 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeslie Pack Kaelbling
Partially Observable Task and Motion Planning with Uncertainty and Risk Awareness
Mar 15, 2024


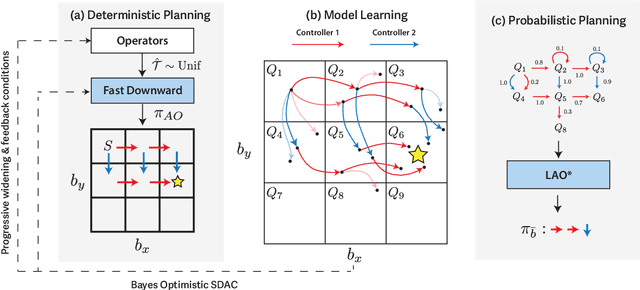
Integrated task and motion planning (TAMP) has proven to be a valuable approach to generalizable long-horizon robotic manipulation and navigation problems. However, the typical TAMP problem formulation assumes full observability and deterministic action effects. These assumptions limit the ability of the planner to gather information and make decisions that are risk-aware. We propose a strategy for TAMP with Uncertainty and Risk Awareness (TAMPURA) that is capable of efficiently solving long-horizon planning problems with initial-state and action outcome uncertainty, including problems that require information gathering and avoiding undesirable and irreversible outcomes. Our planner reasons under uncertainty at both the abstract task level and continuous controller level. Given a set of closed-loop goal-conditioned controllers operating in the primitive action space and a description of their preconditions and potential capabilities, we learn a high-level abstraction that can be solved efficiently and then refined to continuous actions for execution. We demonstrate our approach on several robotics problems where uncertainty is a crucial factor and show that reasoning under uncertainty in these problems outperforms previously proposed determinized planning, direct search, and reinforcement learning strategies. Lastly, we demonstrate our planner on two real-world robotics problems using recent advancements in probabilistic perception.
Practice Makes Perfect: Planning to Learn Skill Parameter Policies
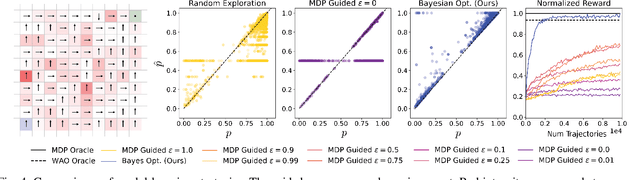
Feb 22, 2024One promising approach towards effective robot decision making in complex, long-horizon tasks is to sequence together parameterized skills. We consider a setting where a robot is initially equipped with (1) a library of parameterized skills, (2) an AI planner for sequencing together the skills given a goal, and (3) a very general prior distribution for selecting skill parameters. Once deployed, the robot should rapidly and autonomously learn to improve its performance by specializing its skill parameter selection policy to the particular objects, goals, and constraints in its environment. In this work, we focus on the active learning problem of choosing which skills to practice to maximize expected future task success. We propose that the robot should estimate the competence of each skill, extrapolate the competence (asking: "how much would the competence improve through practice?"), and situate the skill in the task distribution through competence-aware planning. This approach is implemented within a fully autonomous system where the robot repeatedly plans, practices, and learns without any environment resets. Through experiments in simulation, we find that our approach learns effective parameter policies more sample-efficiently than several baselines. Experiments in the real-world demonstrate our approach's ability to handle noise from perception and control and improve the robot's ability to solve two long-horizon mobile-manipulation tasks after a few hours of autonomous practice.
What Planning Problems Can A Relational Neural Network Solve?
Dec 06, 2023Goal-conditioned policies are generally understood to be "feed-forward" circuits, in the form of neural networks that map from the current state and the goal specification to the next action to take. However, under what circumstances such a policy can be learned and how efficient the policy will be are not well understood. In this paper, we present a circuit complexity analysis for relational neural networks (such as graph neural networks and transformers) representing policies for planning problems, by drawing connections with serialized goal regression search (S-GRS). We show that there are three general classes of planning problems, in terms of the growth of circuit width and depth as a function of the number of objects and planning horizon, providing constructive proofs. We also illustrate the utility of this analysis for designing neural networks for policy learning.
Learning Reusable Manipulation Strategies
Nov 06, 2023Humans demonstrate an impressive ability to acquire and generalize manipulation "tricks." Even from a single demonstration, such as using soup ladles to reach for distant objects, we can apply this skill to new scenarios involving different object positions, sizes, and categories (e.g., forks and hammers). Additionally, we can flexibly combine various skills to devise long-term plans. In this paper, we present a framework that enables machines to acquire such manipulation skills, referred to as "mechanisms," through a single demonstration and self-play. Our key insight lies in interpreting each demonstration as a sequence of changes in robot-object and object-object contact modes, which provides a scaffold for learning detailed samplers for continuous parameters. These learned mechanisms and samplers can be seamlessly integrated into standard task and motion planners, enabling their compositional use.
Neural Relational Inference with Fast Modular Meta-learning
Oct 10, 2023
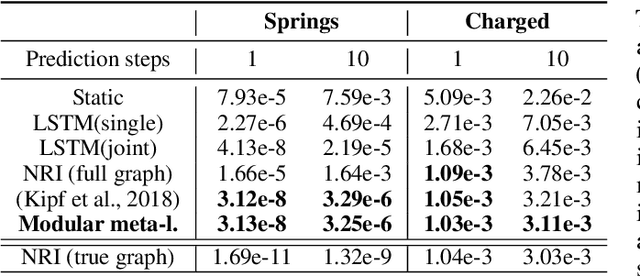

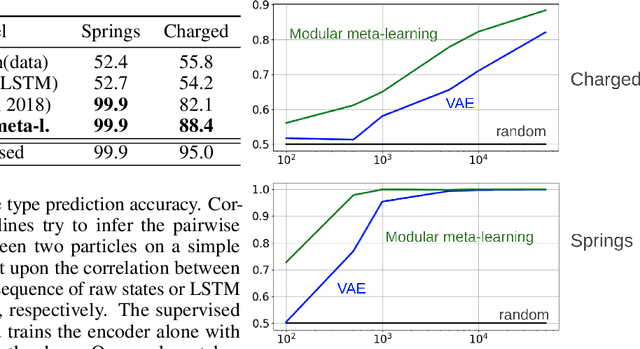
\textit{Graph neural networks} (GNNs) are effective models for many dynamical systems consisting of entities and relations. Although most GNN applications assume a single type of entity and relation, many situations involve multiple types of interactions. \textit{Relational inference} is the problem of inferring these interactions and learning the dynamics from observational data. We frame relational inference as a \textit{modular meta-learning} problem, where neural modules are trained to be composed in different ways to solve many tasks. This meta-learning framework allows us to implicitly encode time invariance and infer relations in context of one another rather than independently, which increases inference capacity. Framing inference as the inner-loop optimization of meta-learning leads to a model-based approach that is more data-efficient and capable of estimating the state of entities that we do not observe directly, but whose existence can be inferred from their effect on observed entities. To address the large search space of graph neural network compositions, we meta-learn a \textit{proposal function} that speeds up the inner-loop simulated annealing search within the modular meta-learning algorithm, providing two orders of magnitude increase in the size of problems that can be addressed.
Compositional Diffusion-Based Continuous Constraint Solvers
Sep 02, 2023This paper introduces an approach for learning to solve continuous constraint satisfaction problems (CCSP) in robotic reasoning and planning. Previous methods primarily rely on hand-engineering or learning generators for specific constraint types and then rejecting the value assignments when other constraints are violated. By contrast, our model, the compositional diffusion continuous constraint solver (Diffusion-CCSP) derives global solutions to CCSPs by representing them as factor graphs and combining the energies of diffusion models trained to sample for individual constraint types. Diffusion-CCSP exhibits strong generalization to novel combinations of known constraints, and it can be integrated into a task and motion planner to devise long-horizon plans that include actions with both discrete and continuous parameters. Project site: https://diffusion-ccsp.github.io/
Distilled Feature Fields Enable Few-Shot Language-Guided Manipulation
Jul 27, 2023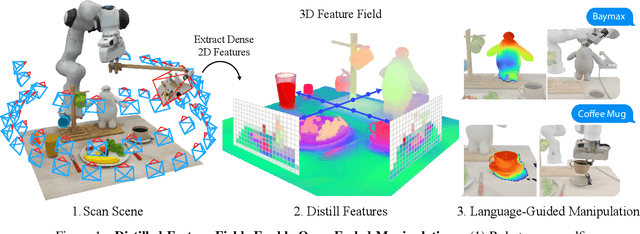
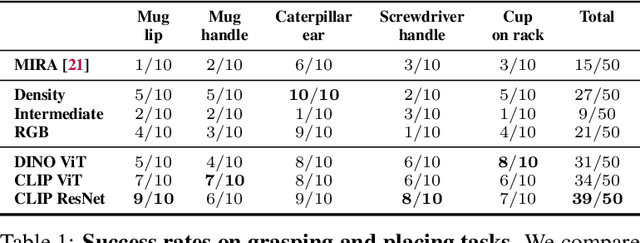
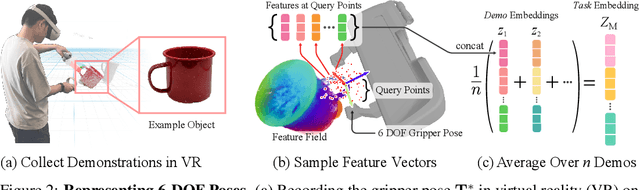
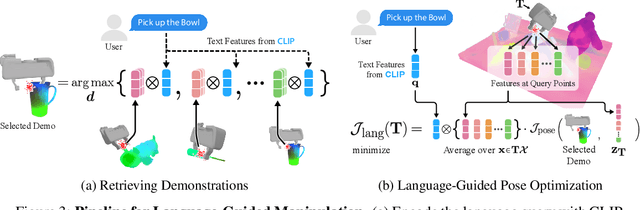
Self-supervised and language-supervised image models contain rich knowledge of the world that is important for generalization. Many robotic tasks, however, require a detailed understanding of 3D geometry, which is often lacking in 2D image features. This work bridges this 2D-to-3D gap for robotic manipulation by leveraging distilled feature fields to combine accurate 3D geometry with rich semantics from 2D foundation models. We present a few-shot learning method for 6-DOF grasping and placing that harnesses these strong spatial and semantic priors to achieve in-the-wild generalization to unseen objects. Using features distilled from a vision-language model, CLIP, we present a way to designate novel objects for manipulation via free-text natural language, and demonstrate its ability to generalize to unseen expressions and novel categories of objects.
Embodied Lifelong Learning for Task and Motion Planning
Jul 13, 2023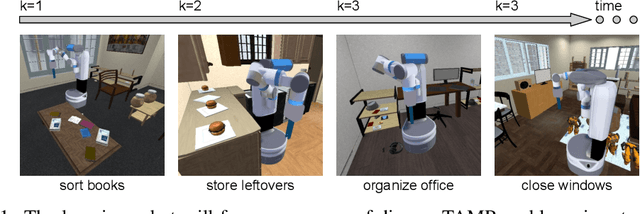
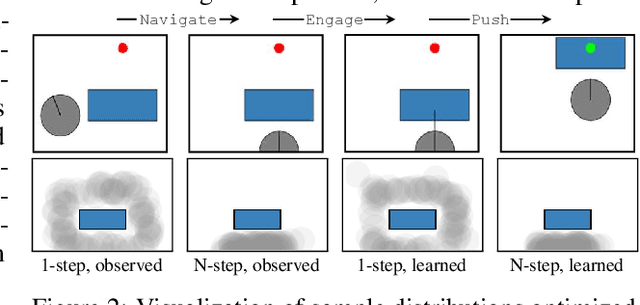
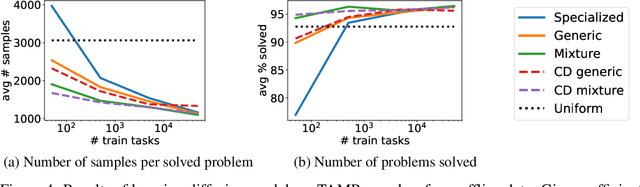
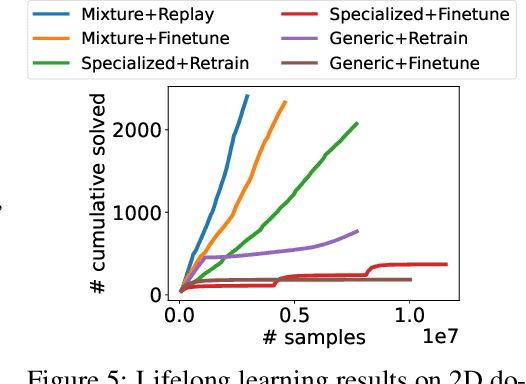
A robot deployed in a home over long stretches of time faces a true lifelong learning problem. As it seeks to provide assistance to its users, the robot should leverage any accumulated experience to improve its own knowledge to become a more proficient assistant. We formalize this setting with a novel lifelong learning problem formulation in the context of learning for task and motion planning (TAMP). Exploiting the modularity of TAMP systems, we develop a generative mixture model that produces candidate continuous parameters for a planner. Whereas most existing lifelong learning approaches determine a priori how data is shared across task models, our approach learns shared and non-shared models and determines which to use online during planning based on auxiliary tasks that serve as a proxy for each model's understanding of a state. Our method exhibits substantial improvements in planning success on simulated 2D domains and on several problems from the BEHAVIOR benchmark.
DiMSam: Diffusion Models as Samplers for Task and Motion Planning under Partial Observability
Jun 22, 2023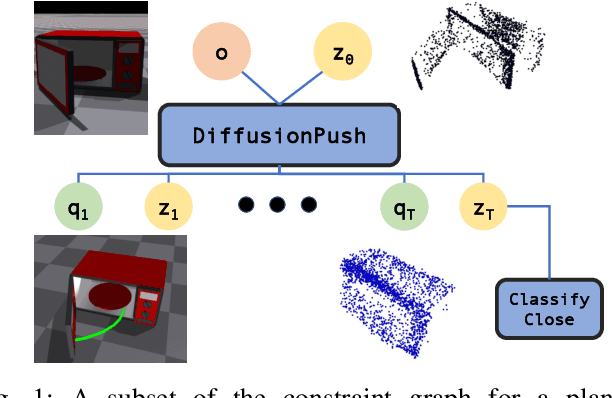
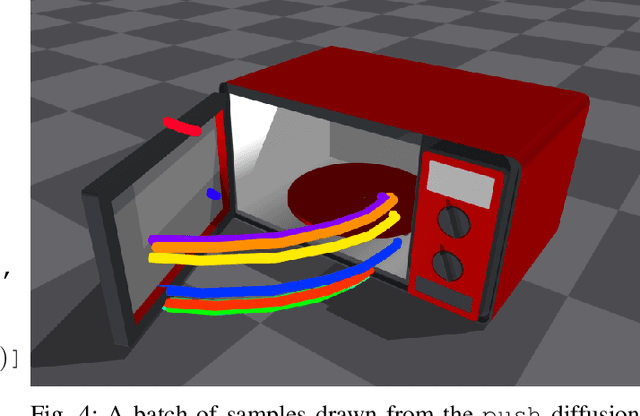


Task and Motion Planning (TAMP) approaches are effective at planning long-horizon autonomous robot manipulation. However, because they require a planning model, it can be difficult to apply them to domains where the environment and its dynamics are not fully known. We propose to overcome these limitations by leveraging deep generative modeling, specifically diffusion models, to learn constraints and samplers that capture these difficult-to-engineer aspects of the planning model. These learned samplers are composed and combined within a TAMP solver in order to find action parameter values jointly that satisfy the constraints along a plan. To tractably make predictions for unseen objects in the environment, we define these samplers on low-dimensional learned latent embeddings of changing object state. We evaluate our approach in an articulated object manipulation domain and show how the combination of classical TAMP, generative learning, and latent embeddings enables long-horizon constraint-based reasoning.
Generalized Planning in PDDL Domains with Pretrained Large Language Models
May 18, 2023
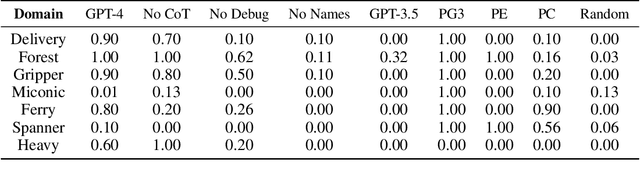
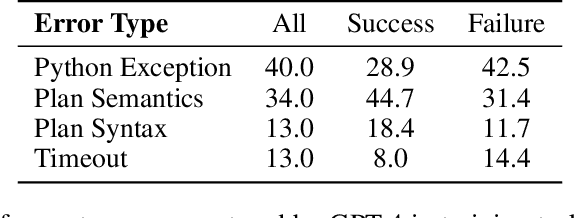
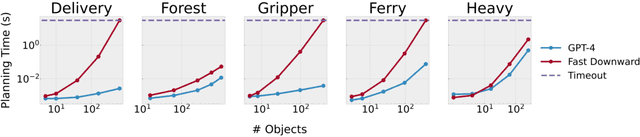
Recent work has considered whether large language models (LLMs) can function as planners: given a task, generate a plan. We investigate whether LLMs can serve as generalized planners: given a domain and training tasks, generate a program that efficiently produces plans for other tasks in the domain. In particular, we consider PDDL domains and use GPT-4 to synthesize Python programs. We also consider (1) Chain-of-Thought (CoT) summarization, where the LLM is prompted to summarize the domain and propose a strategy in words before synthesizing the program; and (2) automated debugging, where the program is validated with respect to the training tasks, and in case of errors, the LLM is re-prompted with four types of feedback. We evaluate this approach in seven PDDL domains and compare it to four ablations and four baselines. Overall, we find that GPT-4 is a surprisingly powerful generalized planner. We also conclude that automated debugging is very important, that CoT summarization has non-uniform impact, that GPT-4 is far superior to GPT-3.5, and that just two training tasks are often sufficient for strong generalization.