 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKwok-Yan Lam
Object-level Copy-Move Forgery Image Detection based on Inconsistency Mining
Apr 03, 2024
In copy-move tampering operations, perpetrators often employ techniques, such as blurring, to conceal tampering traces, posing significant challenges to the detection of object-level targets with intact structures. Focus on these challenges, this paper proposes an Object-level Copy-Move Forgery Image Detection based on Inconsistency Mining (IMNet). To obtain complete object-level targets, we customize prototypes for both the source and tampered regions and dynamically update them. Additionally, we extract inconsistent regions between coarse similar regions obtained through self-correlation calculations and regions composed of prototypes. The detected inconsistent regions are used as supplements to coarse similar regions to refine pixel-level detection. We operate experiments on three public datasets which validate the effectiveness and the robustness of the proposed IMNet.
STBA: Towards Evaluating the Robustness of DNNs for Query-Limited Black-box Scenario
Mar 30, 2024Many attack techniques have been proposed to explore the vulnerability of DNNs and further help to improve their robustness. Despite the significant progress made recently, existing black-box attack methods still suffer from unsatisfactory performance due to the vast number of queries needed to optimize desired perturbations. Besides, the other critical challenge is that adversarial examples built in a noise-adding manner are abnormal and struggle to successfully attack robust models, whose robustness is enhanced by adversarial training against small perturbations. There is no doubt that these two issues mentioned above will significantly increase the risk of exposure and result in a failure to dig deeply into the vulnerability of DNNs. Hence, it is necessary to evaluate DNNs' fragility sufficiently under query-limited settings in a non-additional way. In this paper, we propose the Spatial Transform Black-box Attack (STBA), a novel framework to craft formidable adversarial examples in the query-limited scenario. Specifically, STBA introduces a flow field to the high-frequency part of clean images to generate adversarial examples and adopts the following two processes to enhance their naturalness and significantly improve the query efficiency: a) we apply an estimated flow field to the high-frequency part of clean images to generate adversarial examples instead of introducing external noise to the benign image, and b) we leverage an efficient gradient estimation method based on a batch of samples to optimize such an ideal flow field under query-limited settings. Compared to existing score-based black-box baselines, extensive experiments indicated that STBA could effectively improve the imperceptibility of the adversarial examples and remarkably boost the attack success rate under query-limited settings.
A Learning-based Incentive Mechanism for Mobile AIGC Service in Decentralized Internet of Vehicles
Mar 29, 2024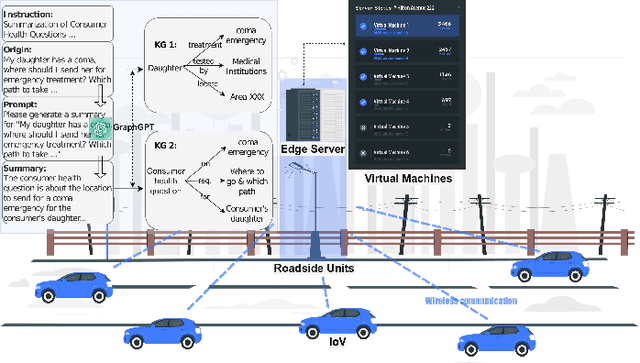
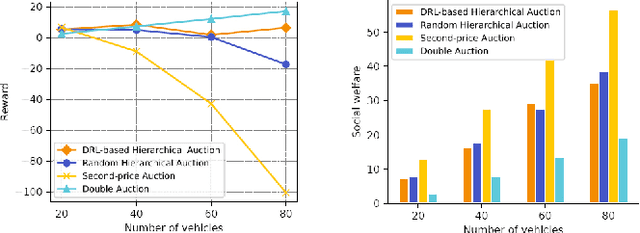
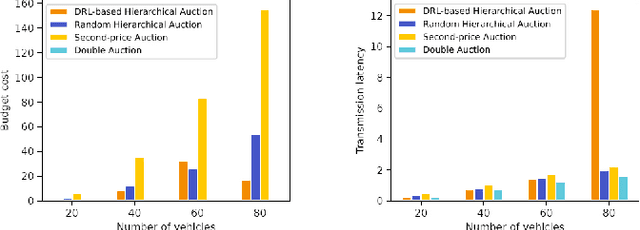
Artificial Intelligence-Generated Content (AIGC) refers to the paradigm of automated content generation utilizing AI models. Mobile AIGC services in the Internet of Vehicles (IoV) network have numerous advantages over traditional cloud-based AIGC services, including enhanced network efficiency, better reconfigurability, and stronger data security and privacy. Nonetheless, AIGC service provisioning frequently demands significant resources. Consequently, resource-constrained roadside units (RSUs) face challenges in maintaining a heterogeneous pool of AIGC services and addressing all user service requests without degrading overall performance. Therefore, in this paper, we propose a decentralized incentive mechanism for mobile AIGC service allocation, employing multi-agent deep reinforcement learning to find the balance between the supply of AIGC services on RSUs and user demand for services within the IoV context, optimizing user experience and minimizing transmission latency. Experimental results demonstrate that our approach achieves superior performance compared to other baseline models.
Threats, Attacks, and Defenses in Machine Unlearning: A Survey
Mar 26, 2024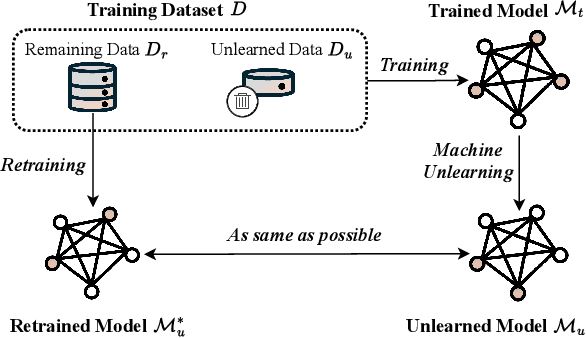
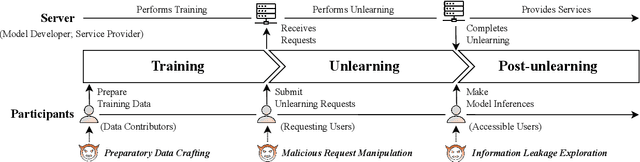

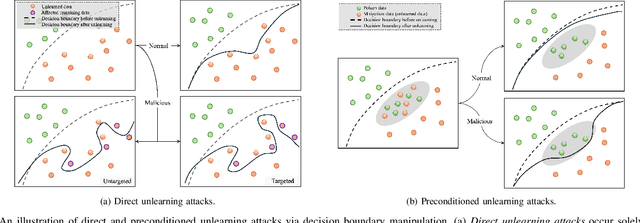
Machine Unlearning (MU) has gained considerable attention recently for its potential to achieve Safe AI by removing the influence of specific data from trained machine learning models. This process, known as knowledge removal, addresses AI governance concerns of training data such as quality, sensitivity, copyright restrictions, and obsolescence. This capability is also crucial for ensuring compliance with privacy regulations such as the Right To Be Forgotten. Furthermore, effective knowledge removal mitigates the risk of harmful outcomes, safeguarding against biases, misinformation, and unauthorized data exploitation, thereby enhancing the safe and responsible use of AI systems. Efforts have been made to design efficient unlearning approaches, with MU services being examined for integration with existing machine learning as a service, allowing users to submit requests to remove specific data from the training corpus. However, recent research highlights vulnerabilities in machine unlearning systems, such as information leakage and malicious unlearning requests, that can lead to significant security and privacy concerns. Moreover, extensive research indicates that unlearning methods and prevalent attacks fulfill diverse roles within MU systems. For instance, unlearning can act as a mechanism to recover models from backdoor attacks, while backdoor attacks themselves can serve as an evaluation metric for unlearning effectiveness. This underscores the intricate relationship and complex interplay among these mechanisms in maintaining system functionality and safety. This survey aims to fill the gap between the extensive number of studies on threats, attacks, and defenses in machine unlearning and the absence of a comprehensive review that categorizes their taxonomy, methods, and solutions, thus offering valuable insights for future research directions and practical implementations.
Device Scheduling and Assignment in Hierarchical Federated Learning for Internet of Things
Feb 04, 2024Federated Learning (FL) is a promising machine learning approach for Internet of Things (IoT), but it has to address network congestion problems when the population of IoT devices grows. Hierarchical FL (HFL) alleviates this issue by distributing model aggregation to multiple edge servers. Nevertheless, the challenge of communication overhead remains, especially in scenarios where all IoT devices simultaneously join the training process. For scalability, practical HFL schemes select a subset of IoT devices to participate in the training, hence the notion of device scheduling. In this setting, only selected IoT devices are scheduled to participate in the global training, with each of them being assigned to one edge server. Existing HFL assignment methods are primarily based on search mechanisms, which suffer from high latency in finding the optimal assignment. This paper proposes an improved K-Center algorithm for device scheduling and introduces a deep reinforcement learning-based approach for assigning IoT devices to edge servers. Experiments show that scheduling 50% of IoT devices is generally adequate for achieving convergence in HFL with much lower time delay and energy consumption. In cases where reduction in energy consumption (such as in Green AI) and reduction of messages (to avoid burst traffic) are key objectives, scheduling 30% IoT devices allows a substantial reduction in energy and messages with similar model accuracy.
Towards Efficient and Certified Recovery from Poisoning Attacks in Federated Learning
Jan 19, 2024Federated learning (FL) is vulnerable to poisoning attacks, where malicious clients manipulate their updates to affect the global model. Although various methods exist for detecting those clients in FL, identifying malicious clients requires sufficient model updates, and hence by the time malicious clients are detected, FL models have been already poisoned. Thus, a method is needed to recover an accurate global model after malicious clients are identified. Current recovery methods rely on (i) all historical information from participating FL clients and (ii) the initial model unaffected by the malicious clients, leading to a high demand for storage and computational resources. In this paper, we show that highly effective recovery can still be achieved based on (i) selective historical information rather than all historical information and (ii) a historical model that has not been significantly affected by malicious clients rather than the initial model. In this scenario, while maintaining comparable recovery performance, we can accelerate the recovery speed and decrease memory consumption. Following this concept, we introduce Crab, an efficient and certified recovery method, which relies on selective information storage and adaptive model rollback. Theoretically, we demonstrate that the difference between the global model recovered by Crab and the one recovered by train-from-scratch can be bounded under certain assumptions. Our empirical evaluation, conducted across three datasets over multiple machine learning models, and a variety of untargeted and targeted poisoning attacks reveals that Crab is both accurate and efficient, and consistently outperforms previous approaches in terms of both recovery speed and memory consumption.
SSTA: Salient Spatially Transformed Attack
Dec 12, 2023
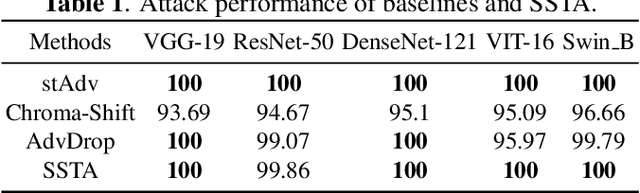

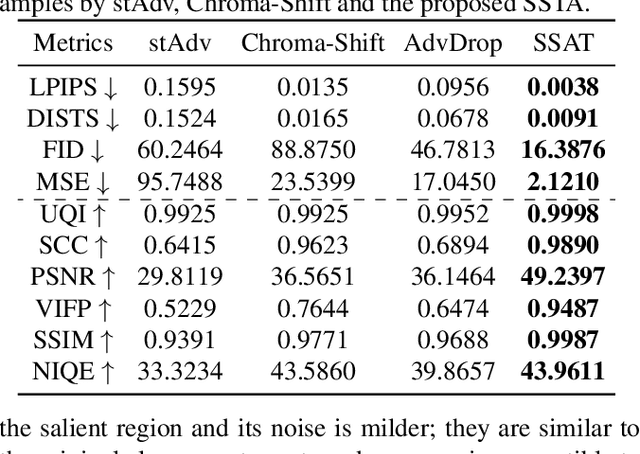
Extensive studies have demonstrated that deep neural networks (DNNs) are vulnerable to adversarial attacks, which brings a huge security risk to the further application of DNNs, especially for the AI models developed in the real world. Despite the significant progress that has been made recently, existing attack methods still suffer from the unsatisfactory performance of escaping from being detected by naked human eyes due to the formulation of adversarial example (AE) heavily relying on a noise-adding manner. Such mentioned challenges will significantly increase the risk of exposure and result in an attack to be failed. Therefore, in this paper, we propose the Salient Spatially Transformed Attack (SSTA), a novel framework to craft imperceptible AEs, which enhance the stealthiness of AEs by estimating a smooth spatial transform metric on a most critical area to generate AEs instead of adding external noise to the whole image. Compared to state-of-the-art baselines, extensive experiments indicated that SSTA could effectively improve the imperceptibility of the AEs while maintaining a 100\% attack success rate.
FedPEAT: Convergence of Federated Learning, Parameter-Efficient Fine Tuning, and Emulator Assisted Tuning for Artificial Intelligence Foundation Models with Mobile Edge Computing
Oct 26, 2023The emergence of foundation models, including language and vision models, has reshaped AI's landscape, offering capabilities across various applications. Deploying and fine-tuning these large models, like GPT-3 and BERT, presents challenges, especially in the current foundation model era. We introduce Emulator-Assisted Tuning (EAT) combined with Parameter-Efficient Fine-Tuning (PEFT) to form Parameter-Efficient Emulator-Assisted Tuning (PEAT). Further, we expand this into federated learning as Federated PEAT (FedPEAT). FedPEAT uses adapters, emulators, and PEFT for federated model tuning, enhancing model privacy and memory efficiency. Adapters adjust pre-trained models, while emulators give a compact representation of original models, addressing both privacy and efficiency. Adaptable to various neural networks, our approach also uses deep reinforcement learning for hyper-parameter optimization. We tested FedPEAT in a unique scenario with a server participating in collaborative federated tuning, showcasing its potential in tackling foundation model challenges.
Efficient Dataset Distillation through Alignment with Smooth and High-Quality Expert Trajectories
Oct 16, 2023Training a large and state-of-the-art machine learning model typically necessitates the use of large-scale datasets, which, in turn, makes the training and parameter-tuning process expensive and time-consuming. Some researchers opt to distil information from real-world datasets into tiny and compact synthetic datasets while maintaining their ability to train a well-performing model, hence proposing a data-efficient method known as Dataset Distillation (DD). Despite recent progress in this field, existing methods still underperform and cannot effectively replace large datasets. In this paper, unlike previous methods that focus solely on improving the efficacy of student distillation, we are the first to recognize the important interplay between expert and student. We argue the significant impact of expert smoothness when employing more potent expert trajectories in subsequent dataset distillation. Based on this, we introduce the integration of clipping loss and gradient penalty to regulate the rate of parameter changes in expert trajectories. Furthermore, in response to the sensitivity exhibited towards randomly initialized variables during distillation, we propose representative initialization for synthetic dataset and balanced inner-loop loss. Finally, we present two enhancement strategies, namely intermediate matching loss and weight perturbation, to mitigate the potential occurrence of cumulative errors. We conduct extensive experiments on datasets of different scales, sizes, and resolutions. The results demonstrate that the proposed method significantly outperforms prior methods.
SCME: A Self-Contrastive Method for Data-free and Query-Limited Model Extraction Attack
Oct 15, 2023Previous studies have revealed that artificial intelligence (AI) systems are vulnerable to adversarial attacks. Among them, model extraction attacks fool the target model by generating adversarial examples on a substitute model. The core of such an attack is training a substitute model as similar to the target model as possible, where the simulation process can be categorized in a data-dependent and data-free manner. Compared with the data-dependent method, the data-free one has been proven to be more practical in the real world since it trains the substitute model with synthesized data. However, the distribution of these fake data lacks diversity and cannot detect the decision boundary of the target model well, resulting in the dissatisfactory simulation effect. Besides, these data-free techniques need a vast number of queries to train the substitute model, increasing the time and computing consumption and the risk of exposure. To solve the aforementioned problems, in this paper, we propose a novel data-free model extraction method named SCME (Self-Contrastive Model Extraction), which considers both the inter- and intra-class diversity in synthesizing fake data. In addition, SCME introduces the Mixup operation to augment the fake data, which can explore the target model's decision boundary effectively and improve the simulating capacity. Extensive experiments show that the proposed method can yield diversified fake data. Moreover, our method has shown superiority in many different attack settings under the query-limited scenario, especially for untargeted attacks, the SCME outperforms SOTA methods by 11.43\% on average for five baseline datasets.