 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLichun Wang
Real-time Human Action Recognition Using Locally Aggregated Kinematic-Guided Skeletonlet and Supervised Hashing-by-Analysis Model
May 24, 2021
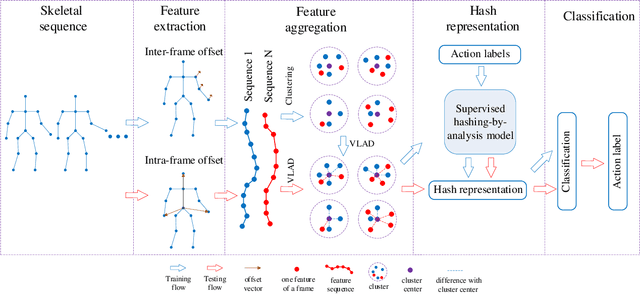
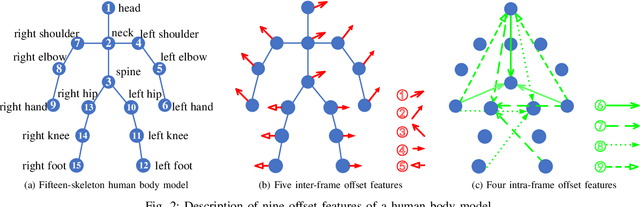
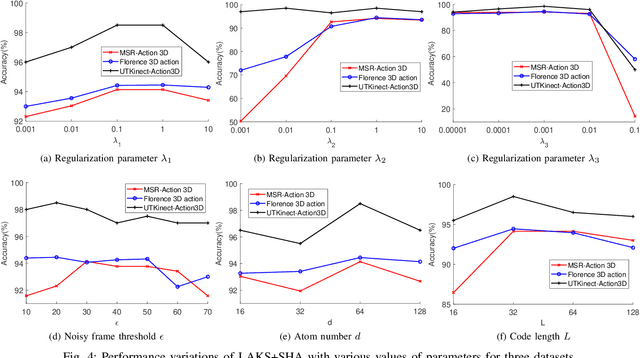
3D action recognition is referred to as the classification of action sequences which consist of 3D skeleton joints. While many research work are devoted to 3D action recognition, it mainly suffers from three problems: highly complicated articulation, a great amount of noise, and a low implementation efficiency. To tackle all these problems, we propose a real-time 3D action recognition framework by integrating the locally aggregated kinematic-guided skeletonlet (LAKS) with a supervised hashing-by-analysis (SHA) model. We first define the skeletonlet as a few combinations of joint offsets grouped in terms of kinematic principle, and then represent an action sequence using LAKS, which consists of a denoising phase and a locally aggregating phase. The denoising phase detects the noisy action data and adjust it by replacing all the features within it with the features of the corresponding previous frame, while the locally aggregating phase sums the difference between an offset feature of the skeletonlet and its cluster center together over all the offset features of the sequence. Finally, the SHA model which combines sparse representation with a hashing model, aiming at promoting the recognition accuracy while maintaining a high efficiency. Experimental results on MSRAction3D, UTKinectAction3D and Florence3DAction datasets demonstrate that the proposed method outperforms state-of-the-art methods in both recognition accuracy and implementation efficiency.
Feature Fusion Use Unsupervised Prior Knowledge to Let Small Object Represent
Dec 17, 2019

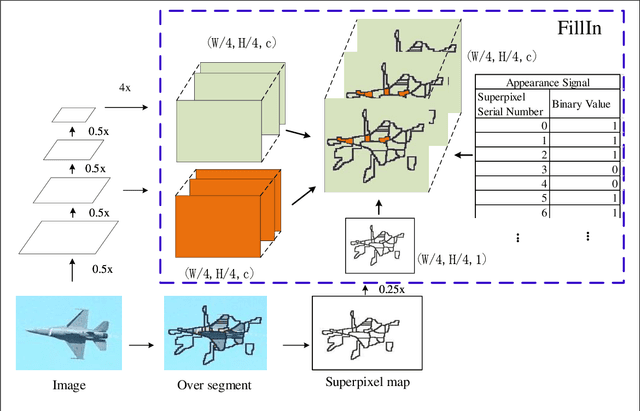
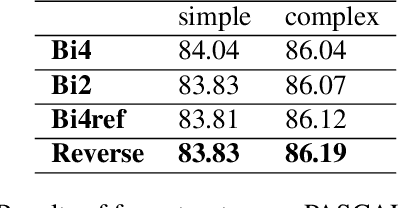
Fusing low level and high level features is a widely used strategy to provide details that might be missing during convolution and pooling. Different from previous works, we propose a new fusion mechanism called FillIn which takes advantage of prior knowledge described with superpixel segmentation. According to the prior knowledge, the FillIn chooses small region on low level feature map to fill into high level feature map. By using the proposed fusion mechanism, the low level features have equal channels for some tiny region as high level features, which makes the low level features have relatively independent power to decide final semantic label. We demonstrate the effectiveness of our model on PASCAL VOC 2012, it achieves competitive test result based on DeepLabv3+ backbone and visualizations of predictions prove our fusion can let small objects represent and low level features have potential for segmenting small objects.