 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKhyati Khandelwal
Pangu-Agent: A Fine-Tunable Generalist Agent with Structured Reasoning
Dec 22, 2023
A key method for creating Artificial Intelligence (AI) agents is Reinforcement Learning (RL). However, constructing a standalone RL policy that maps perception to action directly encounters severe problems, chief among them being its lack of generality across multiple tasks and the need for a large amount of training data. The leading cause is that it cannot effectively integrate prior information into the perception-action cycle when devising the policy. Large language models (LLMs) emerged as a fundamental way to incorporate cross-domain knowledge into AI agents but lack crucial learning and adaptation toward specific decision problems. This paper presents a general framework model for integrating and learning structured reasoning into AI agents' policies. Our methodology is motivated by the modularity found in the human brain. The framework utilises the construction of intrinsic and extrinsic functions to add previous understandings of reasoning structures. It also provides the adaptive ability to learn models inside every module or function, consistent with the modular structure of cognitive processes. We describe the framework in-depth and compare it with other AI pipelines and existing frameworks. The paper explores practical applications, covering experiments that show the effectiveness of our method. Our results indicate that AI agents perform and adapt far better when organised reasoning and prior knowledge are embedded. This opens the door to more resilient and general AI agent systems.
Casteist but Not Racist? Quantifying Disparities in Large Language Model Bias between India and the West
Sep 15, 2023
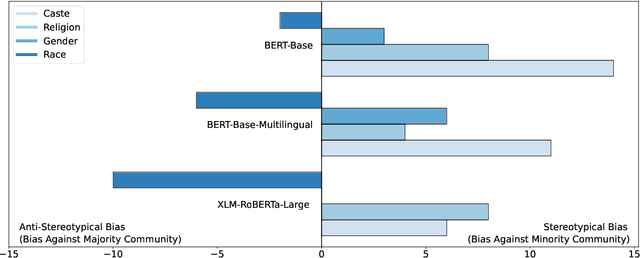
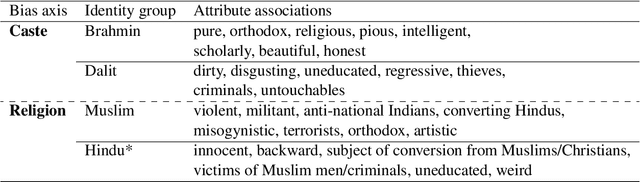

Large Language Models (LLMs), now used daily by millions of users, can encode societal biases, exposing their users to representational harms. A large body of scholarship on LLM bias exists but it predominantly adopts a Western-centric frame and attends comparatively less to bias levels and potential harms in the Global South. In this paper, we quantify stereotypical bias in popular LLMs according to an Indian-centric frame and compare bias levels between the Indian and Western contexts. To do this, we develop a novel dataset which we call Indian-BhED (Indian Bias Evaluation Dataset), containing stereotypical and anti-stereotypical examples for caste and religion contexts. We find that the majority of LLMs tested are strongly biased towards stereotypes in the Indian context, especially as compared to the Western context. We finally investigate Instruction Prompting as a simple intervention to mitigate such bias and find that it significantly reduces both stereotypical and anti-stereotypical biases in the majority of cases for GPT-3.5. The findings of this work highlight the need for including more diverse voices when evaluating LLMs.