution of input features of one domain given input features of another domain, and then it estimates the domain-invariant relationship by predicting labels with the learned conditional distribution. Simulation experiments show the proposed method accurately captures the domain-invariant relationship. Extensive experiments on several datasets consistently demonstrate that DRIVE yields state-of-the-art results.
Federated Causal Inference in Heterogeneous Observational Data
Aug 10, 2021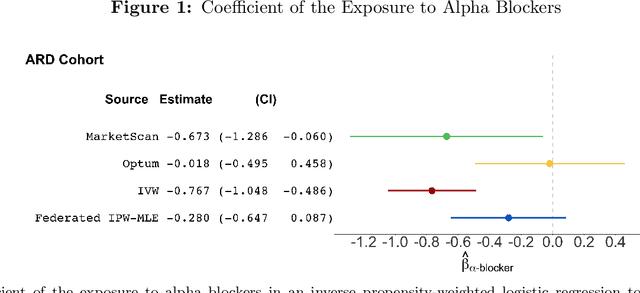



Analyzing observational data from multiple sources can be useful for increasing statistical power to detect a treatment effect; however, practical constraints such as privacy considerations may restrict individual-level information sharing across data sets. This paper develops federated methods that only utilize summary-level information from heterogeneous data sets. Our federated methods provide doubly-robust point estimates of treatment effects as well as variance estimates. We derive the asymptotic distributions of our federated estimators, which are shown to be asymptotically equivalent to the corresponding estimators from the combined, individual-level data. We show that to achieve these properties, federated methods should be adjusted based on conditions such as whether models are correctly specified and stable across heterogeneous data sets.
Stable Prediction with Model Misspecification and Agnostic Distribution Shift
Jan 31, 2020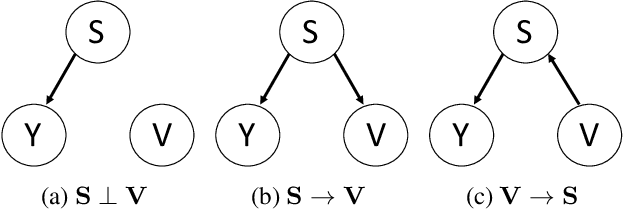
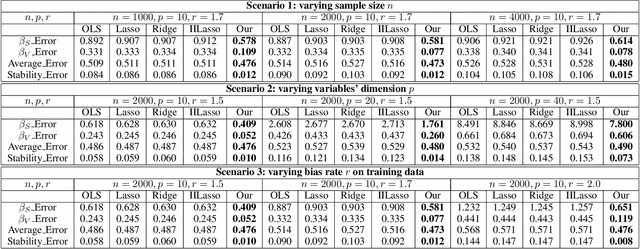
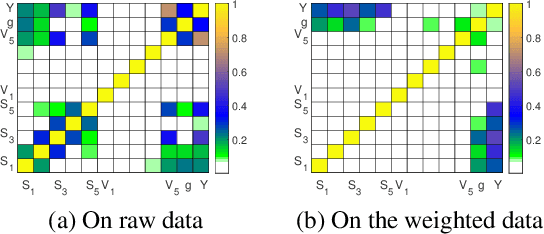
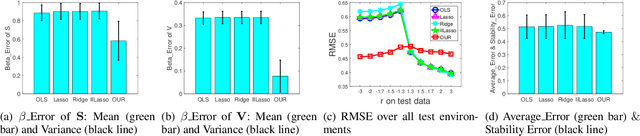
For many machine learning algorithms, two main assumptions are required to guarantee performance. One is that the test data are drawn from the same distribution as the training data, and the other is that the model is correctly specified. In real applications, however, we often have little prior knowledge on the test data and on the underlying true model. Under model misspecification, agnostic distribution shift between training and test data leads to inaccuracy of parameter estimation and instability of prediction across unknown test data. To address these problems, we propose a novel Decorrelated Weighting Regression (DWR) algorithm which jointly optimizes a variable decorrelation regularizer and a weighted regression model. The variable decorrelation regularizer estimates a weight for each sample such that variables are decorrelated on the weighted training data. Then, these weights are used in the weighted regression to improve the accuracy of estimation on the effect of each variable, thus help to improve the stability of prediction across unknown test data. Extensive experiments clearly demonstrate that our DWR algorithm can significantly improve the accuracy of parameter estimation and stability of prediction with model misspecification and agnostic distribution shift.
Optimal Experimental Design for Staggered Rollouts
Nov 09, 2019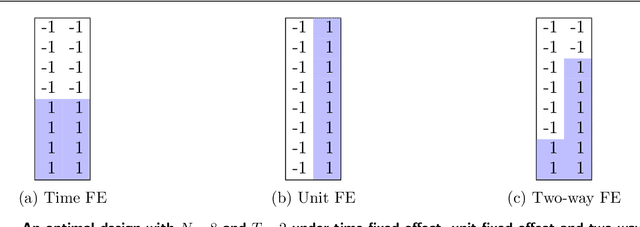

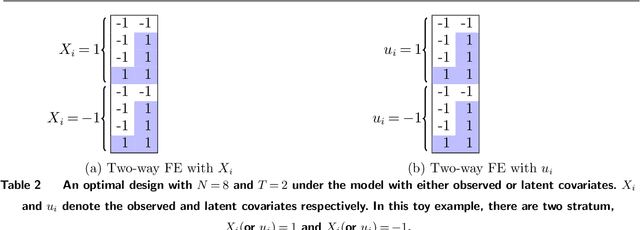

Experimentation has become an increasingly prevalent tool for guiding policy choices, firm decisions, and product innovation. A common hurdle in designing experiments is the lack of statistical power. In this paper, we study optimal multi-period experimental design under the constraint that the treatment cannot be easily removed once implemented; for example, a government or firm might implement treatment in different geographies at different times, where the treatment cannot be easily removed due to practical constraints. The design problem is to select which units to treat at which time, intending to test hypotheses about the effect of the treatment. When the potential outcome is a linear function of a unit effect, a time effect, and observed discrete covariates, we provide an analytically feasible solution to the design problem where the variance of the estimator for the treatment effect is at most 1+O(1/N^2) times the variance of the optimal design, where N is the number of units. This solution assigns units in a staggered treatment adoption pattern, where the proportion treated is a linear function of time. In the general setting where outcomes depend on latent covariates, we show that historical data can be utilized in the optimal design. We propose a data-driven local search algorithm with the minimax decision criterion to assign units to treatment times. We demonstrate that our approach improves upon benchmark experimental designs through synthetic experiments on real-world data sets from several domains, including healthcare, finance, and retail. Finally, we consider the case where the treatment effect changes with the time of treatment, showing that the optimal design treats a smaller fraction of units at the beginning and a greater share at the end.