 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLijun Sun
Learning Car-Following Behaviors Using Bayesian Matrix Normal Mixture Regression
Apr 24, 2024
Learning and understanding car-following (CF) behaviors are crucial for microscopic traffic simulation. Traditional CF models, though simple, often lack generalization capabilities, while many data-driven methods, despite their robustness, operate as "black boxes" with limited interpretability. To bridge this gap, this work introduces a Bayesian Matrix Normal Mixture Regression (MNMR) model that simultaneously captures feature correlations and temporal dynamics inherent in CF behaviors. This approach is distinguished by its separate learning of row and column covariance matrices within the model framework, offering an insightful perspective into the human driver decision-making processes. Through extensive experiments, we assess the model's performance across various historical steps of inputs, predictive steps of outputs, and model complexities. The results consistently demonstrate our model's adeptness in effectively capturing the intricate correlations and temporal dynamics present during CF. A focused case study further illustrates the model's outperforming interpretability of identifying distinct operational conditions through the learned mean and covariance matrices. This not only underlines our model's effectiveness in understanding complex human driving behaviors in CF scenarios but also highlights its potential as a tool for enhancing the interpretability of CF behaviors in traffic simulations and autonomous driving systems.
Multivariate Probabilistic Time Series Forecasting with Correlated Errors
Feb 07, 2024Modeling the correlations among errors is closely associated with how accurately the model can quantify predictive uncertainty in probabilistic time series forecasting. Recent multivariate models have made significant progress in accounting for contemporaneous correlations among errors, while a common assumption on these errors is that they are temporally independent for the sake of statistical simplicity. However, real-world observations often deviate from this assumption, since errors usually exhibit substantial autocorrelation due to various factors such as the exclusion of temporally correlated covariates. In this work, we propose an efficient method, based on a low-rank-plus-diagonal parameterization of the covariance matrix, which can effectively characterize the autocorrelation of errors. The proposed method possesses several desirable properties: the complexity does not scale with the number of time series, the resulting covariance can be used for calibrating predictions, and it can seamlessly integrate with any model with Gaussian-distributed errors. We empirically demonstrate these properties using two distinct neural forecasting models-GPVar and Transformer. Our experimental results confirm the effectiveness of our method in enhancing predictive accuracy and the quality of uncertainty quantification on multiple real-world datasets.
Rethinking Urban Mobility Prediction: A Super-Multivariate Time Series Forecasting Approach
Dec 04, 2023



Long-term urban mobility predictions play a crucial role in the effective management of urban facilities and services. Conventionally, urban mobility data has been structured as spatiotemporal videos, treating longitude and latitude grids as fundamental pixels. Consequently, video prediction methods, relying on Convolutional Neural Networks (CNNs) and Vision Transformers (ViTs), have been instrumental in this domain. In our research, we introduce a fresh perspective on urban mobility prediction. Instead of oversimplifying urban mobility data as traditional video data, we regard it as a complex multivariate time series. This perspective involves treating the time-varying values of each grid in each channel as individual time series, necessitating a thorough examination of temporal dynamics, cross-variable correlations, and frequency-domain insights for precise and reliable predictions. To address this challenge, we present the Super-Multivariate Urban Mobility Transformer (SUMformer), which utilizes a specially designed attention mechanism to calculate temporal and cross-variable correlations and reduce computational costs stemming from a large number of time series. SUMformer also employs low-frequency filters to extract essential information for long-term predictions. Furthermore, SUMformer is structured with a temporal patch merge mechanism, forming a hierarchical framework that enables the capture of multi-scale correlations. Consequently, it excels in urban mobility pattern modeling and long-term prediction, outperforming current state-of-the-art methods across three real-world datasets.
A Critical Perceptual Pre-trained Model for Complex Trajectory Recovery
Nov 05, 2023



The trajectory on the road traffic is commonly collected at a low sampling rate, and trajectory recovery aims to recover a complete and continuous trajectory from the sparse and discrete inputs. Recently, sequential language models have been innovatively adopted for trajectory recovery in a pre-trained manner: it learns road segment representation vectors, which will be used in the downstream tasks. However, existing methods are incapable of handling complex trajectories: when the trajectory crosses remote road segments or makes several turns, which we call critical nodes, the quality of learned representations deteriorates, and the recovered trajectories skip the critical nodes. This work is dedicated to offering a more robust trajectory recovery for complex trajectories. Firstly, we define the trajectory complexity based on the detour score and entropy score and construct the complexity-aware semantic graphs correspondingly. Then, we propose a Multi-view Graph and Complexity Aware Transformer (MGCAT) model to encode these semantics in trajectory pre-training from two aspects: 1) adaptively aggregate the multi-view graph features considering trajectory pattern, and 2) higher attention to critical nodes in a complex trajectory. Such that, our MGCAT is perceptual when handling the critical scenario of complex trajectories. Extensive experiments are conducted on large-scale datasets. The results prove that our method learns better representations for trajectory recovery, with 5.22% higher F1-score overall and 8.16% higher F1-score for complex trajectories particularly. The code is available at https://github.com/bonaldli/ComplexTraj.
Choose A Table: Tensor Dirichlet Process Multinomial Mixture Model with Graphs for Passenger Trajectory Clustering
Oct 31, 2023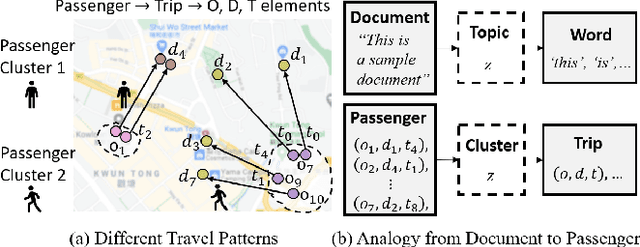
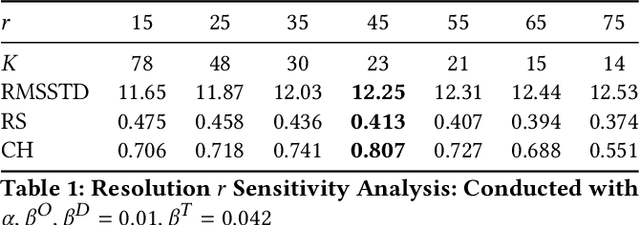
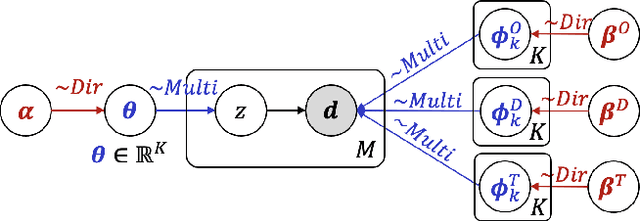
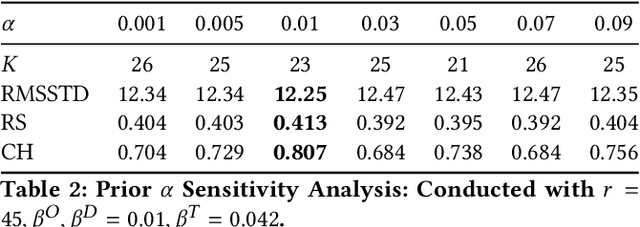
Passenger clustering based on trajectory records is essential for transportation operators. However, existing methods cannot easily cluster the passengers due to the hierarchical structure of the passenger trip information, including multiple trips within each passenger and multi-dimensional information about each trip. Furthermore, existing approaches rely on an accurate specification of the clustering number to start. Finally, existing methods do not consider spatial semantic graphs such as geographical proximity and functional similarity between the locations. In this paper, we propose a novel tensor Dirichlet Process Multinomial Mixture model with graphs, which can preserve the hierarchical structure of the multi-dimensional trip information and cluster them in a unified one-step manner with the ability to determine the number of clusters automatically. The spatial graphs are utilized in community detection to link the semantic neighbors. We further propose a tensor version of Collapsed Gibbs Sampling method with a minimum cluster size requirement. A case study based on Hong Kong metro passenger data is conducted to demonstrate the automatic process of cluster amount evolution and better cluster quality measured by within-cluster compactness and cross-cluster separateness. The code is available at https://github.com/bonaldli/TensorDPMM-G.
Shareable Driving Style Learning and Analysis with a Hierarchical Latent Model
Oct 24, 2023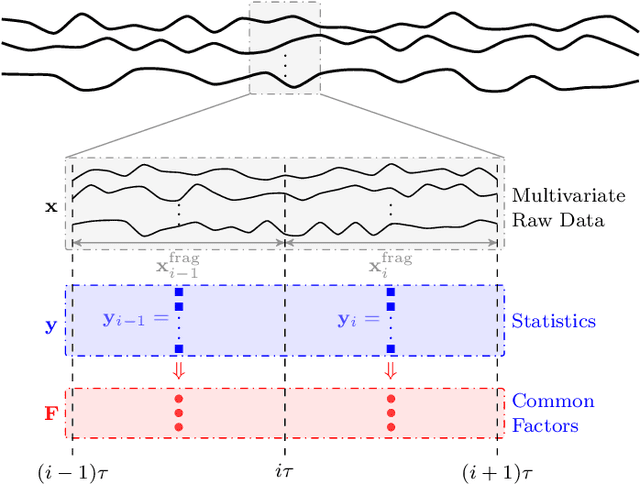
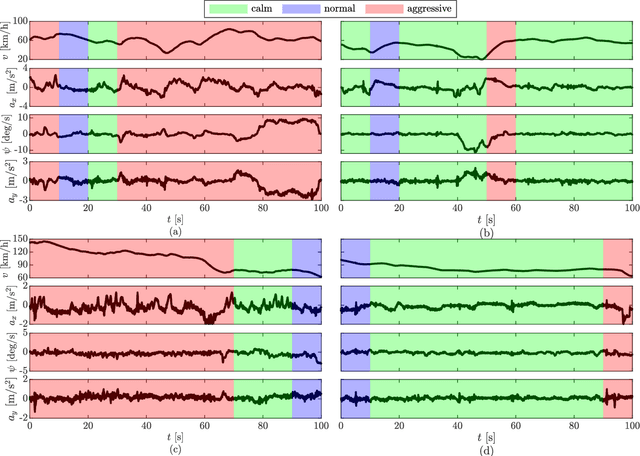
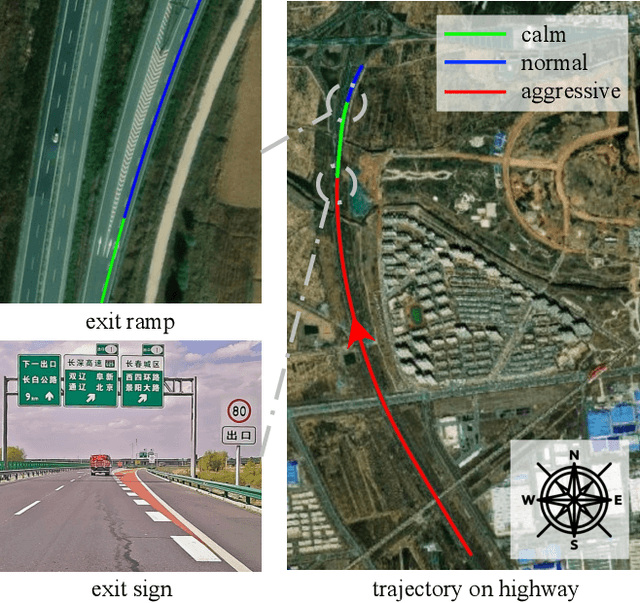
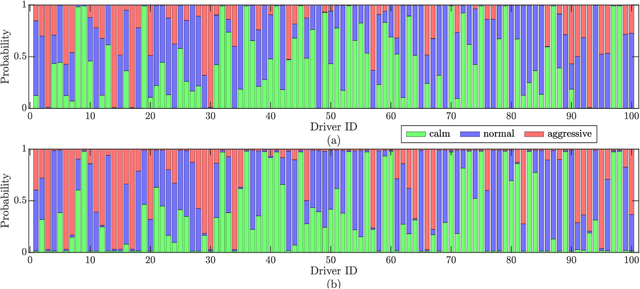
Driving style is usually used to characterize driving behavior for a driver or a group of drivers. However, it remains unclear how one individual's driving style shares certain common grounds with other drivers. Our insight is that driving behavior is a sequence of responses to the weighted mixture of latent driving styles that are shareable within and between individuals. To this end, this paper develops a hierarchical latent model to learn the relationship between driving behavior and driving styles. We first propose a fragment-based approach to represent complex sequential driving behavior, allowing for sufficiently representing driving behavior in a low-dimension feature space. Then, we provide an analytical formulation for the interaction of driving behavior and shareable driving style with a hierarchical latent model by introducing the mechanism of Dirichlet allocation. Our developed model is finally validated and verified with 100 drivers in naturalistic driving settings with urban and highways. Experimental results reveal that individuals share driving styles within and between them. We also analyzed the influence of personalities (e.g., age, gender, and driving experience) on driving styles and found that a naturally aggressive driver would not always keep driving aggressively (i.e., could behave calmly sometimes) but with a higher proportion of aggressiveness than other types of drivers.
Enhancing Representation Learning for Periodic Time Series with Floss: A Frequency Domain Regularization Approach
Aug 09, 2023



Time series analysis is a fundamental task in various application domains, and deep learning approaches have demonstrated remarkable performance in this area. However, many real-world time series data exhibit significant periodic or quasi-periodic dynamics that are often not adequately captured by existing deep learning-based solutions. This results in an incomplete representation of the underlying dynamic behaviors of interest. To address this gap, we propose an unsupervised method called Floss that automatically regularizes learned representations in the frequency domain. The Floss method first automatically detects major periodicities from the time series. It then employs periodic shift and spectral density similarity measures to learn meaningful representations with periodic consistency. In addition, Floss can be easily incorporated into both supervised, semi-supervised, and unsupervised learning frameworks. We conduct extensive experiments on common time series classification, forecasting, and anomaly detection tasks to demonstrate the effectiveness of Floss. We incorporate Floss into several representative deep learning solutions to justify our design choices and demonstrate that it is capable of automatically discovering periodic dynamics and improving state-of-the-art deep learning models.
Interactive Car-Following: Matters but NOT Always
Jul 30, 2023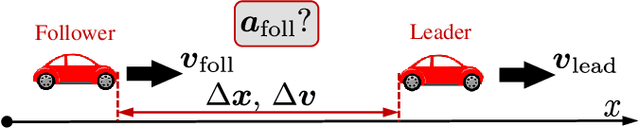
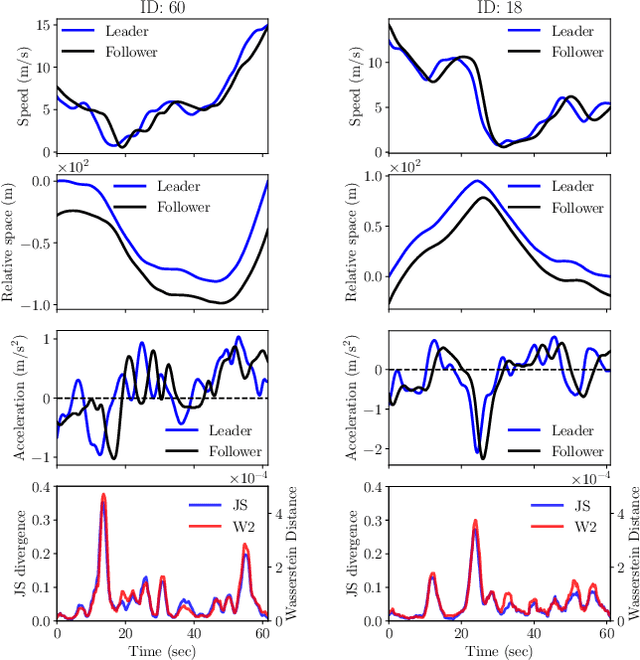
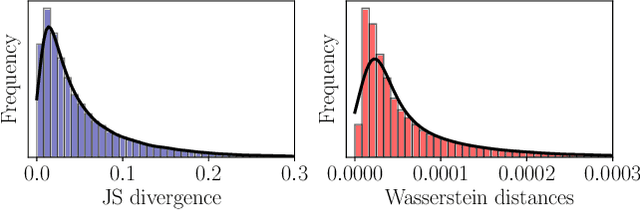
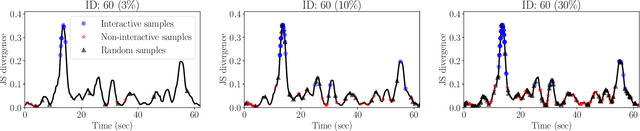
Following a leading vehicle is a daily but challenging task because it requires adapting to various traffic conditions and the leading vehicle's behaviors. However, the question `Does the following vehicle always actively react to the leading vehicle?' remains open. To seek the answer, we propose a novel metric to quantify the interaction intensity within the car-following pairs. The quantified interaction intensity enables us to recognize interactive and non-interactive car-following scenarios and derive corresponding policies for each scenario. Then, we develop an interaction-aware switching control framework with interactive and non-interactive policies, achieving a human-level car-following performance. The extensive simulations demonstrate that our interaction-aware switching control framework achieves improved control performance and data efficiency compared to the unified control strategies. Moreover, the experimental results reveal that human drivers would not always keep reacting to their leading vehicle but occasionally take safety-critical or intentional actions -- interaction matters but not always.
Tensor Dirichlet Process Multinomial Mixture Model for Passenger Trajectory Clustering
Jun 23, 2023Passenger clustering based on travel records is essential for transportation operators. However, existing methods cannot easily cluster the passengers due to the hierarchical structure of the passenger trip information, namely: each passenger has multiple trips, and each trip contains multi-dimensional multi-mode information. Furthermore, existing approaches rely on an accurate specification of the clustering number to start, which is difficult when millions of commuters are using the transport systems on a daily basis. In this paper, we propose a novel Tensor Dirichlet Process Multinomial Mixture model (Tensor-DPMM), which is designed to preserve the multi-mode and hierarchical structure of the multi-dimensional trip information via tensor, and cluster them in a unified one-step manner. The model also has the ability to determine the number of clusters automatically by using the Dirichlet Process to decide the probabilities for a passenger to be either assigned in an existing cluster or to create a new cluster: This allows our model to grow the clusters as needed in a dynamic manner. Finally, existing methods do not consider spatial semantic graphs such as geographical proximity and functional similarity between the locations, which may cause inaccurate clustering. To this end, we further propose a variant of our model, namely the Tensor-DPMM with Graph. For the algorithm, we propose a tensor Collapsed Gibbs Sampling method, with an innovative step of "disband and relocating", which disbands clusters with too small amount of members and relocates them to the remaining clustering. This avoids uncontrollable growing amounts of clusters. A case study based on Hong Kong metro passenger data is conducted to demonstrate the automatic process of learning the number of clusters, and the learned clusters are better in within-cluster compactness and cross-cluster separateness.
Better Batch for Deep Probabilistic Time Series Forecasting
May 26, 2023



Deep probabilistic time series forecasting has gained significant attention due to its ability to provide valuable uncertainty quantification for decision-making tasks. However, many existing models oversimplify the problem by assuming the error process is time-independent, thereby overlooking the serial correlation in the error process. This oversight can potentially diminish the accuracy of the forecasts, rendering these models less effective for decision-making purposes. To overcome this limitation, we propose an innovative training method that incorporates error autocorrelation to enhance the accuracy of probabilistic forecasting. Our method involves constructing a mini-batch as a collection of $D$ consecutive time series segments for model training and explicitly learning a covariance matrix over each mini-batch that encodes the error correlation among adjacent time steps. The resulting covariance matrix can be used to improve prediction accuracy and enhance uncertainty quantification. We evaluate our method using DeepAR on multiple public datasets, and the experimental results confirm that our framework can effectively capture the error autocorrelation and enhance probabilistic forecasting.