 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLichi Zhang
Two-stage Cytopathological Image Synthesis for Augmenting Cervical Abnormality Screening
Feb 25, 2024
Automatic thin-prep cytologic test (TCT) screening can assist pathologists in finding cervical abnormality towards accurate and efficient cervical cancer diagnosis. Current automatic TCT screening systems mostly involve abnormal cervical cell detection, which generally requires large-scale and diverse training data with high-quality annotations to achieve promising performance. Pathological image synthesis is naturally raised to minimize the efforts in data collection and annotation. However, it is challenging to generate realistic large-size cytopathological images while simultaneously synthesizing visually plausible appearances for small-size abnormal cervical cells. In this paper, we propose a two-stage image synthesis framework to create synthetic data for augmenting cervical abnormality screening. In the first Global Image Generation stage, a Normal Image Generator is designed to generate cytopathological images full of normal cervical cells. In the second Local Cell Editing stage, normal cells are randomly selected from the generated images and then are converted to different types of abnormal cells using the proposed Abnormal Cell Synthesizer. Both Normal Image Generator and Abnormal Cell Synthesizer are built upon Stable Diffusion, a pre-trained foundation model for image synthesis, via parameter-efficient fine-tuning methods for customizing cytopathological image contents and extending spatial layout controllability, respectively. Our experiments demonstrate the synthetic image quality, diversity, and controllability of the proposed synthesis framework, and validate its data augmentation effectiveness in enhancing the performance of abnormal cervical cell detection.
Uni-COAL: A Unified Framework for Cross-Modality Synthesis and Super-Resolution of MR Images
Nov 14, 2023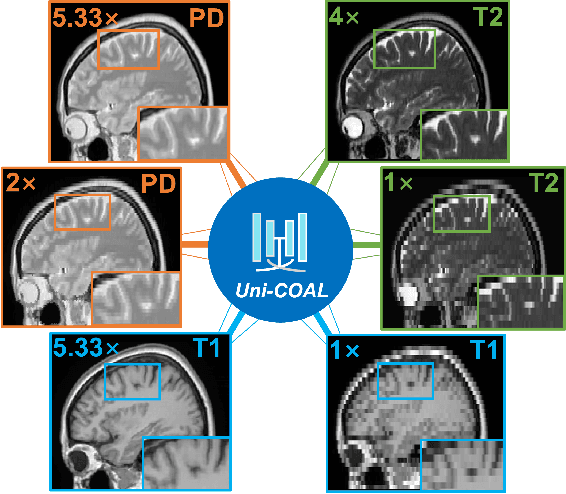
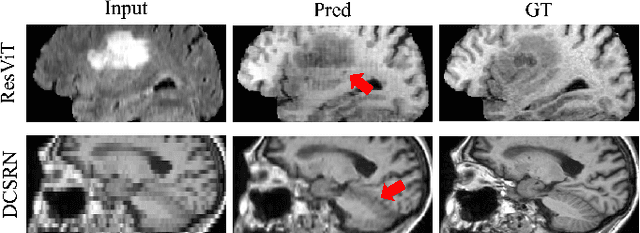
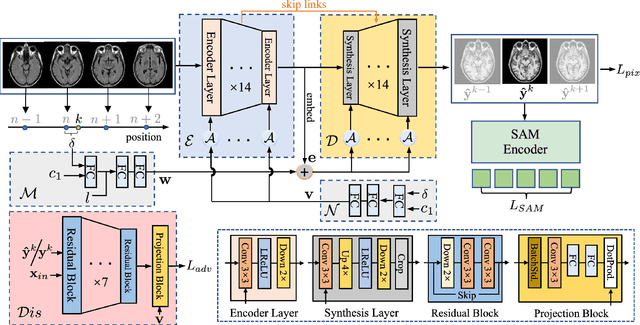
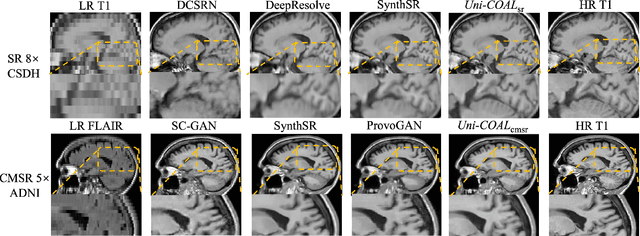
Cross-modality synthesis (CMS), super-resolution (SR), and their combination (CMSR) have been extensively studied for magnetic resonance imaging (MRI). Their primary goals are to enhance the imaging quality by synthesizing the desired modality and reducing the slice thickness. Despite the promising synthetic results, these techniques are often tailored to specific tasks, thereby limiting their adaptability to complex clinical scenarios. Therefore, it is crucial to build a unified network that can handle various image synthesis tasks with arbitrary requirements of modality and resolution settings, so that the resources for training and deploying the models can be greatly reduced. However, none of the previous works is capable of performing CMS, SR, and CMSR using a unified network. Moreover, these MRI reconstruction methods often treat alias frequencies improperly, resulting in suboptimal detail restoration. In this paper, we propose a Unified Co-Modulated Alias-free framework (Uni-COAL) to accomplish the aforementioned tasks with a single network. The co-modulation design of the image-conditioned and stochastic attribute representations ensures the consistency between CMS and SR, while simultaneously accommodating arbitrary combinations of input/output modalities and thickness. The generator of Uni-COAL is also designed to be alias-free based on the Shannon-Nyquist signal processing framework, ensuring effective suppression of alias frequencies. Additionally, we leverage the semantic prior of Segment Anything Model (SAM) to guide Uni-COAL, ensuring a more authentic preservation of anatomical structures during synthesis. Experiments on three datasets demonstrate that Uni-COAL outperforms the alternatives in CMS, SR, and CMSR tasks for MR images, which highlights its generalizability to wide-range applications.
Progressive Attention Guidance for Whole Slide Vulvovaginal Candidiasis Screening
Sep 06, 2023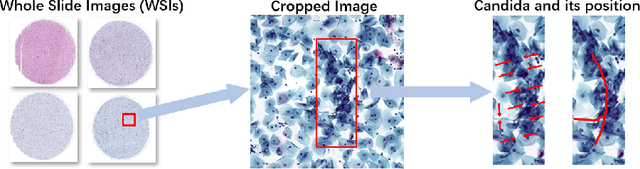
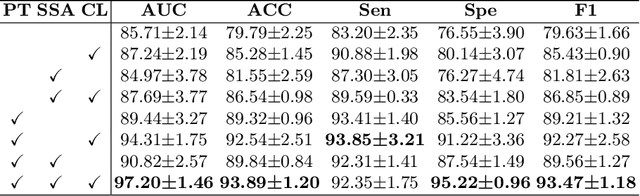
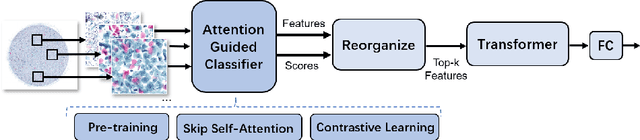
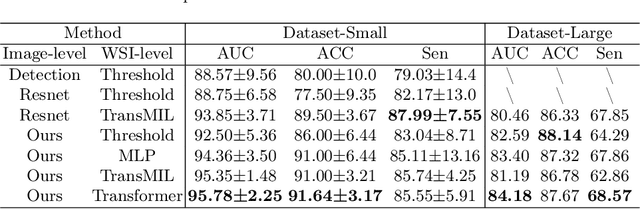
Vulvovaginal candidiasis (VVC) is the most prevalent human candidal infection, estimated to afflict approximately 75% of all women at least once in their lifetime. It will lead to several symptoms including pruritus, vaginal soreness, and so on. Automatic whole slide image (WSI) classification is highly demanded, for the huge burden of disease control and prevention. However, the WSI-based computer-aided VCC screening method is still vacant due to the scarce labeled data and unique properties of candida. Candida in WSI is challenging to be captured by conventional classification models due to its distinctive elongated shape, the small proportion of their spatial distribution, and the style gap from WSIs. To make the model focus on the candida easier, we propose an attention-guided method, which can obtain a robust diagnosis classification model. Specifically, we first use a pre-trained detection model as prior instruction to initialize the classification model. Then we design a Skip Self-Attention module to refine the attention onto the fined-grained features of candida. Finally, we use a contrastive learning method to alleviate the overfitting caused by the style gap of WSIs and suppress the attention to false positive regions. Our experimental results demonstrate that our framework achieves state-of-the-art performance. Code and example data are available at https://github.com/cjdbehumble/MICCAI2023-VVC-Screening.
* Accepted in the main conference MICCAI 2023
AdLER: Adversarial Training with Label Error Rectification for One-Shot Medical Image Segmentation
Sep 02, 2023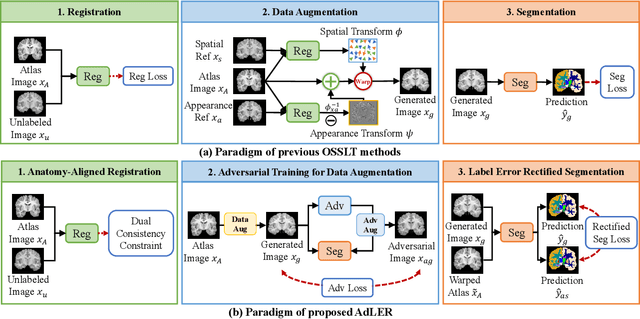
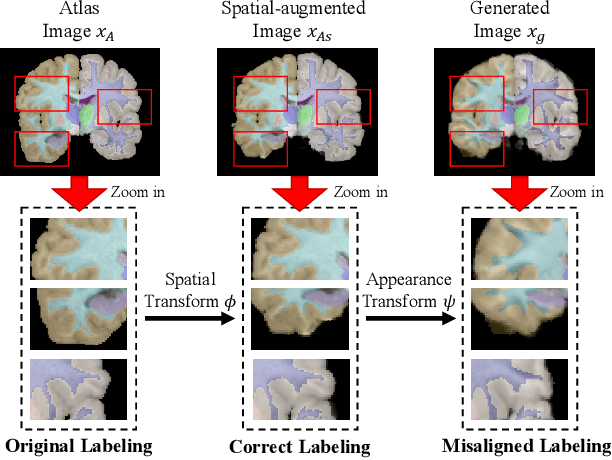
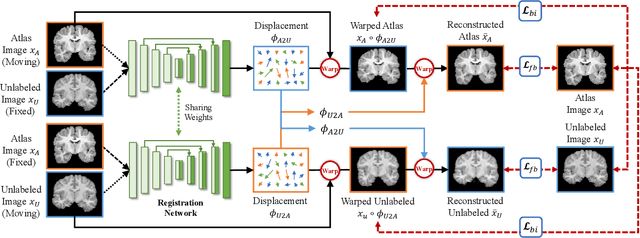
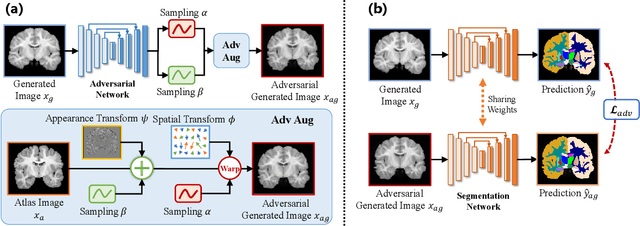
Accurate automatic segmentation of medical images typically requires large datasets with high-quality annotations, making it less applicable in clinical settings due to limited training data. One-shot segmentation based on learned transformations (OSSLT) has shown promise when labeled data is extremely limited, typically including unsupervised deformable registration, data augmentation with learned registration, and segmentation learned from augmented data. However, current one-shot segmentation methods are challenged by limited data diversity during augmentation, and potential label errors caused by imperfect registration. To address these issues, we propose a novel one-shot medical image segmentation method with adversarial training and label error rectification (AdLER), with the aim of improving the diversity of generated data and correcting label errors to enhance segmentation performance. Specifically, we implement a novel dual consistency constraint to ensure anatomy-aligned registration that lessens registration errors. Furthermore, we develop an adversarial training strategy to augment the atlas image, which ensures both generation diversity and segmentation robustness. We also propose to rectify potential label errors in the augmented atlas images by estimating segmentation uncertainty, which can compensate for the imperfect nature of deformable registration and improve segmentation authenticity. Experiments on the CANDI and ABIDE datasets demonstrate that the proposed AdLER outperforms previous state-of-the-art methods by 0.7% (CANDI), 3.6% (ABIDE "seen"), and 4.9% (ABIDE "unseen") in segmentation based on Dice scores, respectively. The source code will be available at https://github.com/hsiangyuzhao/AdLER.
CellGAN: Conditional Cervical Cell Synthesis for Augmenting Cytopathological Image Classification
Jul 12, 2023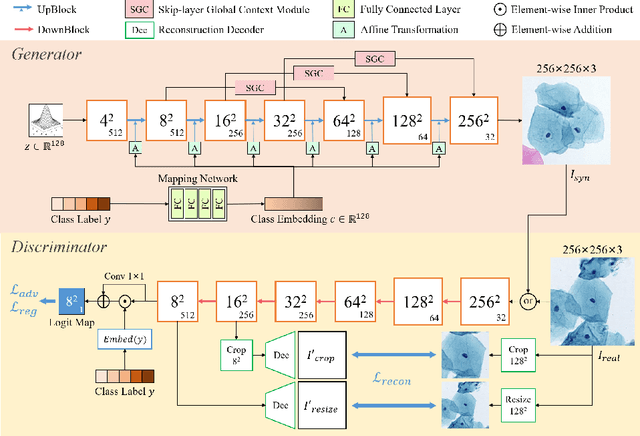

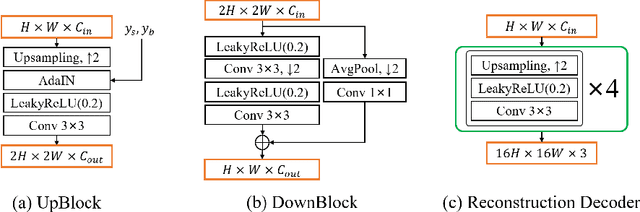
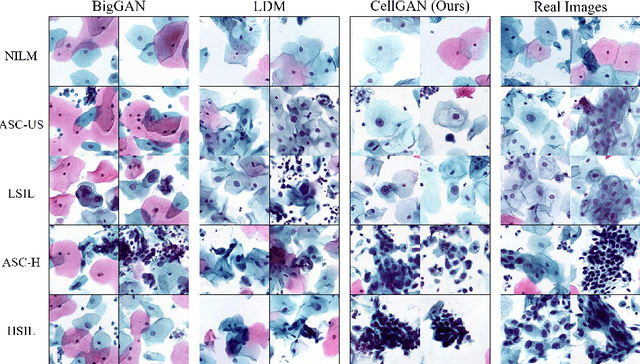
Automatic examination of thin-prep cytologic test (TCT) slides can assist pathologists in finding cervical abnormality for accurate and efficient cancer screening. Current solutions mostly need to localize suspicious cells and classify abnormality based on local patches, concerning the fact that whole slide images of TCT are extremely large. It thus requires many annotations of normal and abnormal cervical cells, to supervise the training of the patch-level classifier for promising performance. In this paper, we propose CellGAN to synthesize cytopathological images of various cervical cell types for augmenting patch-level cell classification. Built upon a lightweight backbone, CellGAN is equipped with a non-linear class mapping network to effectively incorporate cell type information into image generation. We also propose the Skip-layer Global Context module to model the complex spatial relationship of the cells, and attain high fidelity of the synthesized images through adversarial learning. Our experiments demonstrate that CellGAN can produce visually plausible TCT cytopathological images for different cell types. We also validate the effectiveness of using CellGAN to greatly augment patch-level cell classification performance.
CT-based Subchondral Bone Microstructural Analysis in Knee Osteoarthritis via MR-Guided Distillation Learning
Jul 11, 2023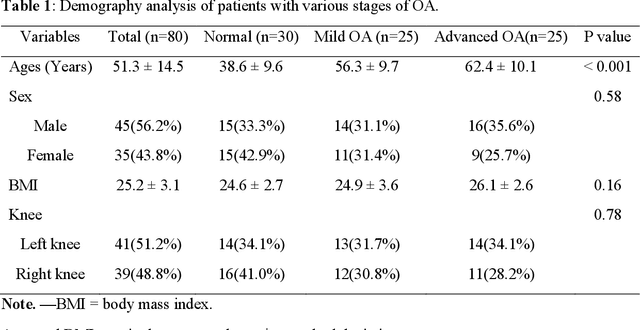

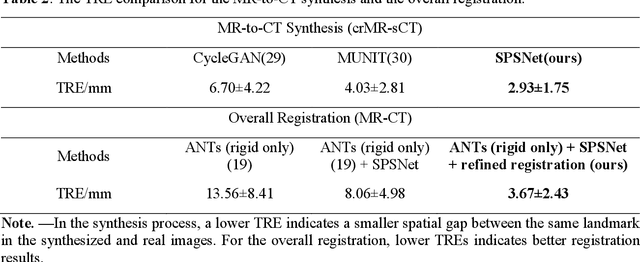
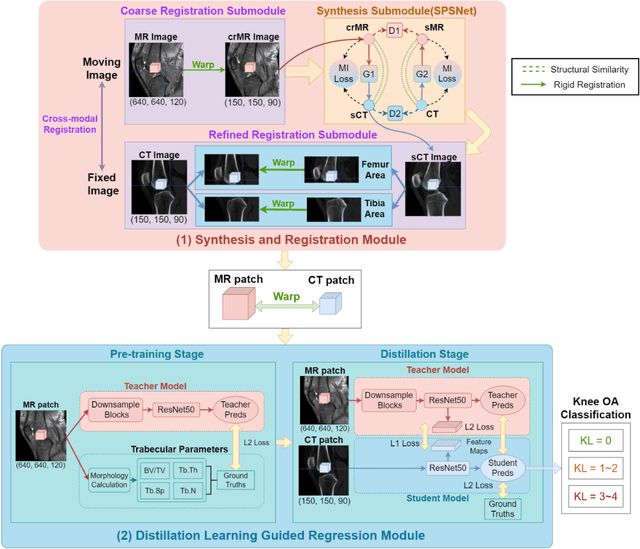
Background: MR-based subchondral bone effectively predicts knee osteoarthritis. However, its clinical application is limited by the cost and time of MR. Purpose: We aim to develop a novel distillation-learning-based method named SRRD for subchondral bone microstructural analysis using easily-acquired CT images, which leverages paired MR images to enhance the CT-based analysis model during training. Materials and Methods: Knee joint images of both CT and MR modalities were collected from October 2020 to May 2021. Firstly, we developed a GAN-based generative model to transform MR images into CT images, which was used to establish the anatomical correspondence between the two modalities. Next, we obtained numerous patches of subchondral bone regions of MR images, together with their trabecular parameters (BV / TV, Tb. Th, Tb. Sp, Tb. N) from the corresponding CT image patches via regression. The distillation-learning technique was used to train the regression model and transfer MR structural information to the CT-based model. The regressed trabecular parameters were further used for knee osteoarthritis classification. Results: A total of 80 participants were evaluated. CT-based regression results of trabecular parameters achieved intra-class correlation coefficients (ICCs) of 0.804, 0.773, 0.711, and 0.622 for BV / TV, Tb. Th, Tb. Sp, and Tb. N, respectively. The use of distillation learning significantly improved the performance of the CT-based knee osteoarthritis classification method using the CNN approach, yielding an AUC score of 0.767 (95% CI, 0.681-0.853) instead of 0.658 (95% CI, 0.574-0.742) (p<.001). Conclusions: The proposed SRRD method showed high reliability and validity in MR-CT registration, regression, and knee osteoarthritis classification, indicating the feasibility of subchondral bone microstructural analysis based on CT images.
Learning Better Contrastive View from Radiologist's Gaze
May 15, 2023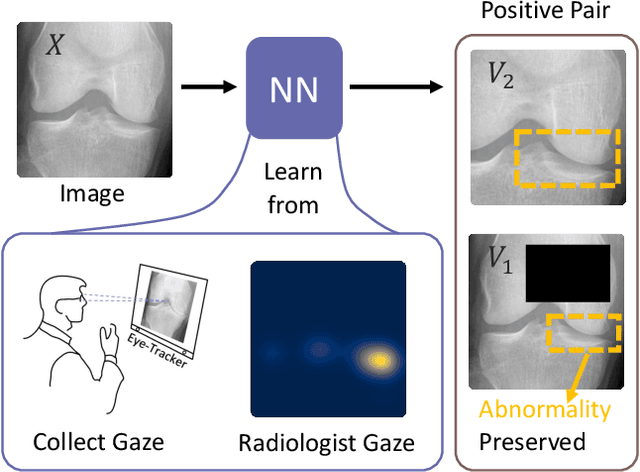
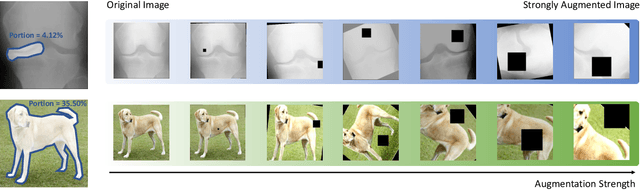
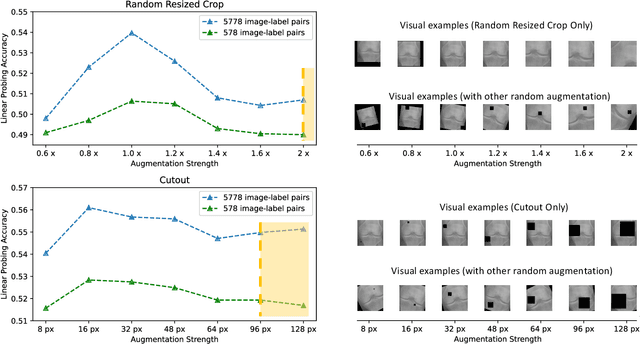
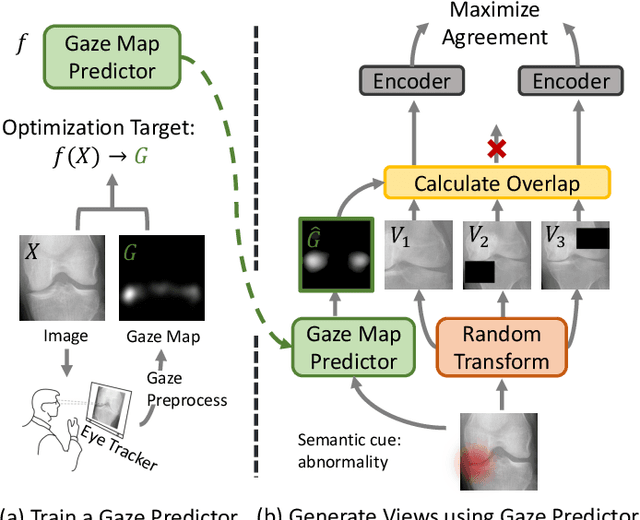
Recent self-supervised contrastive learning methods greatly benefit from the Siamese structure that aims to minimizing distances between positive pairs. These methods usually apply random data augmentation to input images, expecting the augmented views of the same images to be similar and positively paired. However, random augmentation may overlook image semantic information and degrade the quality of augmented views in contrastive learning. This issue becomes more challenging in medical images since the abnormalities related to diseases can be tiny, and are easy to be corrupted (e.g., being cropped out) in the current scheme of random augmentation. In this work, we first demonstrate that, for widely-used X-ray images, the conventional augmentation prevalent in contrastive pre-training can affect the performance of the downstream diagnosis or classification tasks. Then, we propose a novel augmentation method, i.e., FocusContrast, to learn from radiologists' gaze in diagnosis and generate contrastive views for medical images with guidance from radiologists' visual attention. Specifically, we track the gaze movement of radiologists and model their visual attention when reading to diagnose X-ray images. The learned model can predict visual attention of the radiologists given a new input image, and further guide the attention-aware augmentation that hardly neglects the disease-related abnormalities. As a plug-and-play and framework-agnostic module, FocusContrast consistently improves state-of-the-art contrastive learning methods of SimCLR, MoCo, and BYOL by 4.0~7.0% in classification accuracy on a knee X-ray dataset.
Domain Generalization for Mammographic Image Analysis via Contrastive Learning
Apr 20, 2023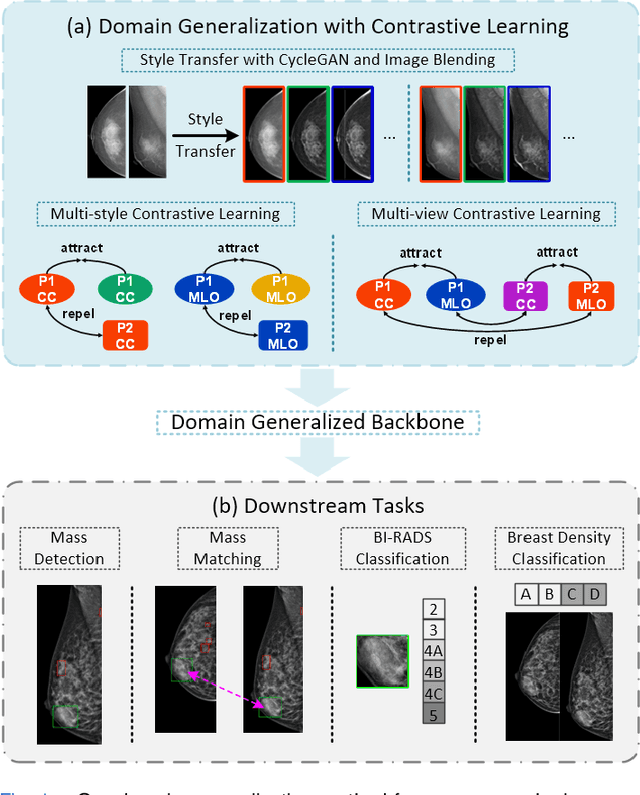
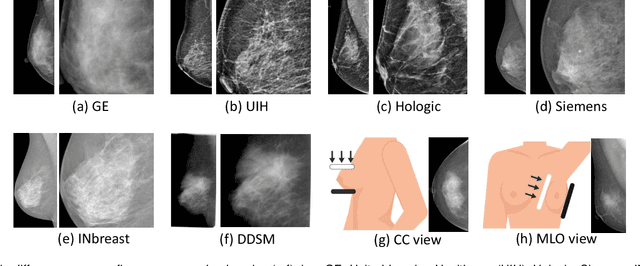
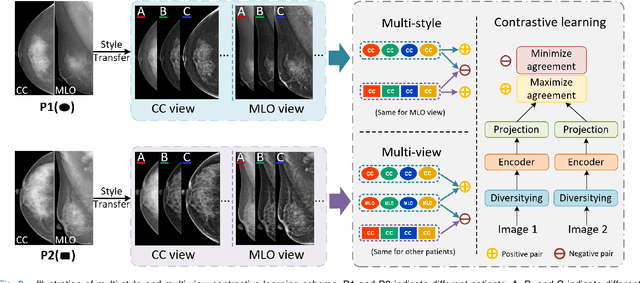
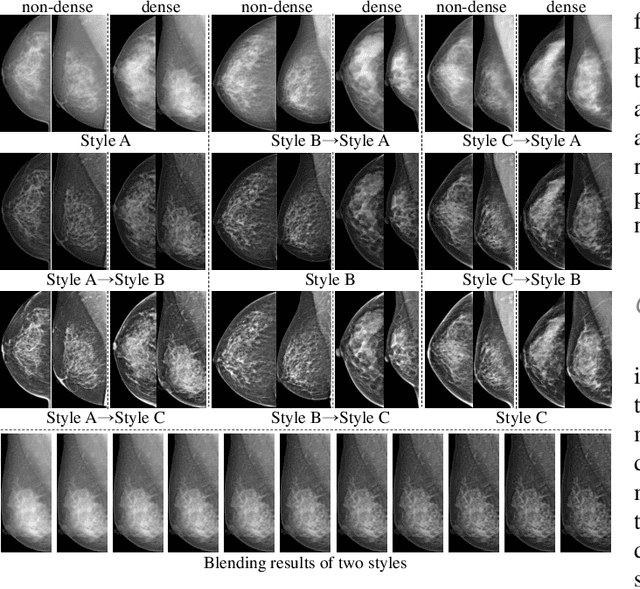
Mammographic image analysis is a fundamental problem in the computer-aided diagnosis scheme, which has recently made remarkable progress with the advance of deep learning. However, the construction of a deep learning model requires training data that are large and sufficiently diverse in terms of image style and quality. In particular, the diversity of image style may be majorly attributed to the vendor factor. However, mammogram collection from vendors as many as possible is very expensive and sometimes impractical for laboratory-scale studies. Accordingly, to further augment the generalization capability of deep learning models to various vendors with limited resources, a new contrastive learning scheme is developed. Specifically, the backbone network is firstly trained with a multi-style and multi-view unsupervised self-learning scheme for the embedding of invariant features to various vendor styles. Afterward, the backbone network is then recalibrated to the downstream tasks of mass detection, multi-view mass matching, BI-RADS classification and breast density classification with specific supervised learning. The proposed method is evaluated with mammograms from four vendors and two unseen public datasets. The experimental results suggest that our approach can effectively improve analysis performance on both seen and unseen domains, and outperforms many state-of-the-art (SOTA) generalization methods.
Arbitrary Reduction of MRI Inter-slice Spacing Using Hierarchical Feature Conditional Diffusion
Apr 18, 2023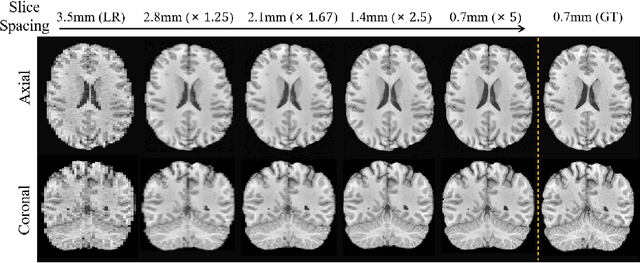
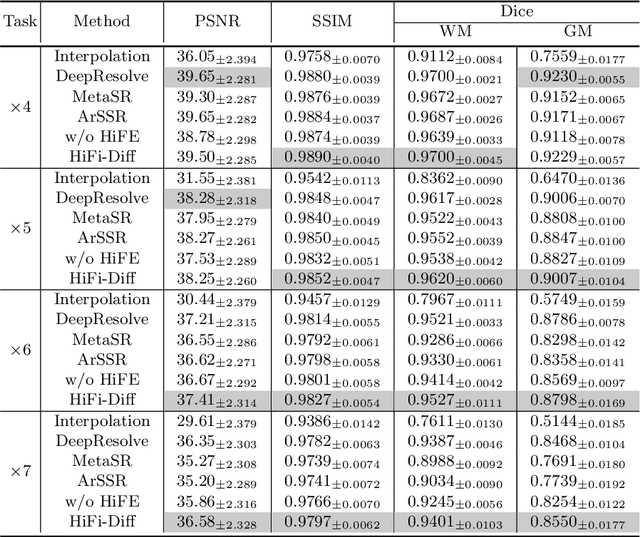
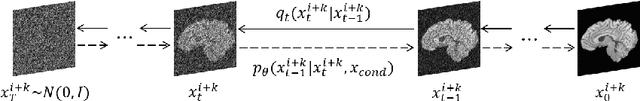
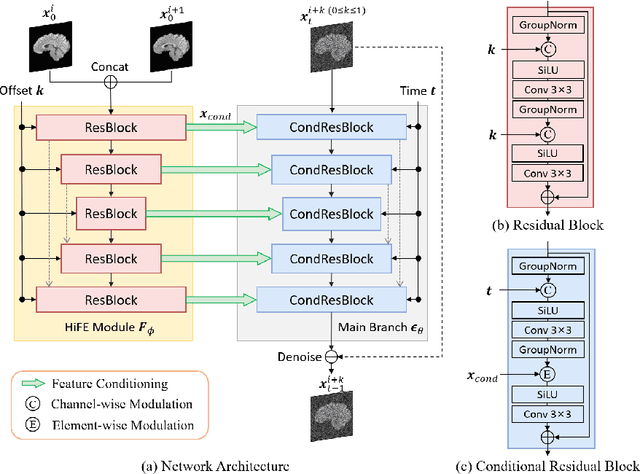
Magnetic resonance (MR) images collected in 2D scanning protocols typically have large inter-slice spacing, resulting in high in-plane resolution but reduced through-plane resolution. Super-resolution techniques can reduce the inter-slice spacing of 2D scanned MR images, facilitating the downstream visual experience and computer-aided diagnosis. However, most existing super-resolution methods are trained at a fixed scaling ratio, which is inconvenient in clinical settings where MR scanning may have varying inter-slice spacings. To solve this issue, we propose Hierarchical Feature Conditional Diffusion (HiFi-Diff)} for arbitrary reduction of MR inter-slice spacing. Given two adjacent MR slices and the relative positional offset, HiFi-Diff can iteratively convert a Gaussian noise map into any desired in-between MR slice. Furthermore, to enable fine-grained conditioning, the Hierarchical Feature Extraction (HiFE) module is proposed to hierarchically extract conditional features and conduct element-wise modulation. Our experimental results on the publicly available HCP-1200 dataset demonstrate the high-fidelity super-resolution capability of HiFi-Diff and its efficacy in enhancing downstream segmentation performance.
RCPS: Rectified Contrastive Pseudo Supervision for Semi-Supervised Medical Image Segmentation
Jan 13, 2023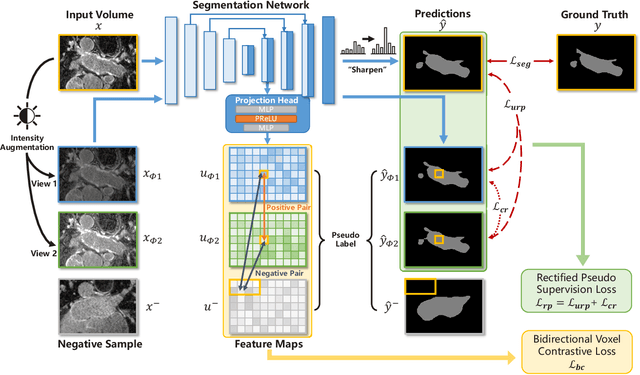
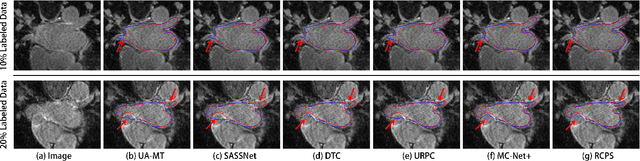
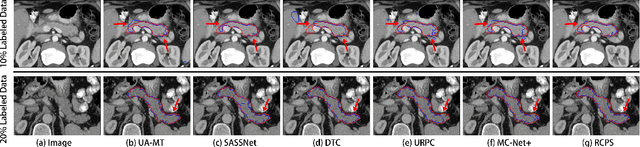
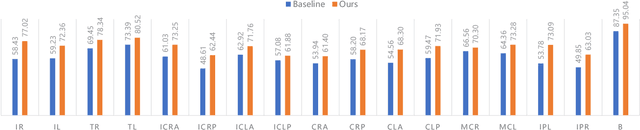
Medical image segmentation methods are generally designed as fully-supervised to guarantee model performance, which require a significant amount of expert annotated samples that are high-cost and laborious. Semi-supervised image segmentation can alleviate the problem by utilizing a large number of unlabeled images along with limited labeled images. However, learning a robust representation from numerous unlabeled images remains challenging due to potential noise in pseudo labels and insufficient class separability in feature space, which undermines the performance of current semi-supervised segmentation approaches. To address the issues above, we propose a novel semi-supervised segmentation method named as Rectified Contrastive Pseudo Supervision (RCPS), which combines a rectified pseudo supervision and voxel-level contrastive learning to improve the effectiveness of semi-supervised segmentation. Particularly, we design a novel rectification strategy for the pseudo supervision method based on uncertainty estimation and consistency regularization to reduce the noise influence in pseudo labels. Furthermore, we introduce a bidirectional voxel contrastive loss to the network to ensure intra-class consistency and inter-class contrast in feature space, which increases class separability in the segmentation. The proposed RCPS segmentation method has been validated on two public datasets and an in-house clinical dataset. Experimental results reveal that the proposed method yields better segmentation performance compared with the state-of-the-art methods in semi-supervised medical image segmentation. The source code is available at https://github.com/hsiangyuzhao/RCPS.