 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLiangliang Zhao
Transformer-Enhanced Motion Planner: Attention-Guided Sampling for State-Specific Decision Making
Apr 30, 2024
Sampling-based motion planning (SBMP) algorithms are renowned for their robust global search capabilities. However, the inherent randomness in their sampling mechanisms often result in inconsistent path quality and limited search efficiency. In response to these challenges, this work proposes a novel deep learning-based motion planning framework, named Transformer-Enhanced Motion Planner (TEMP), which synergizes an Environmental Information Semantic Encoder (EISE) with a Motion Planning Transformer (MPT). EISE converts environmental data into semantic environmental information (SEI), providing MPT with an enriched environmental comprehension. MPT leverages an attention mechanism to dynamically recalibrate its focus on SEI, task objectives, and historical planning data, refining the sampling node generation. To demonstrate the capabilities of TEMP, we train our model using a dataset comprised of planning results produced by the RRT*. EISE and MPT are collaboratively trained, enabling EISE to autonomously learn and extract patterns from environmental data, thereby forming semantic representations that MPT could more effectively interpret and utilize for motion planning. Subsequently, we conducted a systematic evaluation of TEMP's efficacy across diverse task dimensions, which demonstrates that TEMP achieves exceptional performance metrics and a heightened degree of generalizability compared to state-of-the-art SBMPs.
NWPU-MOC: A Benchmark for Fine-grained Multi-category Object Counting in Aerial Images
Jan 19, 2024Object counting is a hot topic in computer vision, which aims to estimate the number of objects in a given image. However, most methods only count objects of a single category for an image, which cannot be applied to scenes that need to count objects with multiple categories simultaneously, especially in aerial scenes. To this end, this paper introduces a Multi-category Object Counting (MOC) task to estimate the numbers of different objects (cars, buildings, ships, etc.) in an aerial image. Considering the absence of a dataset for this task, a large-scale Dataset (NWPU-MOC) is collected, consisting of 3,416 scenes with a resolution of 1024 $\times$ 1024 pixels, and well-annotated using 14 fine-grained object categories. Besides, each scene contains RGB and Near Infrared (NIR) images, of which the NIR spectrum can provide richer characterization information compared with only the RGB spectrum. Based on NWPU-MOC, the paper presents a multi-spectrum, multi-category object counting framework, which employs a dual-attention module to fuse the features of RGB and NIR and subsequently regress multi-channel density maps corresponding to each object category. In addition, to modeling the dependency between different channels in the density map with each object category, a spatial contrast loss is designed as a penalty for overlapping predictions at the same spatial position. Experimental results demonstrate that the proposed method achieves state-of-the-art performance compared with some mainstream counting algorithms. The dataset, code and models are publicly available at https://github.com/lyongo/NWPU-MOC.
Collision-Free Kinematics for Redundant Manipulators in Dynamic Scenes using Optimal Reciprocal Velocity Obstacles
Mar 09, 2019
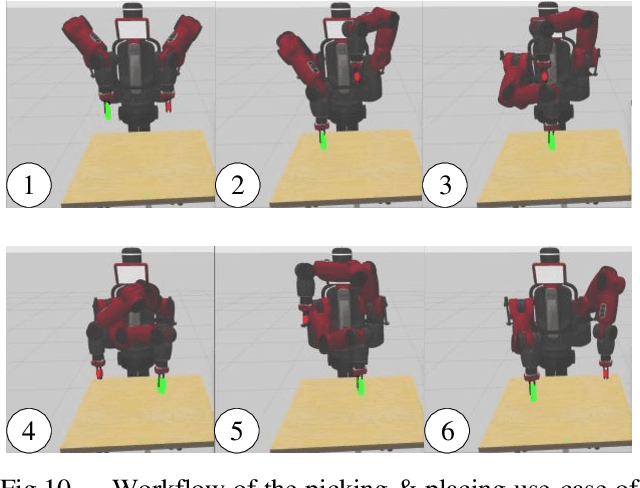
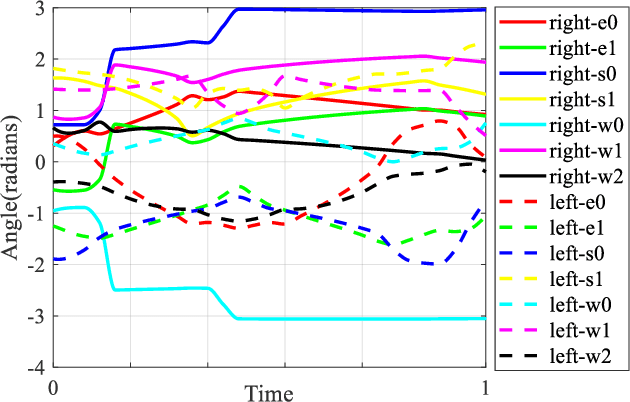
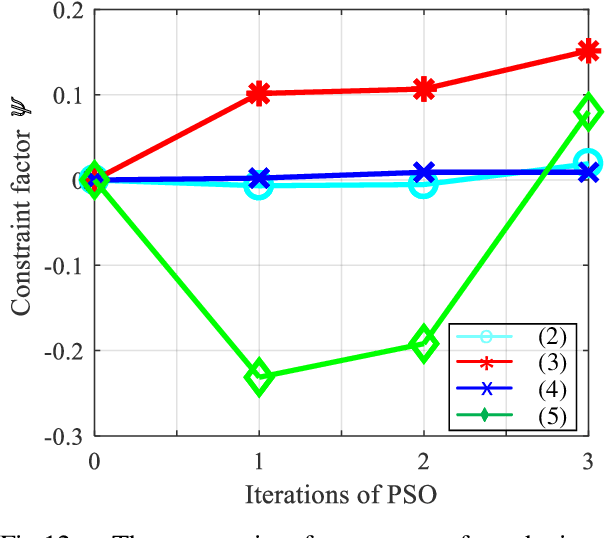
We present a novel algorithm for collision-free kinematics of multiple manipulators in a shared workspace with moving obstacles. Our optimization-based approach simultaneously handles collision-free constraints based on reciprocal velocity obstacles and inverse kinematics constraints for high-DOF manipulators. We present an efficient method based on particle swarm optimization that can generate collision-free configurations for each redundant manipulator. Furthermore, our approach can be used to compute safe and oscillation-free trajectories in a few milli-seconds. We highlight the real-time performance of our algorithm on multiple Baxter robots with 14-DOF manipulators operating in a workspace with dynamic obstacles. Videos are available at https://sites.google.com/view/collision-free-kinematics