 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLin Yuan
IEPile: Unearthing Large-Scale Schema-Based Information Extraction Corpus
Feb 22, 2024
Large Language Models (LLMs) demonstrate remarkable potential across various domains; however, they exhibit a significant performance gap in Information Extraction (IE). Note that high-quality instruction data is the vital key for enhancing the specific capabilities of LLMs, while current IE datasets tend to be small in scale, fragmented, and lack standardized schema. To this end, we introduce IEPile, a comprehensive bilingual (English and Chinese) IE instruction corpus, which contains approximately 0.32B tokens. We construct IEPile by collecting and cleaning 33 existing IE datasets, and introduce schema-based instruction generation to unearth a large-scale corpus. Experimental results on LLaMA and Baichuan demonstrate that using IEPile can enhance the performance of LLMs for IE, especially the zero-shot generalization. We open-source the resource and pre-trained models, hoping to provide valuable support to the NLP community.
RBA-GCN: Relational Bilevel Aggregation Graph Convolutional Network for Emotion Recognition
Aug 31, 2023Emotion recognition in conversation (ERC) has received increasing attention from researchers due to its wide range of applications.As conversation has a natural graph structure,numerous approaches used to model ERC based on graph convolutional networks (GCNs) have yielded significant results.However,the aggregation approach of traditional GCNs suffers from the node information redundancy problem,leading to node discriminant information loss.Additionally,single-layer GCNs lack the capacity to capture long-range contextual information from the graph. Furthermore,the majority of approaches are based on textual modality or stitching together different modalities, resulting in a weak ability to capture interactions between modalities. To address these problems, we present the relational bilevel aggregation graph convolutional network (RBA-GCN), which consists of three modules: the graph generation module (GGM), similarity-based cluster building module (SCBM) and bilevel aggregation module (BiAM). First, GGM constructs a novel graph to reduce the redundancy of target node information.Then,SCBM calculates the node similarity in the target node and its structural neighborhood, where noisy information with low similarity is filtered out to preserve the discriminant information of the node. Meanwhile, BiAM is a novel aggregation method that can preserve the information of nodes during the aggregation process. This module can construct the interaction between different modalities and capture long-range contextual information based on similarity clusters. On both the IEMOCAP and MELD datasets, the weighted average F1 score of RBA-GCN has a 2.17$\sim$5.21\% improvement over that of the most advanced method.Our code is available at https://github.com/luftmenscher/RBA-GCN and our article with the same name has been published in IEEE/ACM Transactions on Audio,Speech,and Language Processing,vol.31,2023
PRO-Face S: Privacy-preserving Reversible Obfuscation of Face Images via Secure Flow
Jul 18, 2023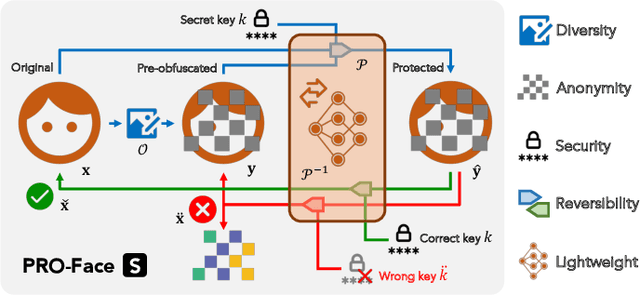
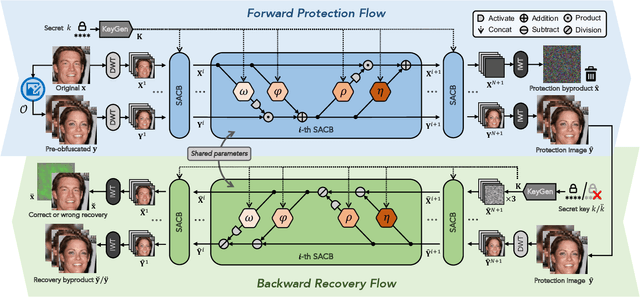
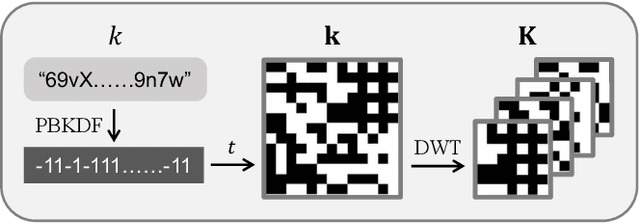
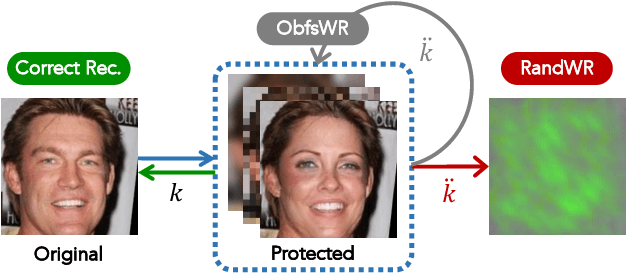
This paper proposes a novel paradigm for facial privacy protection that unifies multiple characteristics including anonymity, diversity, reversibility and security within a single lightweight framework. We name it PRO-Face S, short for Privacy-preserving Reversible Obfuscation of Face images via Secure flow-based model. In the framework, an Invertible Neural Network (INN) is utilized to process the input image along with its pre-obfuscated form, and generate the privacy protected image that visually approximates to the pre-obfuscated one, thus ensuring privacy. The pre-obfuscation applied can be in diversified form with different strengths and styles specified by users. Along protection, a secret key is injected into the network such that the original image can only be recovered from the protection image via the same model given the correct key provided. Two modes of image recovery are devised to deal with malicious recovery attempts in different scenarios. Finally, extensive experiments conducted on three public image datasets demonstrate the superiority of the proposed framework over multiple state-of-the-art approaches.
MMNet: Multi-Collaboration and Multi-Supervision Network for Sequential Deepfake Detection
Jul 06, 2023Advanced manipulation techniques have provided criminals with opportunities to make social panic or gain illicit profits through the generation of deceptive media, such as forged face images. In response, various deepfake detection methods have been proposed to assess image authenticity. Sequential deepfake detection, which is an extension of deepfake detection, aims to identify forged facial regions with the correct sequence for recovery. Nonetheless, due to the different combinations of spatial and sequential manipulations, forged face images exhibit substantial discrepancies that severely impact detection performance. Additionally, the recovery of forged images requires knowledge of the manipulation model to implement inverse transformations, which is difficult to ascertain as relevant techniques are often concealed by attackers. To address these issues, we propose Multi-Collaboration and Multi-Supervision Network (MMNet) that handles various spatial scales and sequential permutations in forged face images and achieve recovery without requiring knowledge of the corresponding manipulation method. Furthermore, existing evaluation metrics only consider detection accuracy at a single inferring step, without accounting for the matching degree with ground-truth under continuous multiple steps. To overcome this limitation, we propose a novel evaluation metric called Complete Sequence Matching (CSM), which considers the detection accuracy at multiple inferring steps, reflecting the ability to detect integrally forged sequences. Extensive experiments on several typical datasets demonstrate that MMNet achieves state-of-the-art detection performance and independent recovery performance.
A Concept Knowledge Graph for User Next Intent Prediction at Alipay
Jan 02, 2023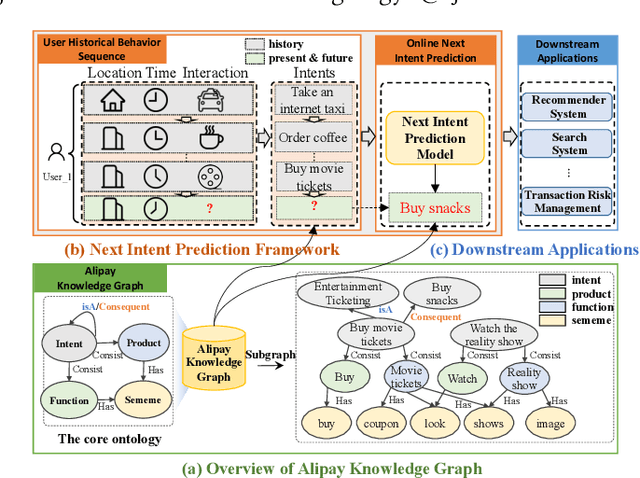
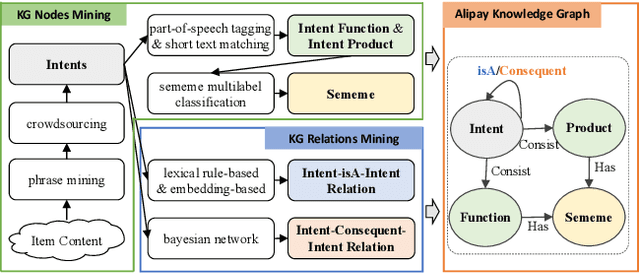
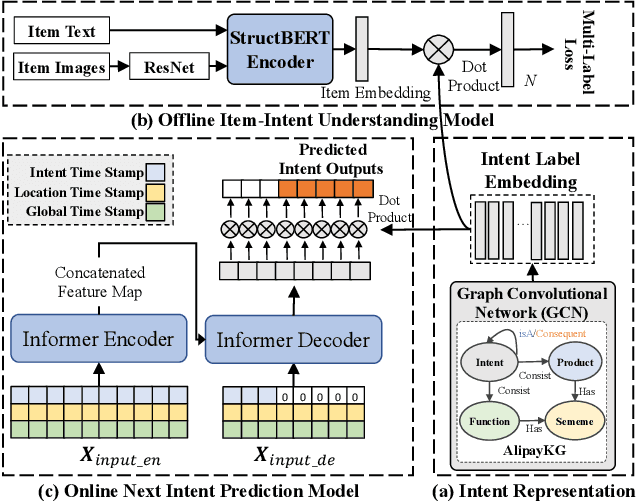
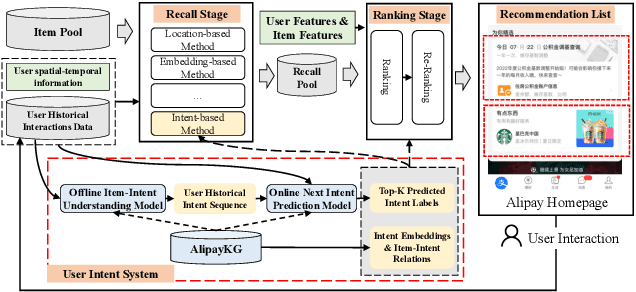
This paper illustrates the technologies of user next intent prediction with a concept knowledge graph. The system has been deployed on the Web at Alipay, serving more than 100 million daily active users. Specifically, we propose AlipayKG to explicitly characterize user intent, which is an offline concept knowledge graph in the Life-Service domain modeling the historical behaviors of users, the rich content interacted by users and the relations between them. We further introduce a Transformer-based model which integrates expert rules from the knowledge graph to infer the online user's next intent. Experimental results demonstrate that the proposed system can effectively enhance the performance of the downstream tasks while retaining explainability.
Generative Graph Neural Networks for Link Prediction
Dec 31, 2022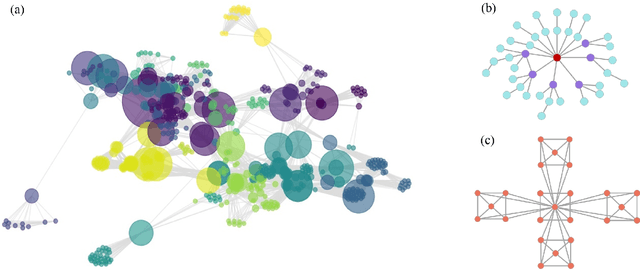
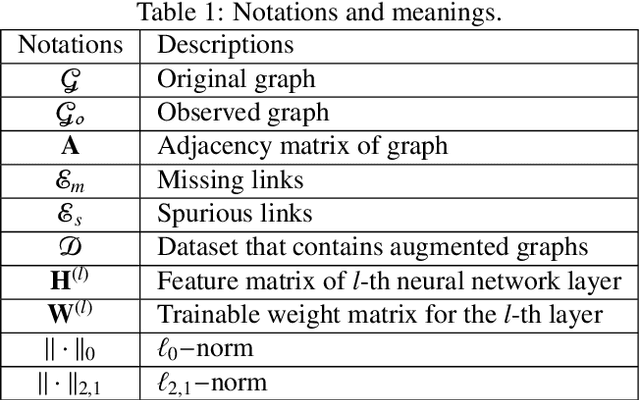
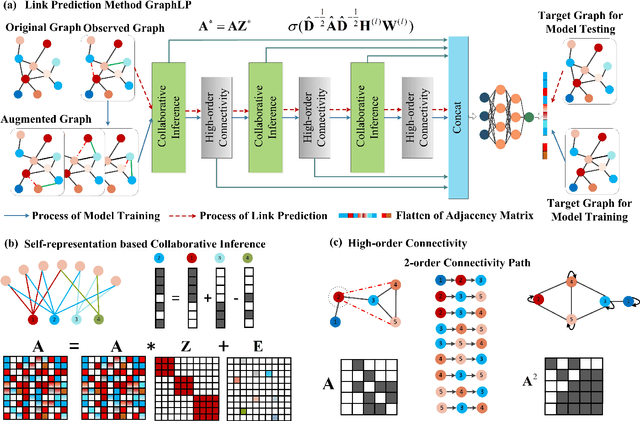
Inferring missing links or detecting spurious ones based on observed graphs, known as link prediction, is a long-standing challenge in graph data analysis. With the recent advances in deep learning, graph neural networks have been used for link prediction and have achieved state-of-the-art performance. Nevertheless, existing methods developed for this purpose are typically discriminative, computing features of local subgraphs around two neighboring nodes and predicting potential links between them from the perspective of subgraph classification. In this formalism, the selection of enclosing subgraphs and heuristic structural features for subgraph classification significantly affects the performance of the methods. To overcome this limitation, this paper proposes a novel and radically different link prediction algorithm based on the network reconstruction theory, called GraphLP. Instead of sampling positive and negative links and heuristically computing the features of their enclosing subgraphs, GraphLP utilizes the feature learning ability of deep-learning models to automatically extract the structural patterns of graphs for link prediction under the assumption that real-world graphs are not locally isolated. Moreover, GraphLP explores high-order connectivity patterns to utilize the hierarchical organizational structures of graphs for link prediction. Our experimental results on all common benchmark datasets from different applications demonstrate that the proposed method consistently outperforms other state-of-the-art methods. Unlike the discriminative neural network models used for link prediction, GraphLP is generative, which provides a new paradigm for neural-network-based link prediction.
An Efficient Framework for Few-shot Skeleton-based Temporal Action Segmentation
Jul 20, 2022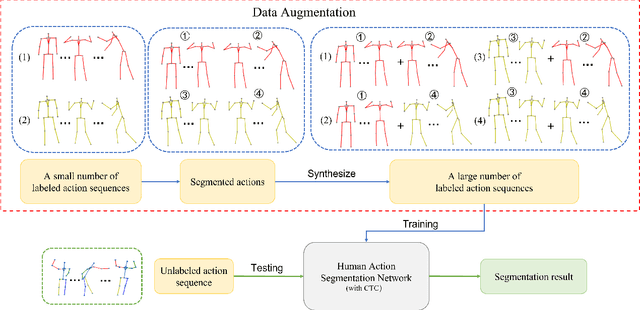
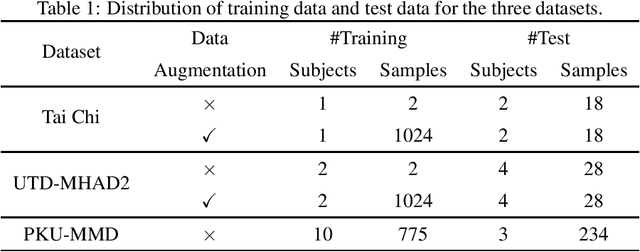
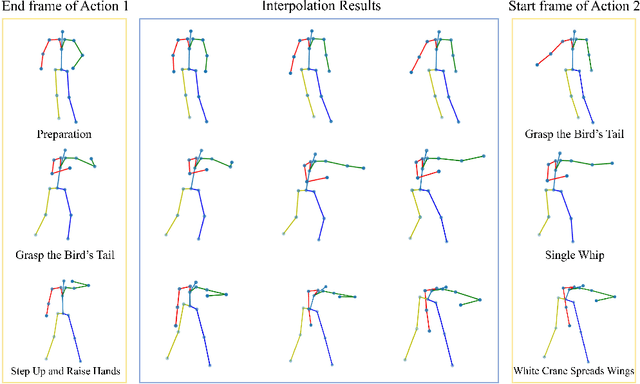
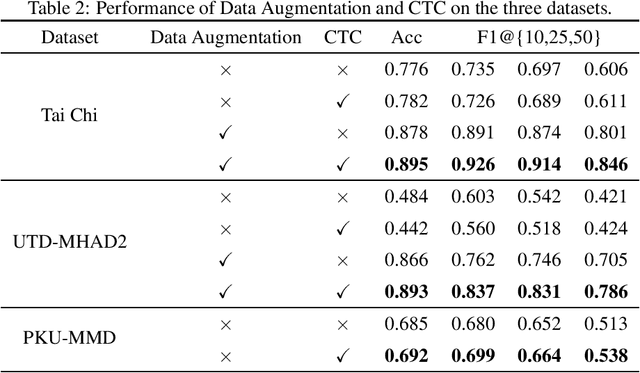
Temporal action segmentation (TAS) aims to classify and locate actions in the long untrimmed action sequence. With the success of deep learning, many deep models for action segmentation have emerged. However, few-shot TAS is still a challenging problem. This study proposes an efficient framework for the few-shot skeleton-based TAS, including a data augmentation method and an improved model. The data augmentation approach based on motion interpolation is presented here to solve the problem of insufficient data, and can increase the number of samples significantly by synthesizing action sequences. Besides, we concatenate a Connectionist Temporal Classification (CTC) layer with a network designed for skeleton-based TAS to obtain an optimized model. Leveraging CTC can enhance the temporal alignment between prediction and ground truth and further improve the segment-wise metrics of segmentation results. Extensive experiments on both public and self-constructed datasets, including two small-scale datasets and one large-scale dataset, show the effectiveness of two proposed methods in improving the performance of the few-shot skeleton-based TAS task.
Spatial Transformer Network with Transfer Learning for Small-scale Fine-grained Skeleton-based Tai Chi Action Recognition
Jun 30, 2022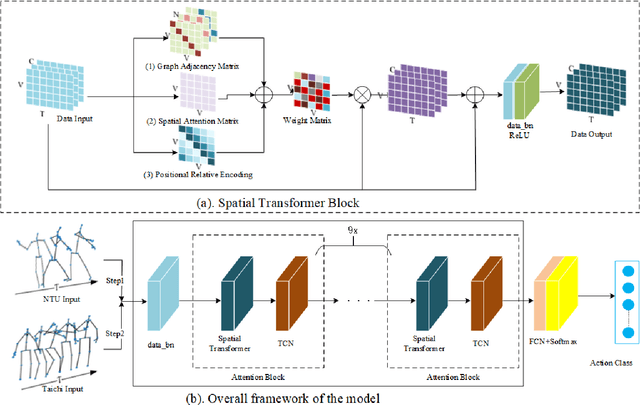

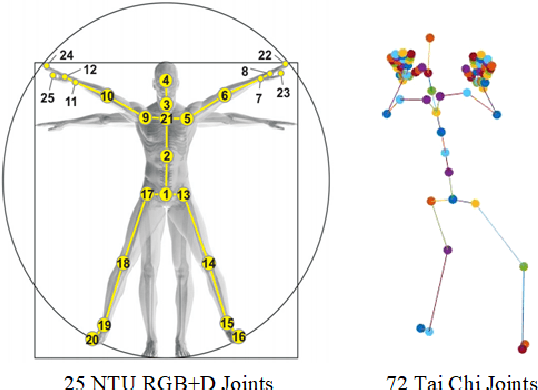
Human action recognition is a quite hugely investigated area where most remarkable action recognition networks usually use large-scale coarse-grained action datasets of daily human actions as inputs to state the superiority of their networks. We intend to recognize our small-scale fine-grained Tai Chi action dataset using neural networks and propose a transfer-learning method using NTU RGB+D dataset to pre-train our network. More specifically, the proposed method first uses a large-scale NTU RGB+D dataset to pre-train the Transformer-based network for action recognition to extract common features among human motion. Then we freeze the network weights except for the fully connected (FC) layer and take our Tai Chi actions as inputs only to train the initialized FC weights. Experimental results show that our general model pipeline can reach a high accuracy of small-scale fine-grained Tai Chi action recognition with even few inputs and demonstrate that our method achieves the state-of-the-art performance compared with previous Tai Chi action recognition methods.
Dialogue Inspectional Summarization with Factual Inconsistency Awareness
Nov 05, 2021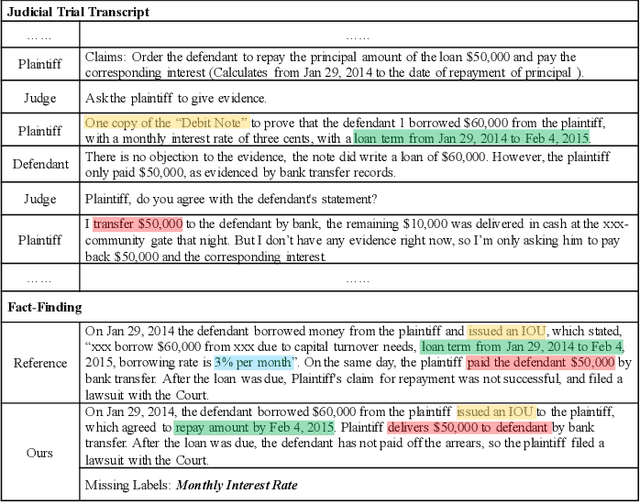
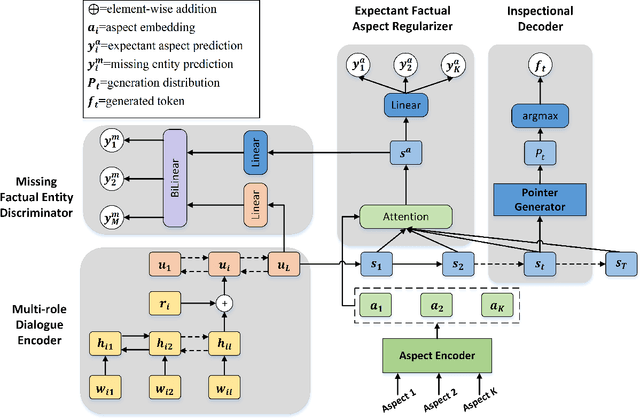
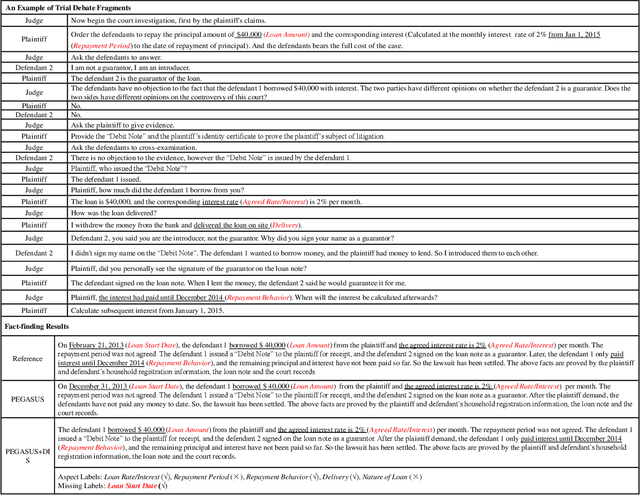
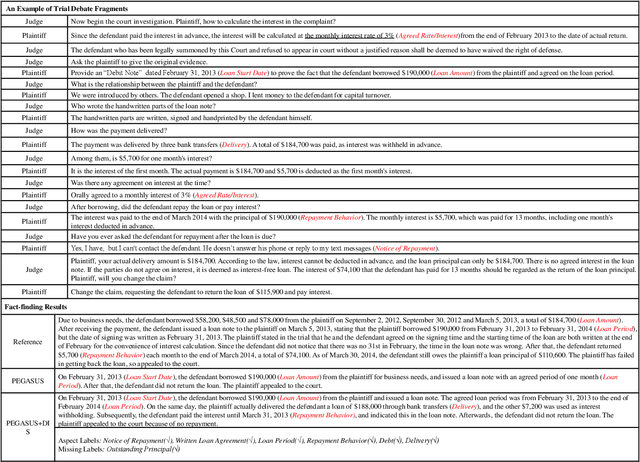
Dialogue summarization has been extensively studied and applied, where the prior works mainly focused on exploring superior model structures to align the input dialogue and the output summary. However, for professional dialogues (e.g., legal debate and medical diagnosis), semantic/statistical alignment can hardly fill the logical/factual gap between input dialogue discourse and summary output with external knowledge. In this paper, we mainly investigate the factual inconsistency problem for Dialogue Inspectional Summarization (DIS) under non-pretraining and pretraining settings. An innovative end-to-end dialogue summary generation framework is proposed with two auxiliary tasks: Expectant Factual Aspect Regularization (EFAR) and Missing Factual Entity Discrimination (MFED). Comprehensive experiments demonstrate that the proposed model can generate a more readable summary with accurate coverage of factual aspects as well as informing the user with potential missing facts detected from the input dialogue for further human intervention.