 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLaurenz Wiskott
ProtoP-OD: Explainable Object Detection with Prototypical Parts
Feb 29, 2024
Interpretation and visualization of the behavior of detection transformers tends to highlight the locations in the image that the model attends to, but it provides limited insight into the \emph{semantics} that the model is focusing on. This paper introduces an extension to detection transformers that constructs prototypical local features and uses them in object detection. These custom features, which we call prototypical parts, are designed to be mutually exclusive and align with the classifications of the model. The proposed extension consists of a bottleneck module, the prototype neck, that computes a discretized representation of prototype activations and a new loss term that matches prototypes to object classes. This setup leads to interpretable representations in the prototype neck, allowing visual inspection of the image content perceived by the model and a better understanding of the model's reliability. We show experimentally that our method incurs only a limited performance penalty, and we provide examples that demonstrate the quality of the explanations provided by our method, which we argue outweighs the performance penalty.
Interpretable Brain-Inspired Representations Improve RL Performance on Visual Navigation Tasks
Feb 19, 2024Visual navigation requires a whole range of capabilities. A crucial one of these is the ability of an agent to determine its own location and heading in an environment. Prior works commonly assume this information as given, or use methods which lack a suitable inductive bias and accumulate error over time. In this work, we show how the method of slow feature analysis (SFA), inspired by neuroscience research, overcomes both limitations by generating interpretable representations of visual data that encode location and heading of an agent. We employ SFA in a modern reinforcement learning context, analyse and compare representations and illustrate where hierarchical SFA can outperform other feature extractors on navigation tasks.
Classification and Reconstruction Processes in Deep Predictive Coding Networks: Antagonists or Allies?
Jan 17, 2024Predictive coding-inspired deep networks for visual computing integrate classification and reconstruction processes in shared intermediate layers. Although synergy between these processes is commonly assumed, it has yet to be convincingly demonstrated. In this study, we take a critical look at how classifying and reconstructing interact in deep learning architectures. Our approach utilizes a purposefully designed family of model architectures reminiscent of autoencoders, each equipped with an encoder, a decoder, and a classification head featuring varying modules and complexities. We meticulously analyze the extent to which classification- and reconstruction-driven information can seamlessly coexist within the shared latent layer of the model architectures. Our findings underscore a significant challenge: Classification-driven information diminishes reconstruction-driven information in intermediate layers' shared representations and vice versa. While expanding the shared representation's dimensions or increasing the network's complexity can alleviate this trade-off effect, our results challenge prevailing assumptions in predictive coding and offer guidance for future iterations of predictive coding concepts in deep networks.
Improving Reinforcement Learning Efficiency with Auxiliary Tasks in Non-Visual Environments: A Comparison
Oct 09, 2023Real-world reinforcement learning (RL) environments, whether in robotics or industrial settings, often involve non-visual observations and require not only efficient but also reliable and thus interpretable and flexible RL approaches. To improve efficiency, agents that perform state representation learning with auxiliary tasks have been widely studied in visual observation contexts. However, for real-world problems, dedicated representation learning modules that are decoupled from RL agents are more suited to meet requirements. This study compares common auxiliary tasks based on, to the best of our knowledge, the only decoupled representation learning method for low-dimensional non-visual observations. We evaluate potential improvements in sample efficiency and returns for environments ranging from a simple pendulum to a complex simulated robotics task. Our findings show that representation learning with auxiliary tasks only provides performance gains in sufficiently complex environments and that learning environment dynamics is preferable to predicting rewards. These insights can inform future development of interpretable representation learning approaches for non-visual observations and advance the use of RL solutions in real-world scenarios.
Comparing Auxiliary Tasks for Learning Representations for Reinforcement Learning
Oct 06, 2023Learning state representations has gained steady popularity in reinforcement learning (RL) due to its potential to improve both sample efficiency and returns on many environments. A straightforward and efficient method is to generate representations with a distinct neural network trained on an auxiliary task, i.e. a task that differs from the actual RL task. While a whole range of such auxiliary tasks has been proposed in the literature, a comparison on typical continuous control benchmark environments is computationally expensive and has, to the best of our knowledge, not been performed before. This paper presents such a comparison of common auxiliary tasks, based on hundreds of agents trained with state-of-the-art off-policy RL algorithms. We compare possible improvements in both sample efficiency and returns for environments ranging from simple pendulum to a complex simulated robotics task. Our findings show that representation learning with auxiliary tasks is beneficial for environments of higher dimension and complexity, and that learning environment dynamics is preferable to predicting rewards. We believe these insights will enable other researchers to make more informed decisions on how to utilize representation learning for their specific problem.
A Tutorial on the Spectral Theory of Markov Chains
Jul 05, 2022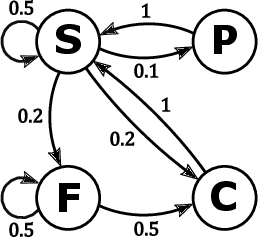
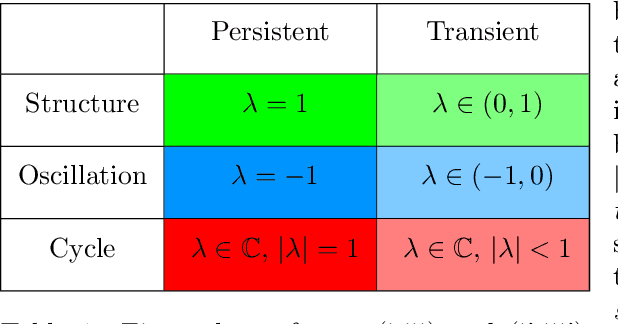
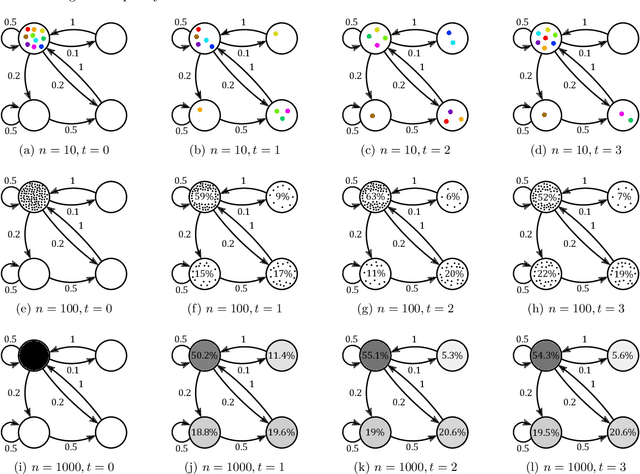
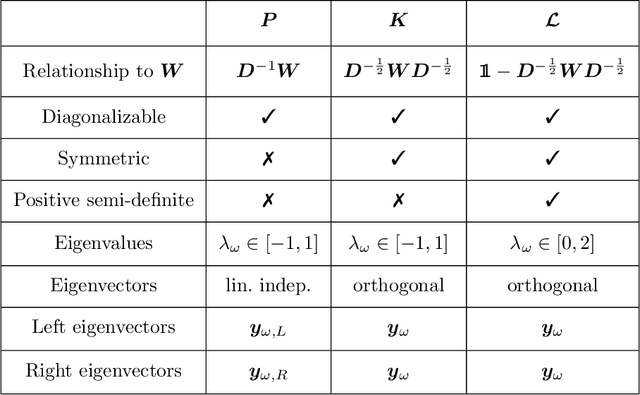
Markov chains are a class of probabilistic models that have achieved widespread application in the quantitative sciences. This is in part due to their versatility, but is compounded by the ease with which they can be probed analytically. This tutorial provides an in-depth introduction to Markov chains, and explores their connection to graphs and random walks. We utilize tools from linear algebra and graph theory to describe the transition matrices of different types of Markov chains, with a particular focus on exploring properties of the eigenvalues and eigenvectors corresponding to these matrices. The results presented are relevant to a number of methods in machine learning and data mining, which we describe at various stages. Rather than being a novel academic study in its own right, this text presents a collection of known results, together with some new concepts. Moreover, the tutorial focuses on offering intuition to readers rather than formal understanding, and only assumes basic exposure to concepts from linear algebra and probability theory. It is therefore accessible to students and researchers from a wide variety of disciplines.
A model of semantic completion in generative episodic memory
Nov 26, 2021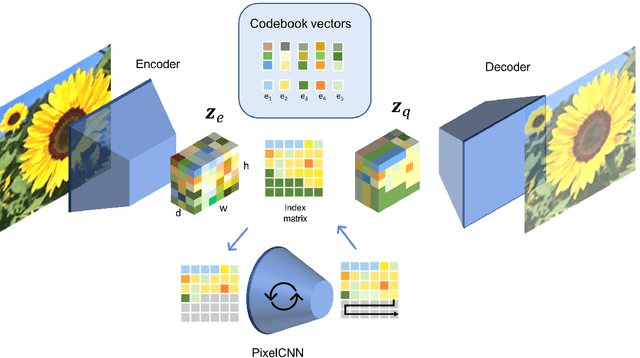
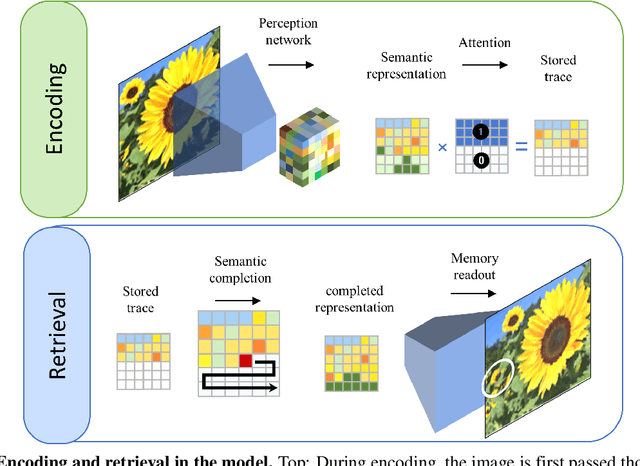
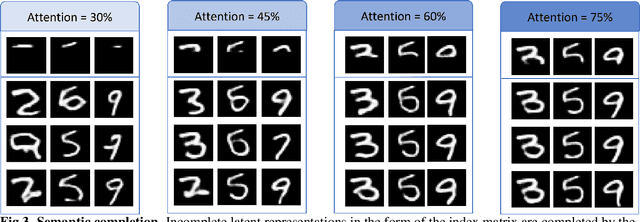
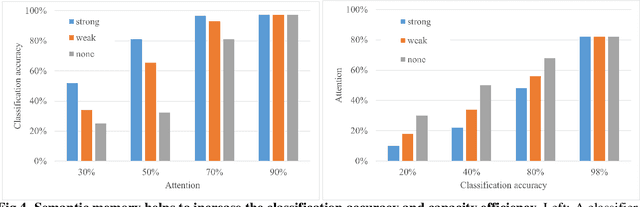
Many different studies have suggested that episodic memory is a generative process, but most computational models adopt a storage view. In this work, we propose a computational model for generative episodic memory. It is based on the central hypothesis that the hippocampus stores and retrieves selected aspects of an episode as a memory trace, which is necessarily incomplete. At recall, the neocortex reasonably fills in the missing information based on general semantic information in a process we call semantic completion. As episodes we use images of digits (MNIST) augmented by different backgrounds representing context. Our model is based on a VQ-VAE which generates a compressed latent representation in form of an index matrix, which still has some spatial resolution. We assume that attention selects some part of the index matrix while others are discarded, this then represents the gist of the episode and is stored as a memory trace. At recall the missing parts are filled in by a PixelCNN, modeling semantic completion, and the completed index matrix is then decoded into a full image by the VQ-VAE. The model is able to complete missing parts of a memory trace in a semantically plausible way up to the point where it can generate plausible images from scratch. Due to the combinatorics in the index matrix, the model generalizes well to images not trained on. Compression as well as semantic completion contribute to a strong reduction in memory requirements and robustness to noise. Finally we also model an episodic memory experiment and can reproduce that semantically congruent contexts are always recalled better than incongruent ones, high attention levels improve memory accuracy in both cases, and contexts that are not remembered correctly are more often remembered semantically congruently than completely wrong.
Modular Networks Prevent Catastrophic Interference in Model-Based Multi-Task Reinforcement Learning
Nov 15, 2021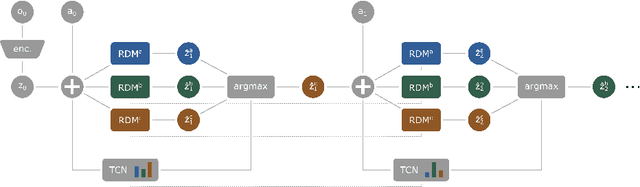

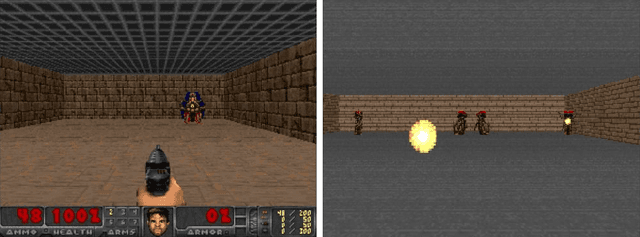
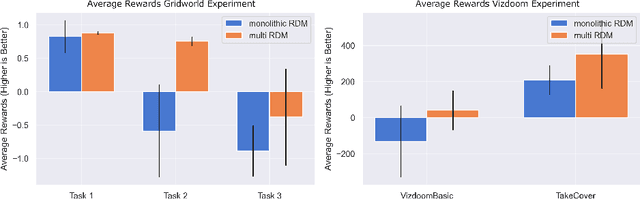
In a multi-task reinforcement learning setting, the learner commonly benefits from training on multiple related tasks by exploiting similarities among them. At the same time, the trained agent is able to solve a wider range of different problems. While this effect is well documented for model-free multi-task methods, we demonstrate a detrimental effect when using a single learned dynamics model for multiple tasks. Thus, we address the fundamental question of whether model-based multi-task reinforcement learning benefits from shared dynamics models in a similar way model-free methods do from shared policy networks. Using a single dynamics model, we see clear evidence of task confusion and reduced performance. As a remedy, enforcing an internal structure for the learned dynamics model by training isolated sub-networks for each task notably improves performance while using the same amount of parameters. We illustrate our findings by comparing both methods on a simple gridworld and a more complex vizdoom multi-task experiment.
Reward prediction for representation learning and reward shaping
May 07, 2021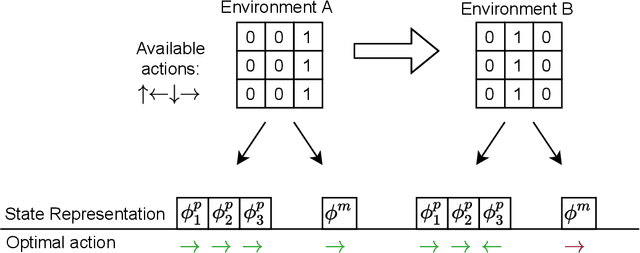
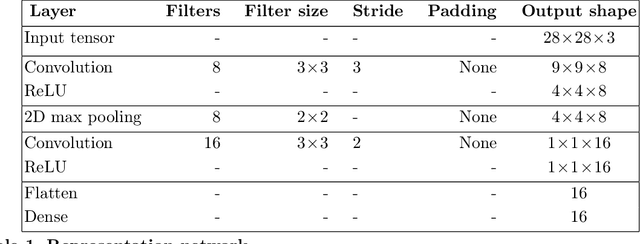
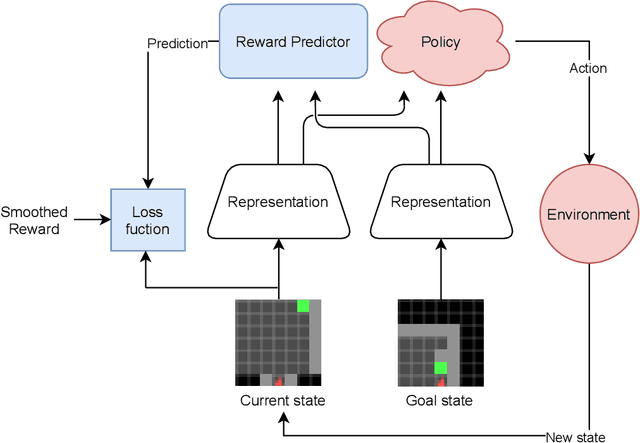
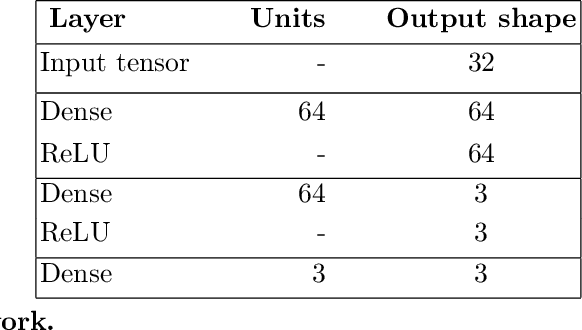
One of the fundamental challenges in reinforcement learning (RL) is the one of data efficiency: modern algorithms require a very large number of training samples, especially compared to humans, for solving environments with high-dimensional observations. The severity of this problem is increased when the reward signal is sparse. In this work, we propose learning a state representation in a self-supervised manner for reward prediction. The reward predictor learns to estimate either a raw or a smoothed version of the true reward signal in environment with a single, terminating, goal state. We augment the training of out-of-the-box RL agents by shaping the reward using our reward predictor during policy learning. Using our representation for preprocessing high-dimensional observations, as well as using the predictor for reward shaping, is shown to significantly enhance Actor Critic using Kronecker-factored Trust Region and Proximal Policy Optimization in single-goal environments with visual inputs.
Singular Sturm-Liouville Problems with Zero Potential (q=0) and Singular Slow Feature Analysis
Nov 09, 2020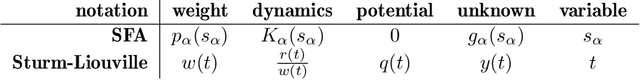
A Sturm-Liouville problem ($\lambda wy=(ry')'+qy$) is singular if its domain is unbounded or if $r$ or $w$ vanish at the boundary. Then it is difficult to tell whether profound results from regular Sturm-Liouville theory apply. Existing criteria are often difficult to apply, e.g. because they are formulated in terms of the solution function. We study the special case that the potential $q$ is zero under Neumann boundary conditions and give simple and explicit criteria, solely in terms of the coefficient functions, to assess whether various properties of the regular case apply. Specifically, these properties are discreteness of the spectrum (BD), self-adjointness, oscillation ($i$th solution has $i$ zeros) and that the $i$th eigenvalue equals the SFA delta value (the total energy) of the $i$th solution. We further prove that stationary points of each solution strictly interlace with its zeros (in singular or regular case, regardless of the boundary condition, for zero potential or if $q < \lambda w$ everywhere). If $\frac{r}{w}$ is bounded and of bounded variation, the criterion simplifies to requiring $\frac{|w'|}{w} \to \infty$ at singular boundary points. This research is motivated by Slow Feature Analysis (SFA), a data processing algorithm that extracts the slowest uncorrelated signals from a high-dimensional input signal and has notable success in computer vision, computational neuroscience and blind source separation. From [Sprekeler et al., 2014] it is known that for an important class of scenarios (statistically independent input), an analytic formulation of SFA reduces to a Sturm-Liouville problem with zero potential and Neumann boundary conditions. So far, the mathematical SFA theory has only considered the regular case, except for a special case that is solved by Hermite Polynomials. This work generalizes SFA theory to the singular case, i.e. open-space scenarios.