 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLawrence Carin
Meta-Learned Attribute Self-Interaction Network for Continual and Generalized Zero-Shot Learning
Dec 02, 2023
Zero-shot learning (ZSL) is a promising approach to generalizing a model to categories unseen during training by leveraging class attributes, but challenges remain. Recently, methods using generative models to combat bias towards classes seen during training have pushed state of the art, but these generative models can be slow or computationally expensive to train. Also, these generative models assume that the attribute vector of each unseen class is available a priori at training, which is not always practical. Additionally, while many previous ZSL methods assume a one-time adaptation to unseen classes, in reality, the world is always changing, necessitating a constant adjustment of deployed models. Models unprepared to handle a sequential stream of data are likely to experience catastrophic forgetting. We propose a Meta-learned Attribute self-Interaction Network (MAIN) for continual ZSL. By pairing attribute self-interaction trained using meta-learning with inverse regularization of the attribute encoder, we are able to outperform state-of-the-art results without leveraging the unseen class attributes while also being able to train our models substantially faster (>100x) than expensive generative-based approaches. We demonstrate this with experiments on five standard ZSL datasets (CUB, aPY, AWA1, AWA2, and SUN) in the generalized zero-shot learning and continual (fixed/dynamic) zero-shot learning settings. Extensive ablations and analyses demonstrate the efficacy of various components proposed.
Open World Classification with Adaptive Negative Samples
Mar 09, 2023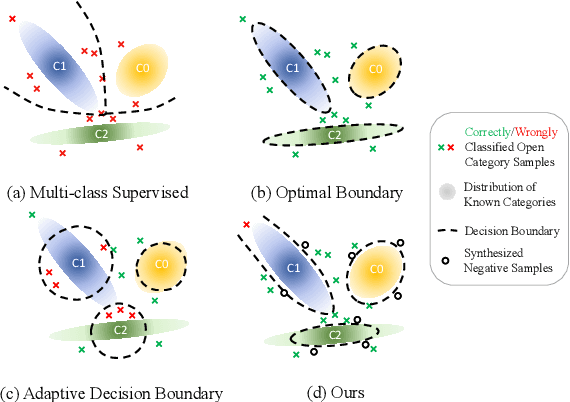
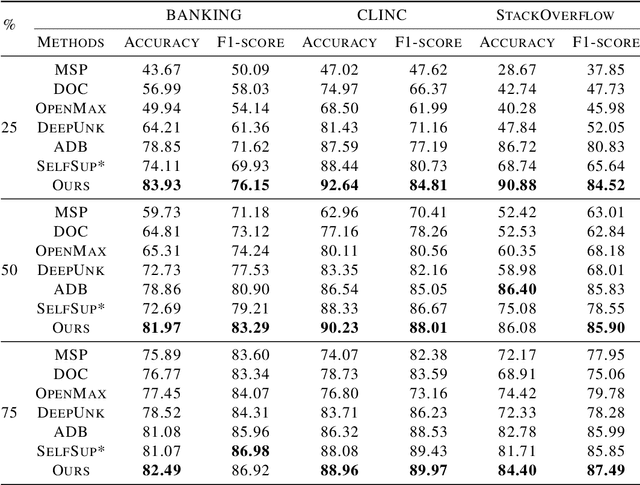
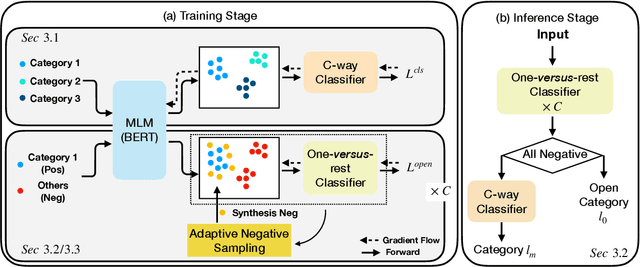
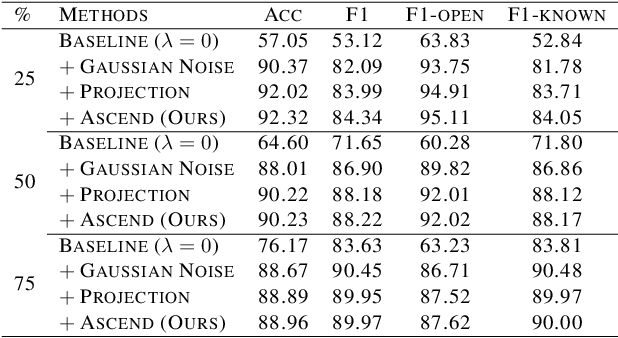
Open world classification is a task in natural language processing with key practical relevance and impact. Since the open or {\em unknown} category data only manifests in the inference phase, finding a model with a suitable decision boundary accommodating for the identification of known classes and discrimination of the open category is challenging. The performance of existing models is limited by the lack of effective open category data during the training stage or the lack of a good mechanism to learn appropriate decision boundaries. We propose an approach based on \underline{a}daptive \underline{n}egative \underline{s}amples (ANS) designed to generate effective synthetic open category samples in the training stage and without requiring any prior knowledge or external datasets. Empirically, we find a significant advantage in using auxiliary one-versus-rest binary classifiers, which effectively utilize the generated negative samples and avoid the complex threshold-seeking stage in previous works. Extensive experiments on three benchmark datasets show that ANS achieves significant improvements over state-of-the-art methods.
Pushing the Efficiency Limit Using Structured Sparse Convolutions
Oct 23, 2022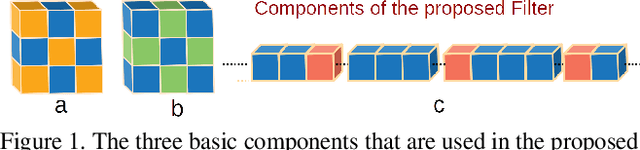
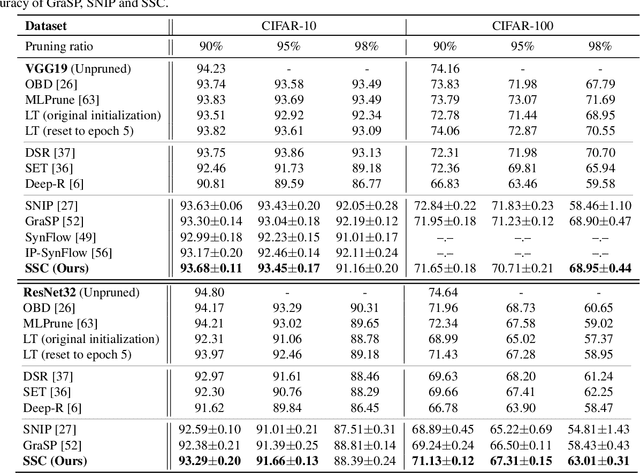
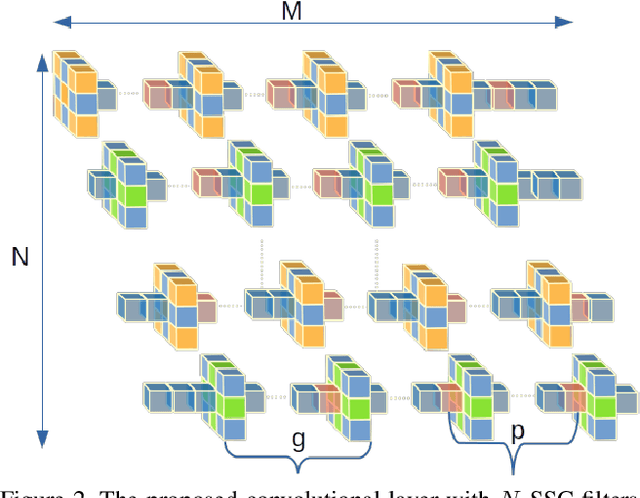
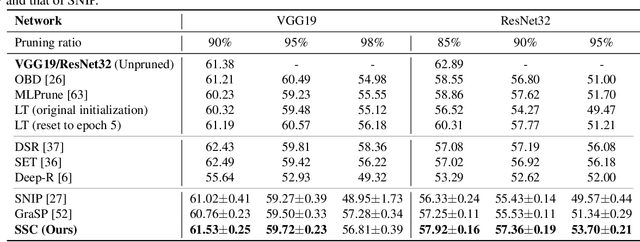
Weight pruning is among the most popular approaches for compressing deep convolutional neural networks. Recent work suggests that in a randomly initialized deep neural network, there exist sparse subnetworks that achieve performance comparable to the original network. Unfortunately, finding these subnetworks involves iterative stages of training and pruning, which can be computationally expensive. We propose Structured Sparse Convolution (SSC), which leverages the inherent structure in images to reduce the parameters in the convolutional filter. This leads to improved efficiency of convolutional architectures compared to existing methods that perform pruning at initialization. We show that SSC is a generalization of commonly used layers (depthwise, groupwise and pointwise convolution) in ``efficient architectures.'' Extensive experiments on well-known CNN models and datasets show the effectiveness of the proposed method. Architectures based on SSC achieve state-of-the-art performance compared to baselines on CIFAR-10, CIFAR-100, Tiny-ImageNet, and ImageNet classification benchmarks.
Pseudo-OOD training for robust language models
Oct 17, 2022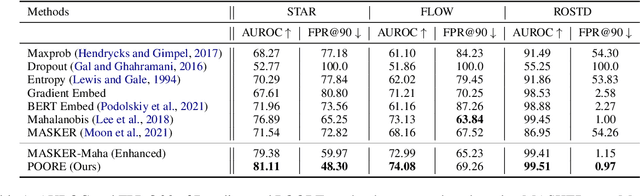

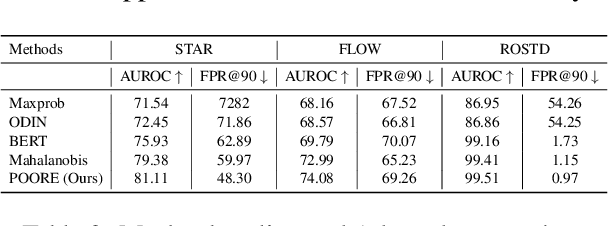

While pre-trained large-scale deep models have garnered attention as an important topic for many downstream natural language processing (NLP) tasks, such models often make unreliable predictions on out-of-distribution (OOD) inputs. As such, OOD detection is a key component of a reliable machine-learning model for any industry-scale application. Common approaches often assume access to additional OOD samples during the training stage, however, outlier distribution is often unknown in advance. Instead, we propose a post hoc framework called POORE - POsthoc pseudo-Ood REgularization, that generates pseudo-OOD samples using in-distribution (IND) data. The model is fine-tuned by introducing a new regularization loss that separates the embeddings of IND and OOD data, which leads to significant gains on the OOD prediction task during testing. We extensively evaluate our framework on three real-world dialogue systems, achieving new state-of-the-art in OOD detection.
Collaborative Anomaly Detection
Sep 20, 2022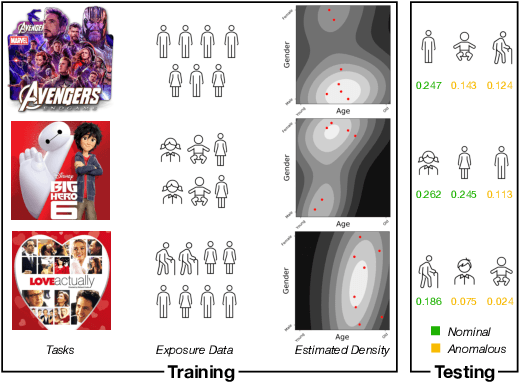
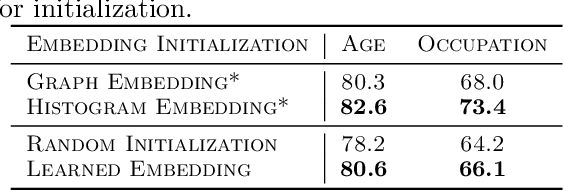
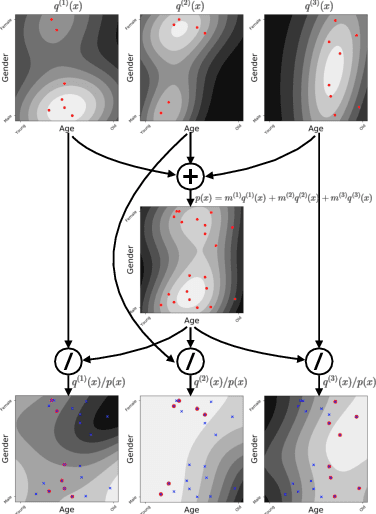

In recommendation systems, items are likely to be exposed to various users and we would like to learn about the familiarity of a new user with an existing item. This can be formulated as an anomaly detection (AD) problem distinguishing between "common users" (nominal) and "fresh users" (anomalous). Considering the sheer volume of items and the sparsity of user-item paired data, independently applying conventional single-task detection methods on each item quickly becomes difficult, while correlations between items are ignored. To address this multi-task anomaly detection problem, we propose collaborative anomaly detection (CAD) to jointly learn all tasks with an embedding encoding correlations among tasks. We explore CAD with conditional density estimation and conditional likelihood ratio estimation. We found that: $i$) estimating a likelihood ratio enjoys more efficient learning and yields better results than density estimation. $ii$) It is beneficial to select a small number of tasks in advance to learn a task embedding model, and then use it to warm-start all task embeddings. Consequently, these embeddings can capture correlations between tasks and generalize to new correlated tasks.
Number Entity Recognition
May 07, 2022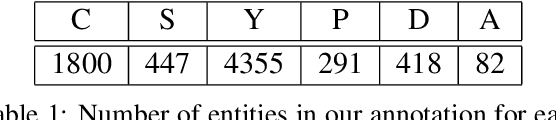
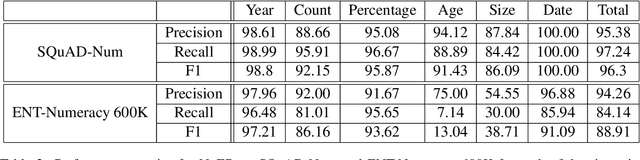

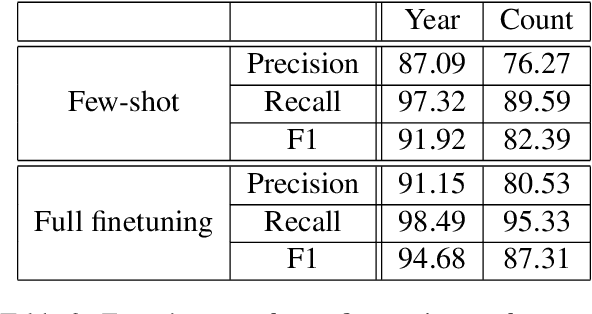
Numbers are essential components of text, like any other word tokens, from which natural language processing (NLP) models are built and deployed. Though numbers are typically not accounted for distinctly in most NLP tasks, there is still an underlying amount of numeracy already exhibited by NLP models. In this work, we attempt to tap this potential of state-of-the-art NLP models and transfer their ability to boost performance in related tasks. Our proposed classification of numbers into entities helps NLP models perform well on several tasks, including a handcrafted Fill-In-The-Blank (FITB) task and on question answering using joint embeddings, outperforming the BERT and RoBERTa baseline classification.
elBERto: Self-supervised Commonsense Learning for Question Answering
Mar 17, 2022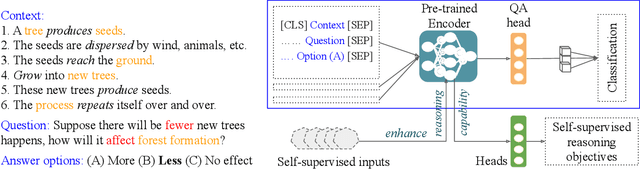

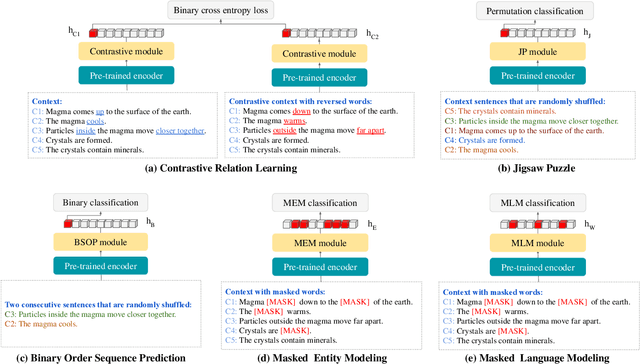
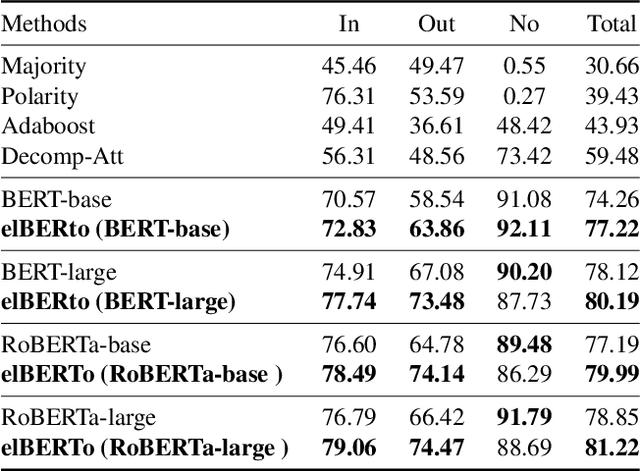
Commonsense question answering requires reasoning about everyday situations and causes and effects implicit in context. Typically, existing approaches first retrieve external evidence and then perform commonsense reasoning using these evidence. In this paper, we propose a Self-supervised Bidirectional Encoder Representation Learning of Commonsense (elBERto) framework, which is compatible with off-the-shelf QA model architectures. The framework comprises five self-supervised tasks to force the model to fully exploit the additional training signals from contexts containing rich commonsense. The tasks include a novel Contrastive Relation Learning task to encourage the model to distinguish between logically contrastive contexts, a new Jigsaw Puzzle task that requires the model to infer logical chains in long contexts, and three classic SSL tasks to maintain pre-trained models language encoding ability. On the representative WIQA, CosmosQA, and ReClor datasets, elBERto outperforms all other methods, including those utilizing explicit graph reasoning and external knowledge retrieval. Moreover, elBERto achieves substantial improvements on out-of-paragraph and no-effect questions where simple lexical similarity comparison does not help, indicating that it successfully learns commonsense and is able to leverage it when given dynamic context.
Capturing Actionable Dynamics with Structured Latent Ordinary Differential Equations
Feb 25, 2022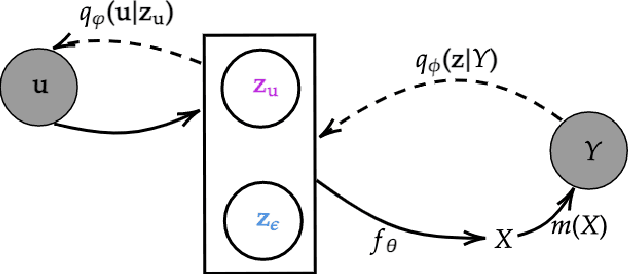


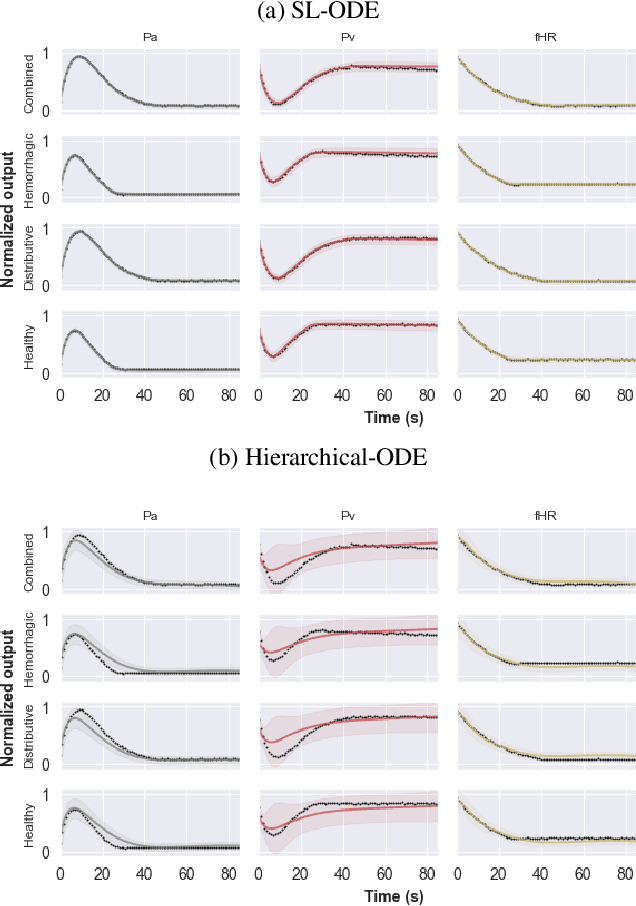
End-to-end learning of dynamical systems with black-box models, such as neural ordinary differential equations (ODEs), provides a flexible framework for learning dynamics from data without prescribing a mathematical model for the dynamics. Unfortunately, this flexibility comes at the cost of understanding the dynamical system, for which ODEs are used ubiquitously. Further, experimental data are collected under various conditions (inputs), such as treatments, or grouped in some way, such as part of sub-populations. Understanding the effects of these system inputs on system outputs is crucial to have any meaningful model of a dynamical system. To that end, we propose a structured latent ODE model that explicitly captures system input variations within its latent representation. Building on a static latent variable specification, our model learns (independent) stochastic factors of variation for each input to the system, thus separating the effects of the system inputs in the latent space. This approach provides actionable modeling through the controlled generation of time-series data for novel input combinations (or perturbations). Additionally, we propose a flexible approach for quantifying uncertainties, leveraging a quantile regression formulation. Experimental results on challenging biological datasets show consistent improvements over competitive baselines in the controlled generation of observational data and prediction of biologically meaningful system inputs.
Explainable multiple abnormality classification of chest CT volumes with AxialNet and HiResCAM
Nov 24, 2021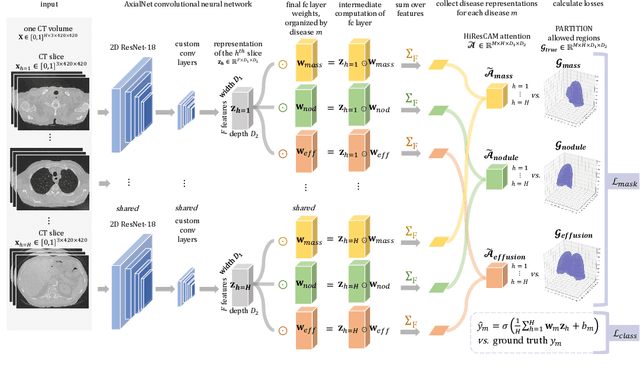
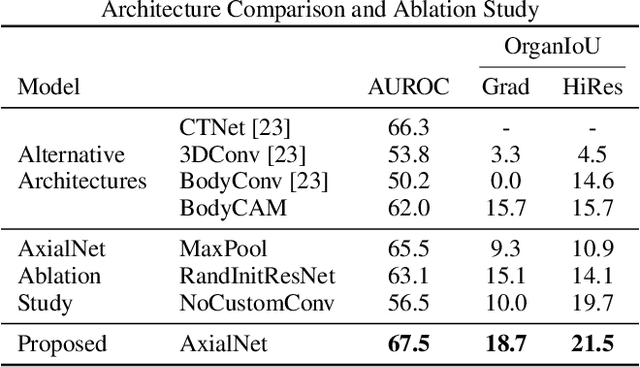
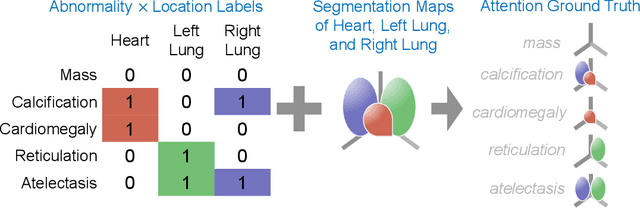

Understanding model predictions is critical in healthcare, to facilitate rapid verification of model correctness and to guard against use of models that exploit confounding variables. We introduce the challenging new task of explainable multiple abnormality classification in volumetric medical images, in which a model must indicate the regions used to predict each abnormality. To solve this task, we propose a multiple instance learning convolutional neural network, AxialNet, that allows identification of top slices for each abnormality. Next we incorporate HiResCAM, an attention mechanism, to identify sub-slice regions. We prove that for AxialNet, HiResCAM explanations are guaranteed to reflect the locations the model used, unlike Grad-CAM which sometimes highlights irrelevant locations. Armed with a model that produces faithful explanations, we then aim to improve the model's learning through a novel mask loss that leverages HiResCAM and 3D allowed regions to encourage the model to predict abnormalities based only on the organs in which those abnormalities appear. The 3D allowed regions are obtained automatically through a new approach, PARTITION, that combines location information extracted from radiology reports with organ segmentation maps obtained through morphological image processing. Overall, we propose the first model for explainable multi-abnormality prediction in volumetric medical images, and then use the mask loss to achieve a 33% improvement in organ localization of multiple abnormalities in the RAD-ChestCT data set of 36,316 scans, representing the state of the art. This work advances the clinical applicability of multiple abnormality modeling in chest CT volumes.
Finite-Time Consensus Learning for Decentralized Optimization with Nonlinear Gossiping
Nov 13, 2021
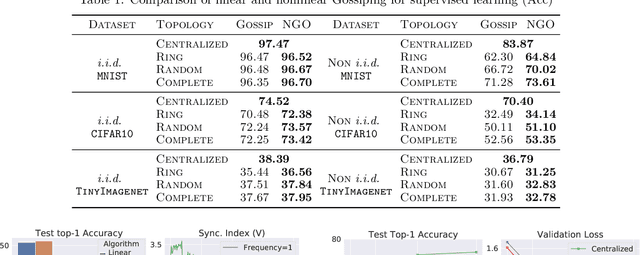
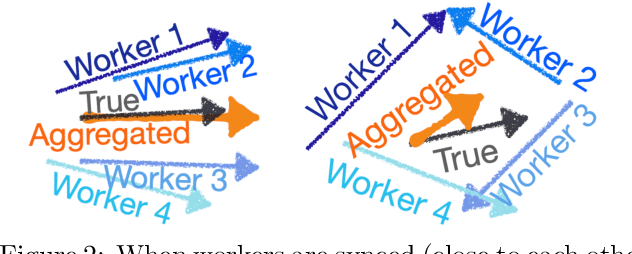

Distributed learning has become an integral tool for scaling up machine learning and addressing the growing need for data privacy. Although more robust to the network topology, decentralized learning schemes have not gained the same level of popularity as their centralized counterparts for being less competitive performance-wise. In this work, we attribute this issue to the lack of synchronization among decentralized learning workers, showing both empirically and theoretically that the convergence rate is tied to the synchronization level among the workers. Such motivated, we present a novel decentralized learning framework based on nonlinear gossiping (NGO), that enjoys an appealing finite-time consensus property to achieve better synchronization. We provide a careful analysis of its convergence and discuss its merits for modern distributed optimization applications, such as deep neural networks. Our analysis on how communication delay and randomized chats affect learning further enables the derivation of practical variants that accommodate asynchronous and randomized communications. To validate the effectiveness of our proposal, we benchmark NGO against competing solutions through an extensive set of tests, with encouraging results reported.