 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMatthieu Zimmer
Distilling Morphology-Conditioned Hypernetworks for Efficient Universal Morphology Control
Feb 09, 2024
Learning a universal policy across different robot morphologies can significantly improve learning efficiency and enable zero-shot generalization to unseen morphologies. However, learning a highly performant universal policy requires sophisticated architectures like transformers (TF) that have larger memory and computational cost than simpler multi-layer perceptrons (MLP). To achieve both good performance like TF and high efficiency like MLP at inference time, we propose HyperDistill, which consists of: (1) A morphology-conditioned hypernetwork (HN) that generates robot-wise MLP policies, and (2) A policy distillation approach that is essential for successful training. We show that on UNIMAL, a benchmark with hundreds of diverse morphologies, HyperDistill performs as well as a universal TF teacher policy on both training and unseen test robots, but reduces model size by 6-14 times, and computational cost by 67-160 times in different environments. Our analysis attributes the efficiency advantage of HyperDistill at inference time to knowledge decoupling, i.e., the ability to decouple inter-task and intra-task knowledge, a general principle that could also be applied to improve inference efficiency in other domains.
Pangu-Agent: A Fine-Tunable Generalist Agent with Structured Reasoning
Dec 22, 2023A key method for creating Artificial Intelligence (AI) agents is Reinforcement Learning (RL). However, constructing a standalone RL policy that maps perception to action directly encounters severe problems, chief among them being its lack of generality across multiple tasks and the need for a large amount of training data. The leading cause is that it cannot effectively integrate prior information into the perception-action cycle when devising the policy. Large language models (LLMs) emerged as a fundamental way to incorporate cross-domain knowledge into AI agents but lack crucial learning and adaptation toward specific decision problems. This paper presents a general framework model for integrating and learning structured reasoning into AI agents' policies. Our methodology is motivated by the modularity found in the human brain. The framework utilises the construction of intrinsic and extrinsic functions to add previous understandings of reasoning structures. It also provides the adaptive ability to learn models inside every module or function, consistent with the modular structure of cognitive processes. We describe the framework in-depth and compare it with other AI pipelines and existing frameworks. The paper explores practical applications, covering experiments that show the effectiveness of our method. Our results indicate that AI agents perform and adapt far better when organised reasoning and prior knowledge are embedded. This opens the door to more resilient and general AI agent systems.
Automatic Unit Test Data Generation and Actor-Critic Reinforcement Learning for Code Synthesis
Oct 20, 2023The advent of large pre-trained language models in the domain of Code Synthesis has shown remarkable performance on various benchmarks, treating the problem of Code Generation in a fashion similar to Natural Language Generation, trained with a Language Modelling (LM) objective. In addition, the property of programming language code being precisely evaluable with respect to its semantics -- through the use of Unit Tests to check its functional correctness -- lends itself to using Reinforcement Learning (RL) as a further training paradigm. Previous work has shown that RL can be applied as such to improve models' coding capabilities; however, such RL-based methods rely on a reward signal based on defined Unit Tests, which are much harder to obtain compared to the huge crawled code datasets used in LM objectives. In this work, we present a novel approach to automatically obtain data consisting of function signatures and associated Unit Tests, suitable for RL training of Code Synthesis models. We also introduce a straightforward, simple yet effective Actor-Critic RL training scheme and show that it, in conjunction with automatically generated training data, leads to improvement of a pre-trained code language model's performance by up to 9.9% improvement over the original underlying code synthesis LM, and up to 4.3% over RL-based models trained with standard PPO or CodeRL.
End-to-End Meta-Bayesian Optimisation with Transformer Neural Processes
May 25, 2023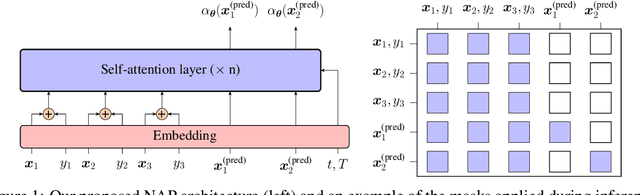
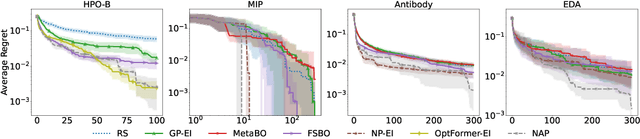
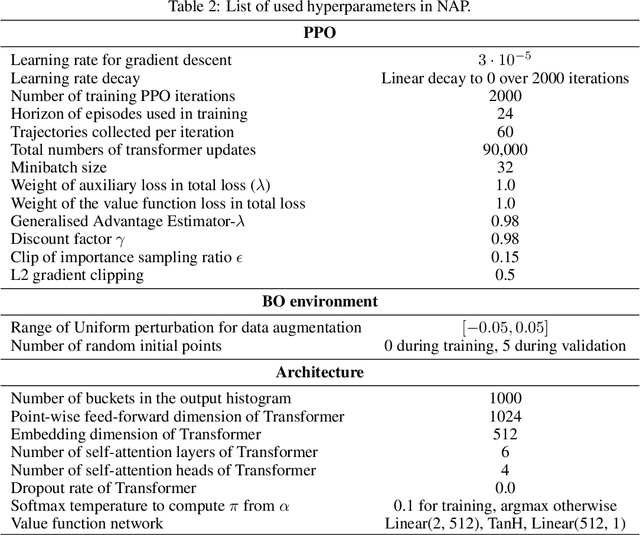
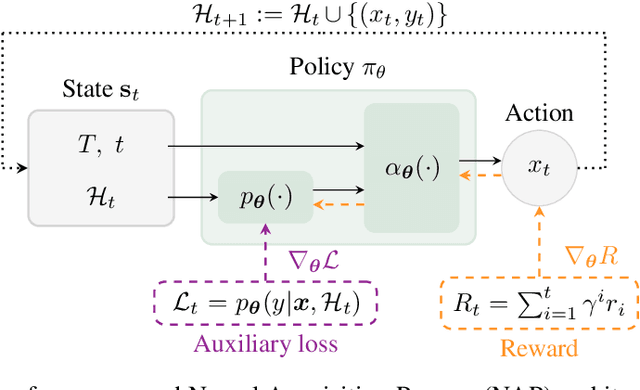
Meta-Bayesian optimisation (meta-BO) aims to improve the sample efficiency of Bayesian optimisation by leveraging data from related tasks. While previous methods successfully meta-learn either a surrogate model or an acquisition function independently, joint training of both components remains an open challenge. This paper proposes the first end-to-end differentiable meta-BO framework that generalises neural processes to learn acquisition functions via transformer architectures. We enable this end-to-end framework with reinforcement learning (RL) to tackle the lack of labelled acquisition data. Early on, we notice that training transformer-based neural processes from scratch with RL is challenging due to insufficient supervision, especially when rewards are sparse. We formalise this claim with a combinatorial analysis showing that the widely used notion of regret as a reward signal exhibits a logarithmic sparsity pattern in trajectory lengths. To tackle this problem, we augment the RL objective with an auxiliary task that guides part of the architecture to learn a valid probabilistic model as an inductive bias. We demonstrate that our method achieves state-of-the-art regret results against various baselines in experiments on standard hyperparameter optimisation tasks and also outperforms others in the real-world problems of mixed-integer programming tuning, antibody design, and logic synthesis for electronic design automation.
Sample-Efficient Optimisation with Probabilistic Transformer Surrogates
May 30, 2022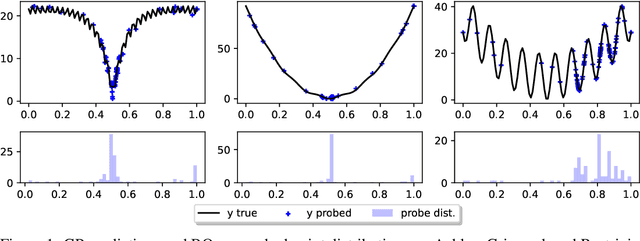
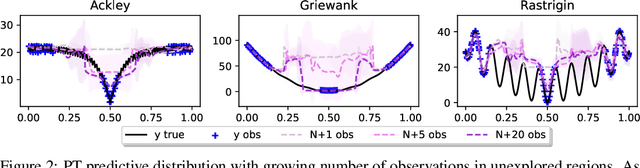
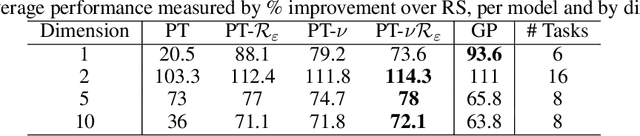
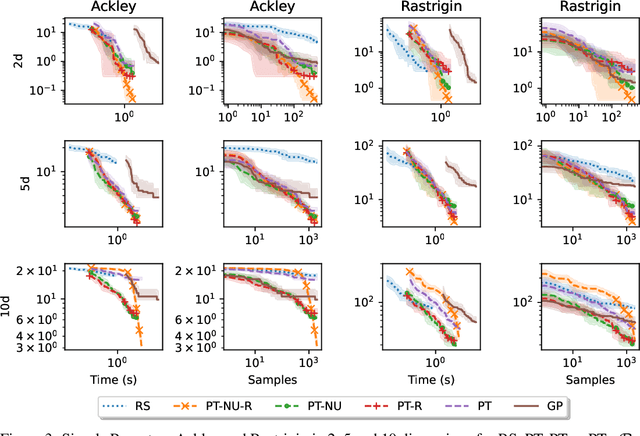
Faced with problems of increasing complexity, recent research in Bayesian Optimisation (BO) has focused on adapting deep probabilistic models as flexible alternatives to Gaussian Processes (GPs). In a similar vein, this paper investigates the feasibility of employing state-of-the-art probabilistic transformers in BO. Upon further investigation, we observe two drawbacks stemming from their training procedure and loss definition, hindering their direct deployment as proxies in black-box optimisation. First, we notice that these models are trained on uniformly distributed inputs, which impairs predictive accuracy on non-uniform data - a setting arising from any typical BO loop due to exploration-exploitation trade-offs. Second, we realise that training losses (e.g., cross-entropy) only asymptotically guarantee accurate posterior approximations, i.e., after arriving at the global optimum, which generally cannot be ensured. At the stationary points of the loss function, however, we observe a degradation in predictive performance especially in exploratory regions of the input space. To tackle these shortcomings we introduce two components: 1) a BO-tailored training prior supporting non-uniformly distributed points, and 2) a novel approximate posterior regulariser trading-off accuracy and input sensitivity to filter favourable stationary points for improved predictive performance. In a large panel of experiments, we demonstrate, for the first time, that one transformer pre-trained on data sampled from random GP priors produces competitive results on 16 benchmark black-boxes compared to GP-based BO. Since our model is only pre-trained once and used in all tasks without any retraining and/or fine-tuning, we report an order of magnitude time-reduction, while matching and sometimes outperforming GPs.
Neuro-Symbolic Hierarchical Rule Induction
Dec 26, 2021



We propose an efficient interpretable neuro-symbolic model to solve Inductive Logic Programming (ILP) problems. In this model, which is built from a set of meta-rules organised in a hierarchical structure, first-order rules are invented by learning embeddings to match facts and body predicates of a meta-rule. To instantiate it, we specifically design an expressive set of generic meta-rules, and demonstrate they generate a consequent fragment of Horn clauses. During training, we inject a controlled \pw{Gumbel} noise to avoid local optima and employ interpretability-regularization term to further guide the convergence to interpretable rules. We empirically validate our model on various tasks (ILP, visual genome, reinforcement learning) against several state-of-the-art methods.
A Survey on Interpretable Reinforcement Learning
Dec 24, 2021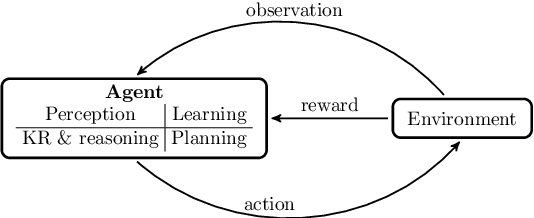
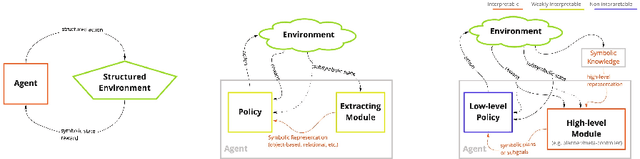

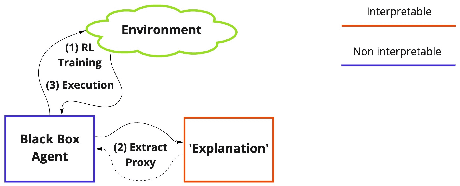
Although deep reinforcement learning has become a promising machine learning approach for sequential decision-making problems, it is still not mature enough for high-stake domains such as autonomous driving or medical applications. In such contexts, a learned policy needs for instance to be interpretable, so that it can be inspected before any deployment (e.g., for safety and verifiability reasons). This survey provides an overview of various approaches to achieve higher interpretability in reinforcement learning (RL). To that aim, we distinguish interpretability (as a property of a model) and explainability (as a post-hoc operation, with the intervention of a proxy) and discuss them in the context of RL with an emphasis on the former notion. In particular, we argue that interpretable RL may embrace different facets: interpretable inputs, interpretable (transition/reward) models, and interpretable decision-making. Based on this scheme, we summarize and analyze recent work related to interpretable RL with an emphasis on papers published in the past 10 years. We also discuss briefly some related research areas and point to some potential promising research directions.
Differentiable Logic Machines
Feb 24, 2021



The integration of reasoning, learning, and decision-making is key to build more general AI systems. As a step in this direction, we propose a novel neural-logic architecture that can solve both inductive logic programming (ILP) and deep reinforcement learning (RL) problems. Our architecture defines a restricted but expressive continuous space of first-order logic programs by assigning weights to predicates instead of rules. Therefore, it is fully differentiable and can be efficiently trained with gradient descent. Besides, in the deep RL setting with actor-critic algorithms, we propose a novel efficient critic architecture. Compared to state-of-the-art methods on both ILP and RL problems, our proposition achieves excellent performance, while being able to provide a fully interpretable solution and scaling much better, especially during the testing phase.
Learning Fair Policies in Decentralized Cooperative Multi-Agent Reinforcement Learning
Dec 17, 2020



We consider the problem of learning fair policies in (deep) cooperative multi-agent reinforcement learning (MARL). We formalize it in a principled way as the problem of optimizing a welfare function that explicitly encodes two important aspects of fairness: efficiency and equity. As a solution method, we propose a novel neural network architecture, which is composed of two sub-networks specifically designed for taking into account the two aspects of fairness. In experiments, we demonstrate the importance of the two sub-networks for fair optimization. Our overall approach is general as it can accommodate any (sub)differentiable welfare function. Therefore, it is compatible with various notions of fairness that have been proposed in the literature (e.g., lexicographic maximin, generalized Gini social welfare function, proportional fairness). Our solution method is generic and can be implemented in various MARL settings: centralized training and decentralized execution, or fully decentralized. Finally, we experimentally validate our approach in various domains and show that it can perform much better than previous methods.
Hyperparameter Auto-tuning in Self-Supervised Robotic Learning
Oct 19, 2020



Policy optimization in reinforcement learning requires the selection of numerous hyperparameters across different environments. Fixing them incorrectly may negatively impact optimization performance leading notably to insufficient or redundant learning. Insufficient learning (due to convergence to local optima) results in under-performing policies whilst redundant learning wastes time and resources. The effects are further exacerbated when using single policies to solve multi-task learning problems. In this paper, we study how the Evidence Lower Bound (ELBO) used in Variational Auto-Encoders (VAEs) is affected by the diversity of image samples. Different tasks or setups in visual reinforcement learning incur varying diversity. We exploit the ELBO to create an auto-tuning technique in self-supervised reinforcement learning. Our approach can auto-tune three hyperparameters: the replay buffer size, the number of policy gradient updates during each epoch, and the number of exploration steps during each epoch. We use the state-of-the-art self-supervised robotic learning framework (Reinforcement Learning with Imagined Goals (RIG) using Soft Actor-Critic) as baseline for experimental verification. Experiments show that our method can auto-tune online and yields the best performance at a fraction of the time and computational resources. Code, video, and appendix for simulated and real-robot experiments can be found at http://www.JuanRojas.net/autotune.