 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLingxiao Li
Debiased Distribution Compression
Apr 18, 2024
Modern compression methods can summarize a target distribution $\mathbb{P}$ more succinctly than i.i.d. sampling but require access to a low-bias input sequence like a Markov chain converging quickly to $\mathbb{P}$. We introduce a new suite of compression methods suitable for compression with biased input sequences. Given $n$ points targeting the wrong distribution and quadratic time, Stein Kernel Thinning (SKT) returns $\sqrt{n}$ equal-weighted points with $\widetilde{O}(n^{-1/2})$ maximum mean discrepancy (MMD) to $\mathbb {P}$. For larger-scale compression tasks, Low-rank SKT achieves the same feat in sub-quadratic time using an adaptive low-rank debiasing procedure that may be of independent interest. For downstream tasks that support simplex or constant-preserving weights, Stein Recombination and Stein Cholesky achieve even greater parsimony, matching the guarantees of SKT with as few as $\operatorname{poly-log}(n)$ weighted points. Underlying these advances are new guarantees for the quality of simplex-weighted coresets, the spectral decay of kernel matrices, and the covering numbers of Stein kernel Hilbert spaces. In our experiments, our techniques provide succinct and accurate posterior summaries while overcoming biases due to burn-in, approximate Markov chain Monte Carlo, and tempering.
LLsM: Generative Linguistic Steganography with Large Language Model
Feb 06, 2024Linguistic Steganography (LS) tasks aim to generate steganographic text (stego) based on secret information. Only authorized recipients can perceive the existence of secrets in the texts and extract them, thereby preserving privacy. However, the controllability of the stego generated by existing schemes is poor, and the stego is difficult to contain specific discourse characteristics such as style. As a result, the stego is easily detectable, compromising covert communication. To address these problems, this paper proposes LLsM, the first LS with the Large Language Model (LLM). We fine-tuned the LLaMA2 with a large-scale constructed dataset encompassing rich discourse characteristics, which enables the fine-tuned LLM to generate texts with specific discourse in a controllable manner. Then the discourse is used as guiding information and inputted into the fine-tuned LLM in the form of the Prompt together with secret. On this basis, the constructed candidate pool will be range encoded and use secret to determine the interval. The same prefix of this interval's beginning and ending is the secret embedded at this moment. Experiments show that LLsM performs superior to prevalent LS-task and related-task baselines regarding text quality, statistical analysis, discourse matching, and anti-steganalysis. In particular, LLsM's MAUVE matric surpasses some baselines by 70%-80%, and its anti-steganalysis performance is 30%-40% higher. Notably, we also present examples of longer stegos generated by LLsM, showing its potential superiority in long LS tasks.
Monitoring and Adapting ML Models on Mobile Devices
May 17, 2023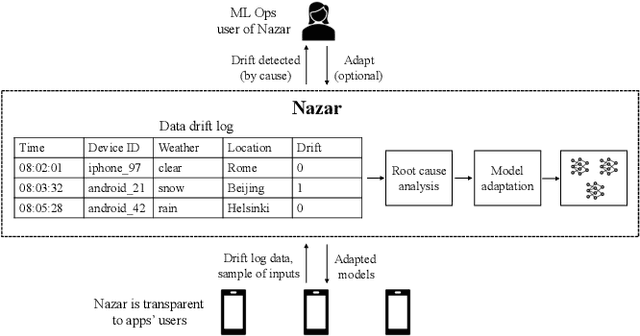

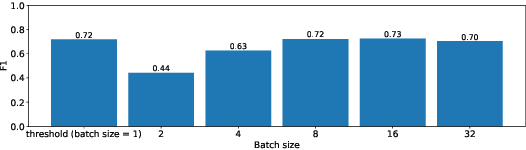
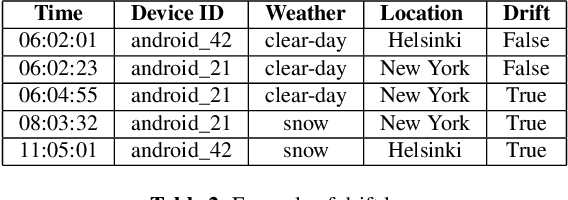
ML models are increasingly being pushed to mobile devices, for low-latency inference and offline operation. However, once the models are deployed, it is hard for ML operators to track their accuracy, which can degrade unpredictably (e.g., due to data drift). We design the first end-to-end system for continuously monitoring and adapting models on mobile devices without requiring feedback from users. Our key observation is that often model degradation is due to a specific root cause, which may affect a large group of devices. Therefore, once the system detects a consistent degradation across a large number of devices, it employs a root cause analysis to determine the origin of the problem and applies a cause-specific adaptation. We evaluate the system on two computer vision datasets, and show it consistently boosts accuracy compared to existing approaches. On a dataset containing photos collected from driving cars, our system improves the accuracy on average by 15%.
Self-Consistent Velocity Matching of Probability Flows
Jan 31, 2023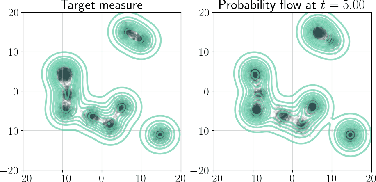

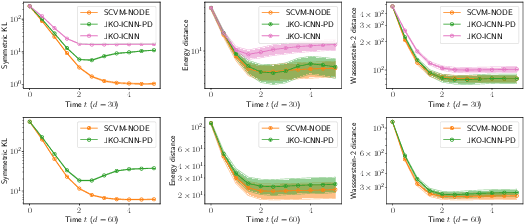
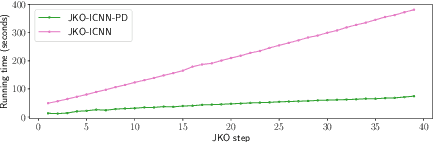
We present a discretization-free scalable framework for solving a large class of mass-conserving partial differential equations (PDEs), including the time-dependent Fokker-Planck equation and the Wasserstein gradient flow. The main observation is that the time-varying velocity field of the PDE solution needs to be self-consistent: it must satisfy a fixed-point equation involving the flow characterized by the same velocity field. By parameterizing the flow as a time-dependent neural network, we propose an end-to-end iterative optimization framework called self-consistent velocity matching to solve this class of PDEs. Compared to existing approaches, our method does not suffer from temporal or spatial discretization, covers a wide range of PDEs, and scales to high dimensions. Experimentally, our method recovers analytical solutions accurately when they are available and achieves comparable or better performance in high dimensions with less training time compared to recent large-scale JKO-based methods that are designed for solving a more restrictive family of PDEs.
The Euclidean Space is Evil: Hyperbolic Attribute Editing for Few-shot Image Generation
Nov 22, 2022



Few-shot image generation is a challenging task since it aims to generate diverse new images for an unseen category with only a few images. Existing methods suffer from the trade-off between the quality and diversity of generated images. To tackle this problem, we propose Hyperbolic Attribute Editing (HAE), a simple yet effective method. Unlike other methods that work in Euclidean space, HAE captures the hierarchy among images using data from seen categories in hyperbolic space. Given a well-trained HAE, images of unseen categories can be generated by moving the latent code of a given image toward any meaningful directions in the Poincar\'e disk with a fixing radius. Most importantly, the hyperbolic space allows us to control the semantic diversity of the generated images by setting different radii in the disk. Extensive experiments and visualizations demonstrate that HAE is capable of not only generating images with promising quality and diversity using limited data but achieving a highly controllable and interpretable editing process.
Sampling with Mollified Interaction Energy Descent
Oct 24, 2022
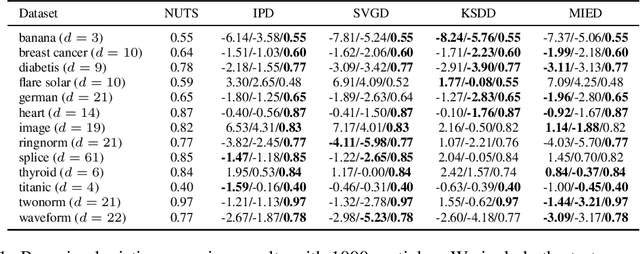
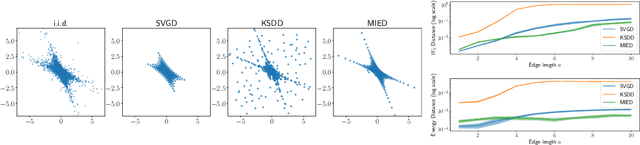
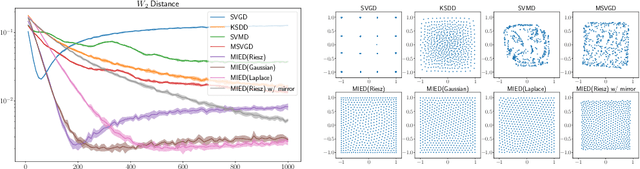
Sampling from a target measure whose density is only known up to a normalization constant is a fundamental problem in computational statistics and machine learning. In this paper, we present a new optimization-based method for sampling called mollified interaction energy descent (MIED). MIED minimizes a new class of energies on probability measures called mollified interaction energies (MIEs). These energies rely on mollifier functions -- smooth approximations of the Dirac delta originated from PDE theory. We show that as the mollifier approaches the Dirac delta, the MIE converges to the chi-square divergence with respect to the target measure and the gradient flow of the MIE agrees with that of the chi-square divergence. Optimizing this energy with proper discretization yields a practical first-order particle-based algorithm for sampling in both unconstrained and constrained domains. We show experimentally that for unconstrained sampling problems our algorithm performs on par with existing particle-based algorithms like SVGD, while for constrained sampling problems our method readily incorporates constrained optimization techniques to handle more flexible constraints with strong performance compared to alternatives.
Wasserstein Iterative Networks for Barycenter Estimation
Jan 28, 2022



Wasserstein barycenters have become popular due to their ability to represent the average of probability measures in a geometrically meaningful way. In this paper, we present an algorithm to approximate the Wasserstein-2 barycenters of continuous measures via a generative model. Previous approaches rely on regularization (entropic/quadratic) which introduces bias or on input convex neural networks which are not expressive enough for large-scale tasks. In contrast, our algorithm does not introduce bias and allows using arbitrary neural networks. In addition, based on the celebrity faces dataset, we construct Ave, celeba! dataset which can be used for quantitative evaluation of barycenter algorithms by using standard metrics of generative models such as FID.
Learning Proximal Operators to Discover Multiple Optima
Jan 28, 2022



Finding multiple solutions of non-convex optimization problems is a ubiquitous yet challenging task. Typical existing solutions either apply single-solution optimization methods from multiple random initial guesses or search in the vicinity of found solutions using ad hoc heuristics. We present an end-to-end method to learn the proximal operator across a family of non-convex problems, which can then be used to recover multiple solutions for unseen problems at test time. Our method only requires access to the objectives without needing the supervision of ground truth solutions. Notably, the added proximal regularization term elevates the convexity of our formulation: by applying recent theoretical results, we show that for weakly-convex objectives and under mild regularity conditions, training of the proximal operator converges globally in the over-parameterized setting. We further present a benchmark for multi-solution optimization including a wide range of applications and evaluate our method to demonstrate its effectiveness.
Do Neural Optimal Transport Solvers Work? A Continuous Wasserstein-2 Benchmark
Jun 03, 2021



Despite the recent popularity of neural network-based solvers for optimal transport (OT), there is no standard quantitative way to evaluate their performance. In this paper, we address this issue for quadratic-cost transport -- specifically, computation of the Wasserstein-2 distance, a commonly-used formulation of optimal transport in machine learning. To overcome the challenge of computing ground truth transport maps between continuous measures needed to assess these solvers, we use input-convex neural networks (ICNN) to construct pairs of measures whose ground truth OT maps can be obtained analytically. This strategy yields pairs of continuous benchmark measures in high-dimensional spaces such as spaces of images. We thoroughly evaluate existing optimal transport solvers using these benchmark measures. Even though these solvers perform well in downstream tasks, many do not faithfully recover optimal transport maps. To investigate the cause of this discrepancy, we further test the solvers in a setting of image generation. Our study reveals crucial limitations of existing solvers and shows that increased OT accuracy does not necessarily correlate to better results downstream.
Large-Scale Wasserstein Gradient Flows
Jun 01, 2021



Wasserstein gradient flows provide a powerful means of understanding and solving many diffusion equations. Specifically, Fokker-Planck equations, which model the diffusion of probability measures, can be understood as gradient descent over entropy functionals in Wasserstein space. This equivalence, introduced by Jordan, Kinderlehrer and Otto, inspired the so-called JKO scheme to approximate these diffusion processes via an implicit discretization of the gradient flow in Wasserstein space. Solving the optimization problem associated to each JKO step, however, presents serious computational challenges. We introduce a scalable method to approximate Wasserstein gradient flows, targeted to machine learning applications. Our approach relies on input-convex neural networks (ICNNs) to discretize the JKO steps, which can be optimized by stochastic gradient descent. Unlike previous work, our method does not require domain discretization or particle simulation. As a result, we can sample from the measure at each time step of the diffusion and compute its probability density. We demonstrate our algorithm's performance by computing diffusions following the Fokker-Planck equation and apply it to unnormalized density sampling as well as nonlinear filtering.