 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLinda Ruth Petzold
GPT-4V(ision) as a Generalist Evaluator for Vision-Language Tasks
Nov 02, 2023
Automatically evaluating vision-language tasks is challenging, especially when it comes to reflecting human judgments due to limitations in accounting for fine-grained details. Although GPT-4V has shown promising results in various multi-modal tasks, leveraging GPT-4V as a generalist evaluator for these tasks has not yet been systematically explored. We comprehensively validate GPT-4V's capabilities for evaluation purposes, addressing tasks ranging from foundational image-to-text and text-to-image synthesis to high-level image-to-image translations and multi-images to text alignment. We employ two evaluation methods, single-answer grading and pairwise comparison, using GPT-4V. Notably, GPT-4V shows promising agreement with humans across various tasks and evaluation methods, demonstrating immense potential for multi-modal LLMs as evaluators. Despite limitations like restricted visual clarity grading and real-world complex reasoning, its ability to provide human-aligned scores enriched with detailed explanations is promising for universal automatic evaluator.
AlpaCare:Instruction-tuned Large Language Models for Medical Application
Oct 23, 2023Large Language Models (LLMs) have demonstrated significant enhancements in instruction-following abilities through instruction tuning, achieving notable performances across various tasks. Previous research has focused on fine-tuning medical domain-specific LLMs using an extensive array of medical-specific data, incorporating millions of pieces of biomedical literature to augment their medical capabilities. However, existing medical instruction-tuned LLMs have been constrained by the limited scope of tasks and instructions available, restricting the efficacy of instruction tuning and adversely affecting performance in the general domain. In this paper, we fine-tune LLaMA-series models using 52k diverse, machine-generated, medical instruction-following data, MedInstruct-52k, resulting in the model AlpaCare. Comprehensive experimental results on both general and medical-specific domain free-form instruction evaluations showcase AlpaCare's strong medical proficiency and generalizability compared to previous instruction-tuned models in both medical and general domains. We provide public access to our MedInstruct-52k dataset and a clinician-crafted free-form instruction test set, MedInstruct-test, along with our codebase, to foster further research and development. Our project page is available at https://github.com/XZhang97666/AlpaCare.
Enhancing Small Medical Learners with Privacy-preserving Contextual Prompting
May 22, 2023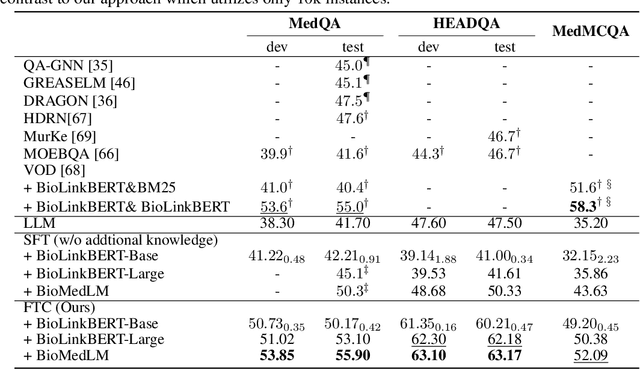
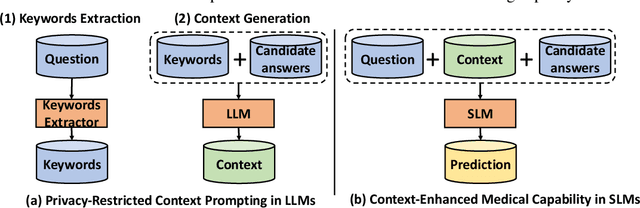
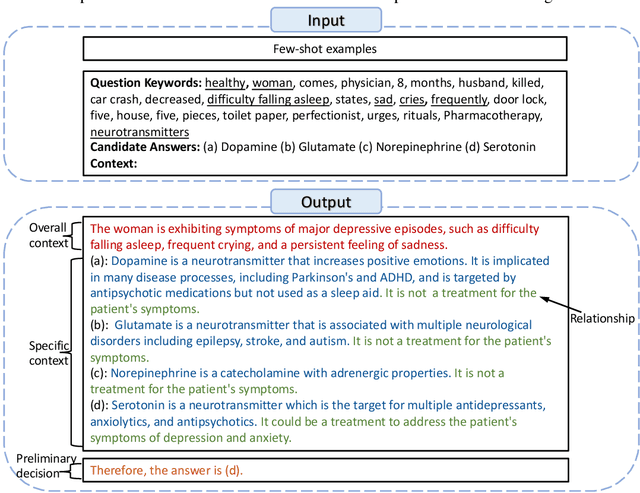

Large language models (LLMs) demonstrate remarkable medical expertise, but data privacy concerns impede their direct use in healthcare environments. Although offering improved data privacy protection, domain-specific small language models (SLMs) often underperform LLMs, emphasizing the need for methods that reduce this performance gap while alleviating privacy concerns. In this paper, we present a simple yet effective method that harnesses LLMs' medical proficiency to boost SLM performance in medical tasks under privacy-restricted scenarios. Specifically, we mitigate patient privacy issues by extracting keywords from medical data and prompting the LLM to generate a medical knowledge-intensive context by simulating clinicians' thought processes. This context serves as additional input for SLMs, augmenting their decision-making capabilities. Our method significantly enhances performance in both few-shot and full training settings across three medical knowledge-intensive tasks, achieving up to a 22.57% increase in absolute accuracy compared to SLM fine-tuning without context, and sets new state-of-the-art results in two medical tasks within privacy-restricted scenarios. Further out-of-domain testing and experiments in two general domain datasets showcase its generalizability and broad applicability.