 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLihui Chen
Learn from Heterophily: Heterophilous Information-enhanced Graph Neural Network
Mar 26, 2024




Under circumstances of heterophily, where nodes with different labels tend to be connected based on semantic meanings, Graph Neural Networks (GNNs) often exhibit suboptimal performance. Current studies on graph heterophily mainly focus on aggregation calibration or neighbor extension and address the heterophily issue by utilizing node features or structural information to improve GNN representations. In this paper, we propose and demonstrate that the valuable semantic information inherent in heterophily can be utilized effectively in graph learning by investigating the distribution of neighbors for each individual node within the graph. The theoretical analysis is carried out to demonstrate the efficacy of the idea in enhancing graph learning. Based on this analysis, we propose HiGNN, an innovative approach that constructs an additional new graph structure, that integrates heterophilous information by leveraging node distribution to enhance connectivity between nodes that share similar semantic characteristics. We conduct empirical assessments on node classification tasks using both homophilous and heterophilous benchmark datasets and compare HiGNN to popular GNN baselines and SoTA methods, confirming the effectiveness in improving graph representations. In addition, by incorporating heterophilous information, we demonstrate a notable enhancement in existing GNN-based approaches, and the homophily degree across real-world datasets, thus affirming the efficacy of our approach.
DistillCSE: Distilled Contrastive Learning for Sentence Embeddings
Oct 30, 2023This paper proposes the DistillCSE framework, which performs contrastive learning under the self-training paradigm with knowledge distillation. The potential advantage of DistillCSE is its self-enhancing feature: using a base model to provide additional supervision signals, a stronger model may be learned through knowledge distillation. However, the vanilla DistillCSE through the standard implementation of knowledge distillation only achieves marginal improvements due to severe overfitting. The further quantitative analyses demonstrate the reason that the standard knowledge distillation exhibits a relatively large variance of the teacher model's logits due to the essence of contrastive learning. To mitigate the issue induced by high variance, this paper accordingly proposed two simple yet effective solutions for knowledge distillation: a Group-P shuffling strategy as an implicit regularization and the averaging logits from multiple teacher components. Experiments on standard benchmarks demonstrate that the proposed DistillCSE outperforms many strong baseline methods and yields a new state-of-the-art performance.
On Synthetic Data for Back Translation
Oct 20, 2023Back translation (BT) is one of the most significant technologies in NMT research fields. Existing attempts on BT share a common characteristic: they employ either beam search or random sampling to generate synthetic data with a backward model but seldom work studies the role of synthetic data in the performance of BT. This motivates us to ask a fundamental question: {\em what kind of synthetic data contributes to BT performance?} Through both theoretical and empirical studies, we identify two key factors on synthetic data controlling the back-translation NMT performance, which are quality and importance. Furthermore, based on our findings, we propose a simple yet effective method to generate synthetic data to better trade off both factors so as to yield a better performance for BT. We run extensive experiments on WMT14 DE-EN, EN-DE, and RU-EN benchmark tasks. By employing our proposed method to generate synthetic data, our BT model significantly outperforms the standard BT baselines (i.e., beam and sampling based methods for data generation), which proves the effectiveness of our proposed methods.
BiGSeT: Binary Mask-Guided Separation Training for DNN-based Hyperspectral Anomaly Detection
Jul 14, 2023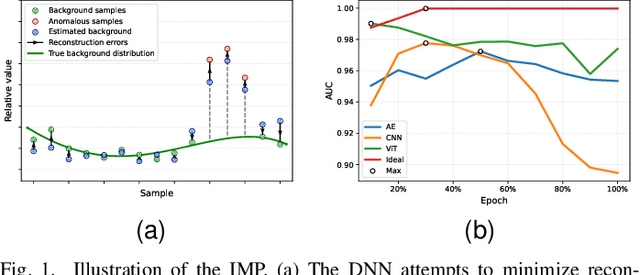


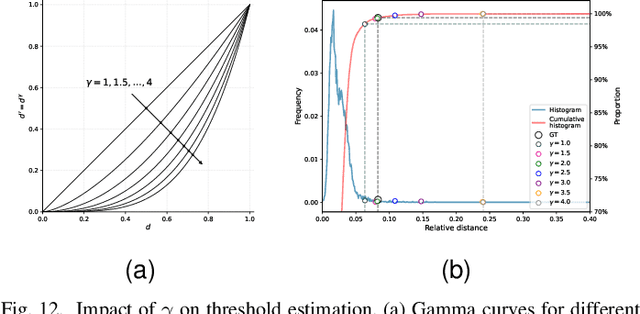
Hyperspectral anomaly detection (HAD) aims to recognize a minority of anomalies that are spectrally different from their surrounding background without prior knowledge. Deep neural networks (DNNs), including autoencoders (AEs), convolutional neural networks (CNNs) and vision transformers (ViTs), have shown remarkable performance in this field due to their powerful ability to model the complicated background. However, for reconstruction tasks, DNNs tend to incorporate both background and anomalies into the estimated background, which is referred to as the identical mapping problem (IMP) and leads to significantly decreased performance. To address this limitation, we propose a model-independent binary mask-guided separation training strategy for DNNs, named BiGSeT. Our method introduces a separation training loss based on a latent binary mask to separately constrain the background and anomalies in the estimated image. The background is preserved, while the potential anomalies are suppressed by using an efficient second-order Laplacian of Gaussian (LoG) operator, generating a pure background estimate. In order to maintain separability during training, we periodically update the mask using a robust proportion threshold estimated before the training. In our experiments, We adopt a vanilla AE as the network to validate our training strategy on several real-world datasets. Our results show superior performance compared to some state-of-the-art methods. Specifically, we achieved a 90.67% AUC score on the HyMap Cooke City dataset. Additionally, we applied our training strategy to other deep network structures, achieving improved detection performance compared to their original versions, demonstrating its effective transferability. The code of our method will be available at https://github.com/enter-i-username/BiGSeT.
Resource Efficient Neural Networks Using Hessian Based Pruning
Jun 12, 2023



Neural network pruning is a practical way for reducing the size of trained models and the number of floating-point operations. One way of pruning is to use the relative Hessian trace to calculate sensitivity of each channel, as compared to the more common magnitude pruning approach. However, the stochastic approach used to estimate the Hessian trace needs to iterate over many times before it can converge. This can be time-consuming when used for larger models with many millions of parameters. To address this problem, we modify the existing approach by estimating the Hessian trace using FP16 precision instead of FP32. We test the modified approach (EHAP) on ResNet-32/ResNet-56/WideResNet-28-8 trained on CIFAR10/CIFAR100 image classification tasks and achieve faster computation of the Hessian trace. Specifically, our modified approach can achieve speed ups ranging from 17% to as much as 44% during our experiments on different combinations of model architectures and GPU devices. Our modified approach also takes up around 40% less GPU memory when pruning ResNet-32 and ResNet-56 models, which allows for a larger Hessian batch size to be used for estimating the Hessian trace. Meanwhile, we also present the results of pruning using both FP16 and FP32 Hessian trace calculation and show that there are no noticeable accuracy differences between the two. Overall, it is a simple and effective way to compute the relative Hessian trace faster without sacrificing on pruned model performance. We also present a full pipeline using EHAP and quantization aware training (QAT), using INT8 QAT to compress the network further after pruning. In particular, we use symmetric quantization for the weights and asymmetric quantization for the activations.
ImSimCSE: Improving Contrastive Learning for Sentence Embeddings from Two Perspectives
May 22, 2023



This paper aims to improve contrastive learning for sentence embeddings from two perspectives: handling dropout noise and addressing feature corruption. Specifically, for the first perspective, we identify that the dropout noise from negative pairs affects the model's performance. Therefore, we propose a simple yet effective method to deal with such type of noise. Secondly, we pinpoint the rank bottleneck of current solutions to feature corruption and propose a dimension-wise contrastive learning objective to address this issue. Both proposed methods are generic and can be applied to any contrastive learning based models for sentence embeddings. Experimental results on standard benchmarks demonstrate that combining both proposed methods leads to a gain of 1.8 points compared to the strong baseline SimCSE configured with BERT base. Furthermore, applying the proposed method to DiffCSE, another strong contrastive learning based baseline, results in a gain of 1.4 points.
mSHINE: A Multiple-meta-paths Simultaneous Learning Framework for Heterogeneous Information Network Embedding
Apr 09, 2021



Heterogeneous information networks(HINs) become popular in recent years for its strong capability of modelling objects with abundant information using explicit network structure. Network embedding has been proved as an effective method to convert information networks into lower-dimensional space, whereas the core information can be well preserved. However, traditional network embedding algorithms are sub-optimal in capturing rich while potentially incompatible semantics provided by HINs. To address this issue, a novel meta-path-based HIN representation learning framework named mSHINE is designed to simultaneously learn multiple node representations for different meta-paths. More specifically, one representation learning module inspired by the RNN structure is developed and multiple node representations can be learned simultaneously, where each representation is associated with one respective meta-path. By measuring the relevance between nodes with the designed objective function, the learned module can be applied in downstream link prediction tasks. A set of criteria for selecting initial meta-paths is proposed as the other module in mSHINE which is important to reduce the optimal meta-path selection cost when no prior knowledge of suitable meta-paths is available. To corroborate the effectiveness of mSHINE, extensive experimental studies including node classification and link prediction are conducted on five real-world datasets. The results demonstrate that mSHINE outperforms other state-of-the-art HIN embedding methods.
LA-HCN: Label-based Attention for Hierarchical Multi-label TextClassification Neural Network
Sep 23, 2020



Hierarchical multi-label text classification(HMTC) problems become popular recently because of its practicality. Most existing algorithms for HMTC focus on the design of classifiers, and are largely referred to as local, global, or a combination of local/global approaches. However, a few studies have started exploring hierarchical feature extraction based on the label hierarchy associating with text in HMTC. In this paper, a \textbf{N}eural network-based method called \textbf{LA-HCN} is proposed where a novel \textbf{L}abel-based \textbf{A}ttention module is designed to hierarchically extract important information from the text based on different labels. Besides, local and global document embeddings are separately generated to support the respective local and global classifications. In our experiments, LA-HCN achieves the top performance on the four public HMTC datasets when compared with other neural network-based state-of-the-art algorithms. The comparison between LA-HCN with its variants also demonstrates the effectiveness of the proposed label-based attention module as well as the use of the combination of local and global classifications. By visualizing the learned attention(words), we find LA-HCN is able to extract meaningful but different information from text based on different labels which is helpful for human understanding and explanation of classification results.
apk2vec: Semi-supervised multi-view representation learning for profiling Android applications
Sep 15, 2018



Building behavior profiles of Android applications (apps) with holistic, rich and multi-view information (e.g., incorporating several semantic views of an app such as API sequences, system calls, etc.) would help catering downstream analytics tasks such as app categorization, recommendation and malware analysis significantly better. Towards this goal, we design a semi-supervised Representation Learning (RL) framework named apk2vec to automatically generate a compact representation (aka profile/embedding) for a given app. More specifically, apk2vec has the three following unique characteristics which make it an excellent choice for largescale app profiling: (1) it encompasses information from multiple semantic views such as API sequences, permissions, etc., (2) being a semi-supervised embedding technique, it can make use of labels associated with apps (e.g., malware family or app category labels) to build high quality app profiles, and (3) it combines RL and feature hashing which allows it to efficiently build profiles of apps that stream over time (i.e., online learning). The resulting semi-supervised multi-view hash embeddings of apps could then be used for a wide variety of downstream tasks such as the ones mentioned above. Our extensive evaluations with more than 42,000 apps demonstrate that apk2vec's app profiles could significantly outperform state-of-the-art techniques in four app analytics tasks namely, malware detection, familial clustering, app clone detection and app recommendation.
graph2vec: Learning Distributed Representations of Graphs
Jul 17, 2017



Recent works on representation learning for graph structured data predominantly focus on learning distributed representations of graph substructures such as nodes and subgraphs. However, many graph analytics tasks such as graph classification and clustering require representing entire graphs as fixed length feature vectors. While the aforementioned approaches are naturally unequipped to learn such representations, graph kernels remain as the most effective way of obtaining them. However, these graph kernels use handcrafted features (e.g., shortest paths, graphlets, etc.) and hence are hampered by problems such as poor generalization. To address this limitation, in this work, we propose a neural embedding framework named graph2vec to learn data-driven distributed representations of arbitrary sized graphs. graph2vec's embeddings are learnt in an unsupervised manner and are task agnostic. Hence, they could be used for any downstream task such as graph classification, clustering and even seeding supervised representation learning approaches. Our experiments on several benchmark and large real-world datasets show that graph2vec achieves significant improvements in classification and clustering accuracies over substructure representation learning approaches and are competitive with state-of-the-art graph kernels.