 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGe Yang
Feature Splatting: Language-Driven Physics-Based Scene Synthesis and Editing
Apr 01, 2024
Scene representations using 3D Gaussian primitives have produced excellent results in modeling the appearance of static and dynamic 3D scenes. Many graphics applications, however, demand the ability to manipulate both the appearance and the physical properties of objects. We introduce Feature Splatting, an approach that unifies physics-based dynamic scene synthesis with rich semantics from vision language foundation models that are grounded by natural language. Our first contribution is a way to distill high-quality, object-centric vision-language features into 3D Gaussians, that enables semi-automatic scene decomposition using text queries. Our second contribution is a way to synthesize physics-based dynamics from an otherwise static scene using a particle-based simulator, in which material properties are assigned automatically via text queries. We ablate key techniques used in this pipeline, to illustrate the challenge and opportunities in using feature-carrying 3D Gaussians as a unified format for appearance, geometry, material properties and semantics grounded on natural language. Project website: https://feature-splatting.github.io/
Learning Generalizable Feature Fields for Mobile Manipulation
Mar 12, 2024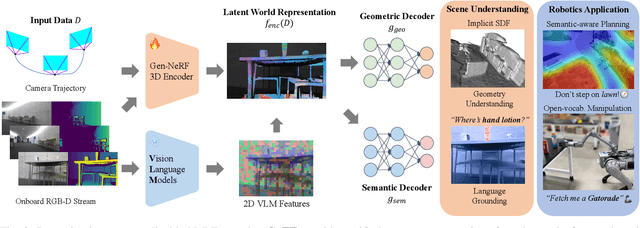


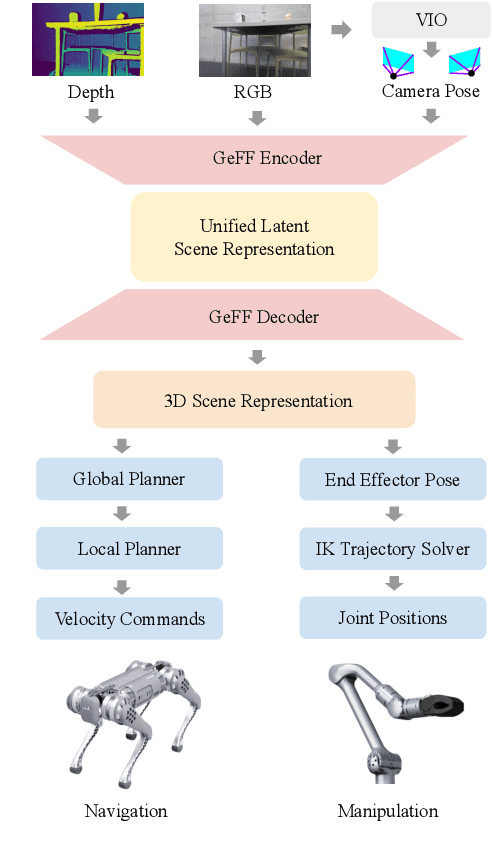
An open problem in mobile manipulation is how to represent objects and scenes in a unified manner, so that robots can use it both for navigating in the environment and manipulating objects. The latter requires capturing intricate geometry while understanding fine-grained semantics, whereas the former involves capturing the complexity inherit to an expansive physical scale. In this work, we present GeFF (Generalizable Feature Fields), a scene-level generalizable neural feature field that acts as a unified representation for both navigation and manipulation that performs in real-time. To do so, we treat generative novel view synthesis as a pre-training task, and then align the resulting rich scene priors with natural language via CLIP feature distillation. We demonstrate the effectiveness of this approach by deploying GeFF on a quadrupedal robot equipped with a manipulator. We evaluate GeFF's ability to generalize to open-set objects as well as running time, when performing open-vocabulary mobile manipulation in dynamic scenes.
Expressive Whole-Body Control for Humanoid Robots
Mar 06, 2024Can we enable humanoid robots to generate rich, diverse, and expressive motions in the real world? We propose to learn a whole-body control policy on a human-sized robot to mimic human motions as realistic as possible. To train such a policy, we leverage the large-scale human motion capture data from the graphics community in a Reinforcement Learning framework. However, directly performing imitation learning with the motion capture dataset would not work on the real humanoid robot, given the large gap in degrees of freedom and physical capabilities. Our method Expressive Whole-Body Control (Exbody) tackles this problem by encouraging the upper humanoid body to imitate a reference motion, while relaxing the imitation constraint on its two legs and only requiring them to follow a given velocity robustly. With training in simulation and Sim2Real transfer, our policy can control a humanoid robot to walk in different styles, shake hands with humans, and even dance with a human in the real world. We conduct extensive studies and comparisons on diverse motions in both simulation and the real world to show the effectiveness of our approach.
Robust Source-Free Domain Adaptation for Fundus Image Segmentation
Oct 25, 2023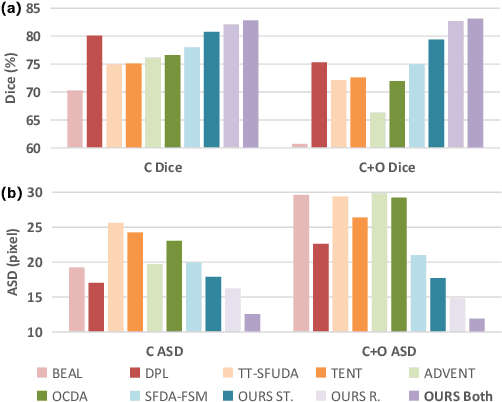

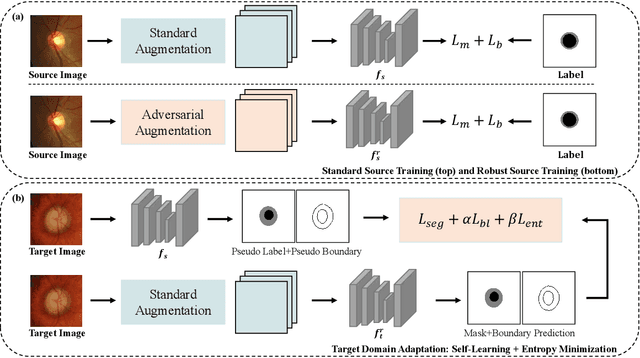
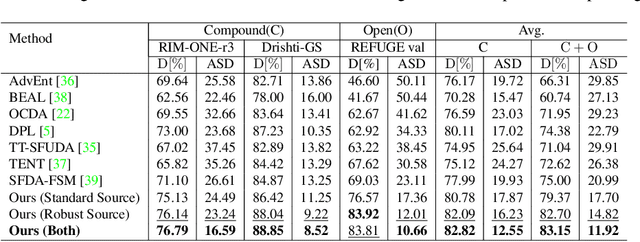
Unsupervised Domain Adaptation (UDA) is a learning technique that transfers knowledge learned in the source domain from labelled training data to the target domain with only unlabelled data. It is of significant importance to medical image segmentation because of the usual lack of labelled training data. Although extensive efforts have been made to optimize UDA techniques to improve the accuracy of segmentation models in the target domain, few studies have addressed the robustness of these models under UDA. In this study, we propose a two-stage training strategy for robust domain adaptation. In the source training stage, we utilize adversarial sample augmentation to enhance the robustness and generalization capability of the source model. And in the target training stage, we propose a novel robust pseudo-label and pseudo-boundary (PLPB) method, which effectively utilizes unlabeled target data to generate pseudo labels and pseudo boundaries that enable model self-adaptation without requiring source data. Extensive experimental results on cross-domain fundus image segmentation confirm the effectiveness and versatility of our method. Source code of this study is openly accessible at https://github.com/LinGrayy/PLPB.
Compositional Sculpting of Iterative Generative Processes
Sep 28, 2023High training costs of generative models and the need to fine-tune them for specific tasks have created a strong interest in model reuse and composition. A key challenge in composing iterative generative processes, such as GFlowNets and diffusion models, is that to realize the desired target distribution, all steps of the generative process need to be coordinated, and satisfy delicate balance conditions. In this work, we propose Compositional Sculpting: a general approach for defining compositions of iterative generative processes. We then introduce a method for sampling from these compositions built on classifier guidance. We showcase ways to accomplish compositional sculpting in both GFlowNets and diffusion models. We highlight two binary operations $\unicode{x2014}$ the harmonic mean ($p_1 \otimes p_2$) and the contrast ($p_1 \unicode{x25D1}\,p_2$) between pairs, and the generalization of these operations to multiple component distributions. We offer empirical results on image and molecular generation tasks.
ADFA: Attention-augmented Differentiable top-k Feature Adaptation for Unsupervised Medical Anomaly Detection
Aug 29, 2023


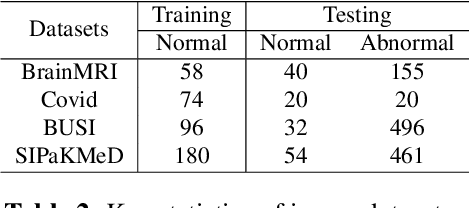
The scarcity of annotated data, particularly for rare diseases, limits the variability of training data and the range of detectable lesions, presenting a significant challenge for supervised anomaly detection in medical imaging. To solve this problem, we propose a novel unsupervised method for medical image anomaly detection: Attention-Augmented Differentiable top-k Feature Adaptation (ADFA). The method utilizes Wide-ResNet50-2 (WR50) network pre-trained on ImageNet to extract initial feature representations. To reduce the channel dimensionality while preserving relevant channel information, we employ an attention-augmented patch descriptor on the extracted features. We then apply differentiable top-k feature adaptation to train the patch descriptor, mapping the extracted feature representations to a new vector space, enabling effective detection of anomalies. Experiments show that ADFA outperforms state-of-the-art (SOTA) methods on multiple challenging medical image datasets, confirming its effectiveness in medical anomaly detection.
Improving Generalization of Adversarial Training via Robust Critical Fine-Tuning
Aug 01, 2023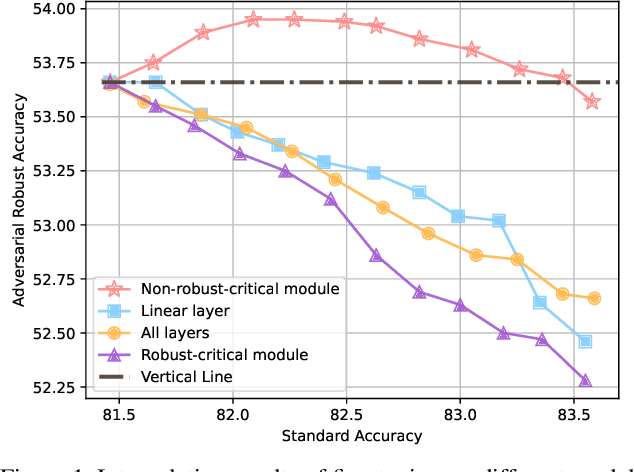
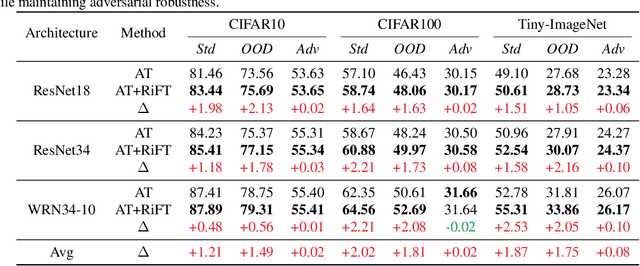
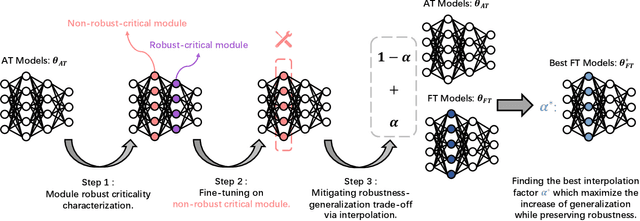

Deep neural networks are susceptible to adversarial examples, posing a significant security risk in critical applications. Adversarial Training (AT) is a well-established technique to enhance adversarial robustness, but it often comes at the cost of decreased generalization ability. This paper proposes Robustness Critical Fine-Tuning (RiFT), a novel approach to enhance generalization without compromising adversarial robustness. The core idea of RiFT is to exploit the redundant capacity for robustness by fine-tuning the adversarially trained model on its non-robust-critical module. To do so, we introduce module robust criticality (MRC), a measure that evaluates the significance of a given module to model robustness under worst-case weight perturbations. Using this measure, we identify the module with the lowest MRC value as the non-robust-critical module and fine-tune its weights to obtain fine-tuned weights. Subsequently, we linearly interpolate between the adversarially trained weights and fine-tuned weights to derive the optimal fine-tuned model weights. We demonstrate the efficacy of RiFT on ResNet18, ResNet34, and WideResNet34-10 models trained on CIFAR10, CIFAR100, and Tiny-ImageNet datasets. Our experiments show that \method can significantly improve both generalization and out-of-distribution robustness by around 1.5% while maintaining or even slightly enhancing adversarial robustness. Code is available at https://github.com/microsoft/robustlearn.
Distilled Feature Fields Enable Few-Shot Language-Guided Manipulation
Jul 27, 2023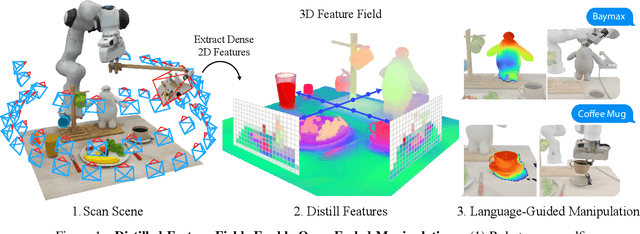
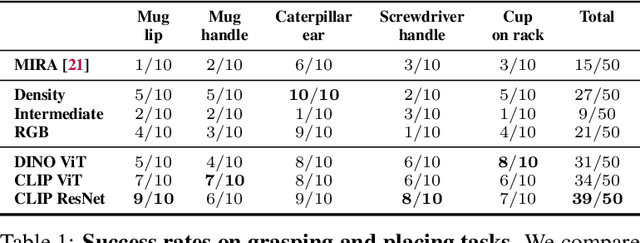
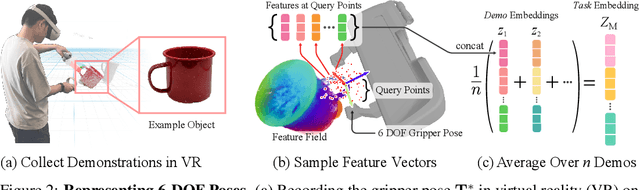
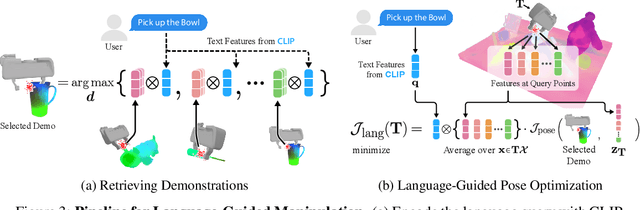
Self-supervised and language-supervised image models contain rich knowledge of the world that is important for generalization. Many robotic tasks, however, require a detailed understanding of 3D geometry, which is often lacking in 2D image features. This work bridges this 2D-to-3D gap for robotic manipulation by leveraging distilled feature fields to combine accurate 3D geometry with rich semantics from 2D foundation models. We present a few-shot learning method for 6-DOF grasping and placing that harnesses these strong spatial and semantic priors to achieve in-the-wild generalization to unseen objects. Using features distilled from a vision-language model, CLIP, we present a way to designate novel objects for manipulation via free-text natural language, and demonstrate its ability to generalize to unseen expressions and novel categories of objects.
PKU-GoodsAD: A Supermarket Goods Dataset for Unsupervised Anomaly Detection and Segmentation
Jul 26, 2023

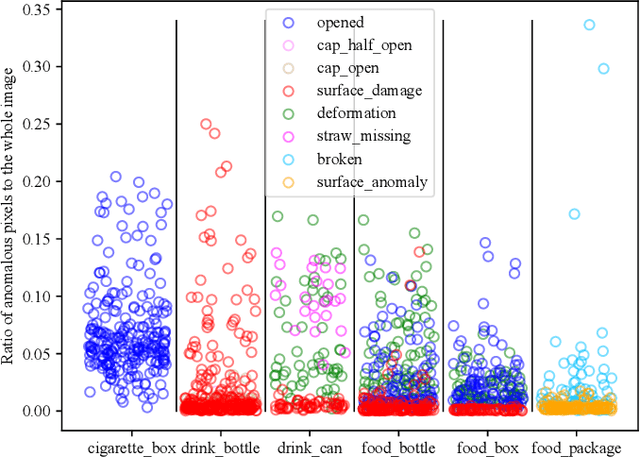
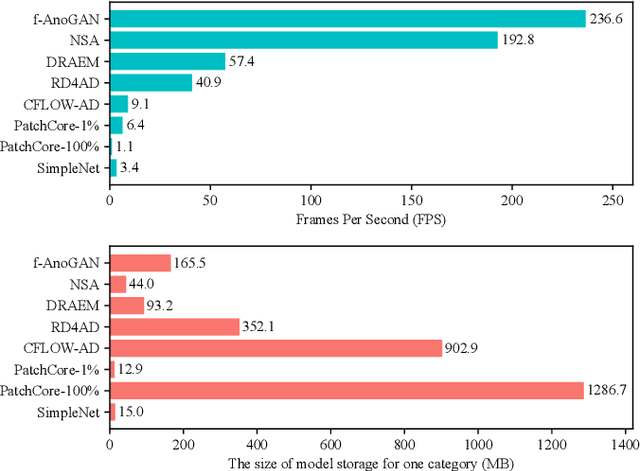
Visual anomaly detection is essential and commonly used for many tasks in the field of computer vision. Recent anomaly detection datasets mainly focus on industrial automated inspection, medical image analysis and video surveillance. In order to broaden the application and research of anomaly detection in unmanned supermarkets and smart manufacturing, we introduce the supermarket goods anomaly detection (GoodsAD) dataset. It contains 6124 high-resolution images of 484 different appearance goods divided into 6 categories. Each category contains several common different types of anomalies such as deformation, surface damage and opened. Anomalies contain both texture changes and structural changes. It follows the unsupervised setting and only normal (defect-free) images are used for training. Pixel-precise ground truth regions are provided for all anomalies. Moreover, we also conduct a thorough evaluation of current state-of-the-art unsupervised anomaly detection methods. This initial benchmark indicates that some methods which perform well on the industrial anomaly detection dataset (e.g., MVTec AD), show poor performance on our dataset. This is a comprehensive, multi-object dataset for supermarket goods anomaly detection that focuses on real-world applications.
Neural Volumetric Memory for Visual Locomotion Control
Apr 03, 2023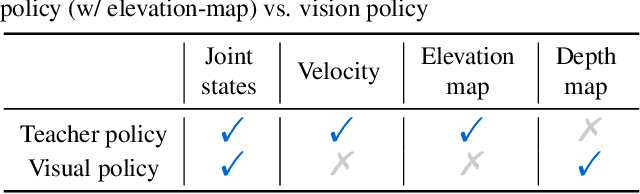

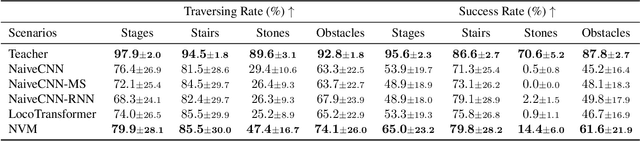
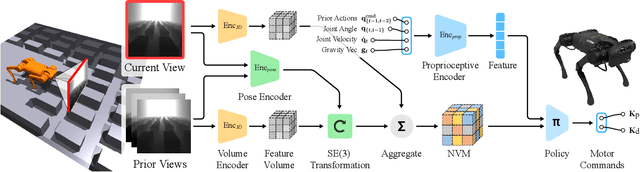
Legged robots have the potential to expand the reach of autonomy beyond paved roads. In this work, we consider the difficult problem of locomotion on challenging terrains using a single forward-facing depth camera. Due to the partial observability of the problem, the robot has to rely on past observations to infer the terrain currently beneath it. To solve this problem, we follow the paradigm in computer vision that explicitly models the 3D geometry of the scene and propose Neural Volumetric Memory (NVM), a geometric memory architecture that explicitly accounts for the SE(3) equivariance of the 3D world. NVM aggregates feature volumes from multiple camera views by first bringing them back to the ego-centric frame of the robot. We test the learned visual-locomotion policy on a physical robot and show that our approach, which explicitly introduces geometric priors during training, offers superior performance than more na\"ive methods. We also include ablation studies and show that the representations stored in the neural volumetric memory capture sufficient geometric information to reconstruct the scene. Our project page with videos is https://rchalyang.github.io/NVM .