 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChengzhi Mao
ImageNet-D: Benchmarking Neural Network Robustness on Diffusion Synthetic Object
Mar 27, 2024




We establish rigorous benchmarks for visual perception robustness. Synthetic images such as ImageNet-C, ImageNet-9, and Stylized ImageNet provide specific type of evaluation over synthetic corruptions, backgrounds, and textures, yet those robustness benchmarks are restricted in specified variations and have low synthetic quality. In this work, we introduce generative model as a data source for synthesizing hard images that benchmark deep models' robustness. Leveraging diffusion models, we are able to generate images with more diversified backgrounds, textures, and materials than any prior work, where we term this benchmark as ImageNet-D. Experimental results show that ImageNet-D results in a significant accuracy drop to a range of vision models, from the standard ResNet visual classifier to the latest foundation models like CLIP and MiniGPT-4, significantly reducing their accuracy by up to 60\%. Our work suggests that diffusion models can be an effective source to test vision models. The code and dataset are available at https://github.com/chenshuang-zhang/imagenet_d.
SelfIE: Self-Interpretation of Large Language Model Embeddings
Mar 26, 2024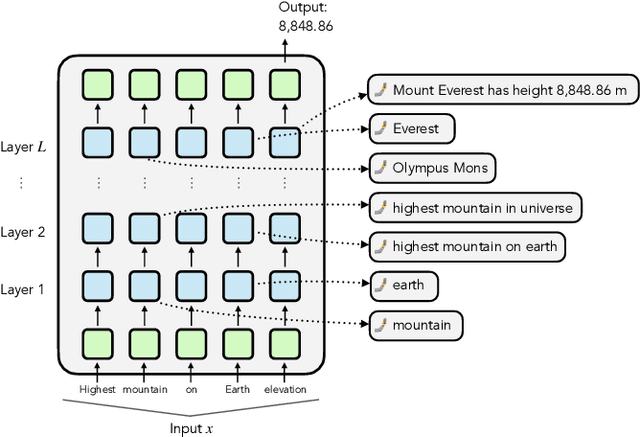
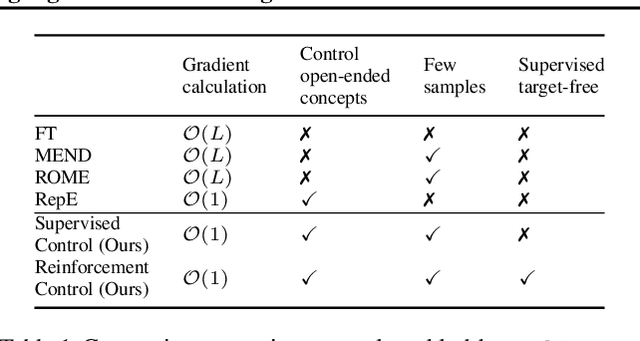
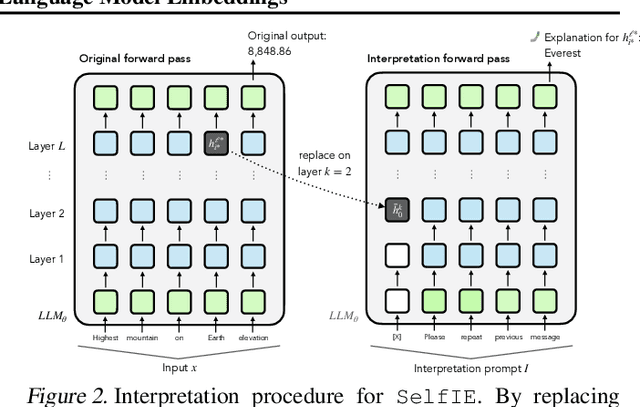
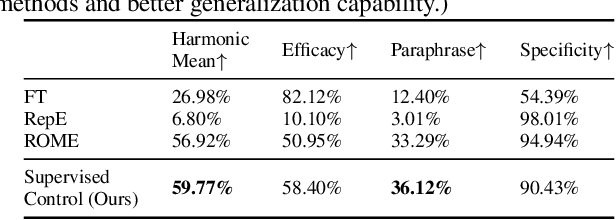
How do large language models (LLMs) obtain their answers? The ability to explain and control an LLM's reasoning process is key for reliability, transparency, and future model developments. We propose SelfIE (Self-Interpretation of Embeddings), a framework that enables LLMs to interpret their own embeddings in natural language by leveraging their ability to respond to inquiries about a given passage. Capable of interpreting open-world concepts in the hidden embeddings, SelfIE reveals LLM internal reasoning in cases such as making ethical decisions, internalizing prompt injection, and recalling harmful knowledge. SelfIE's text descriptions on hidden embeddings also open up new avenues to control LLM reasoning. We propose Supervised Control, which allows editing open-ended concepts while only requiring gradient computation of individual layer. We extend RLHF to hidden embeddings and propose Reinforcement Control that erases harmful knowledge in LLM without supervision targets.
Raidar: geneRative AI Detection viA Rewriting
Jan 23, 2024We find that large language models (LLMs) are more likely to modify human-written text than AI-generated text when tasked with rewriting. This tendency arises because LLMs often perceive AI-generated text as high-quality, leading to fewer modifications. We introduce a method to detect AI-generated content by prompting LLMs to rewrite text and calculating the editing distance of the output. We dubbed our geneRative AI Detection viA Rewriting method Raidar. Raidar significantly improves the F1 detection scores of existing AI content detection models -- both academic and commercial -- across various domains, including News, creative writing, student essays, code, Yelp reviews, and arXiv papers, with gains of up to 29 points. Operating solely on word symbols without high-dimensional features, our method is compatible with black box LLMs, and is inherently robust on new content. Our results illustrate the unique imprint of machine-generated text through the lens of the machines themselves.
Robustifying Language Models with Test-Time Adaptation
Oct 29, 2023Large-scale language models achieved state-of-the-art performance over a number of language tasks. However, they fail on adversarial language examples, which are sentences optimized to fool the language models but with similar semantic meanings for humans. While prior work focuses on making the language model robust at training time, retraining for robustness is often unrealistic for large-scale foundation models. Instead, we propose to make the language models robust at test time. By dynamically adapting the input sentence with predictions from masked words, we show that we can reverse many language adversarial attacks. Since our approach does not require any training, it works for novel tasks at test time and can adapt to novel adversarial corruptions. Visualizations and empirical results on two popular sentence classification datasets demonstrate that our method can repair adversarial language attacks over 65% o
Interpreting and Controlling Vision Foundation Models via Text Explanations
Oct 16, 2023Large-scale pre-trained vision foundation models, such as CLIP, have become de facto backbones for various vision tasks. However, due to their black-box nature, understanding the underlying rules behind these models' predictions and controlling model behaviors have remained open challenges. We present a framework for interpreting vision transformer's latent tokens with natural language. Given a latent token, our framework retains its semantic information to the final layer using transformer's local operations and retrieves the closest text for explanation. Our approach enables understanding of model visual reasoning procedure without needing additional model training or data collection. Based on the obtained interpretations, our framework allows for model editing that controls model reasoning behaviors and improves model robustness against biases and spurious correlations.
Towards Causal Deep Learning for Vulnerability Detection
Oct 13, 2023
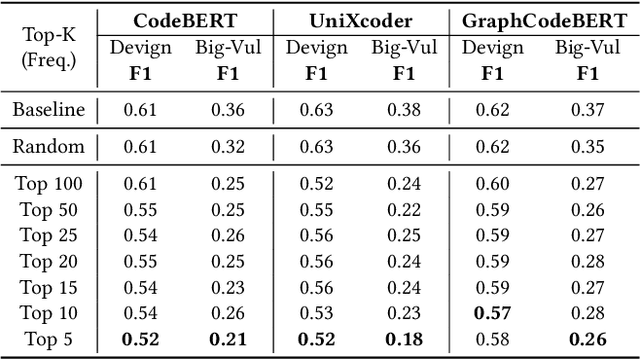
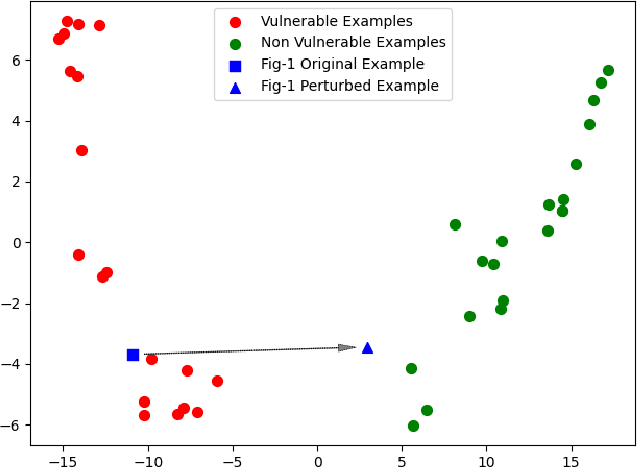
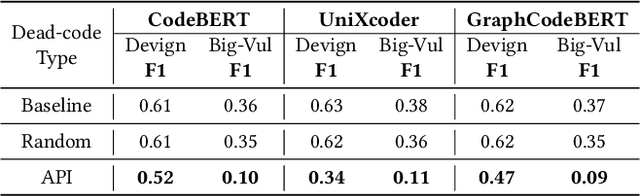
Deep learning vulnerability detection has shown promising results in recent years. However, an important challenge that still blocks it from being very useful in practice is that the model is not robust under perturbation and it cannot generalize well over the out-of-distribution (OOD) data, e.g., applying a trained model to unseen projects in real world. We hypothesize that this is because the model learned non-robust features, e.g., variable names, that have spurious correlations with labels. When the perturbed and OOD datasets no longer have the same spurious features, the model prediction fails. To address the challenge, in this paper, we introduced causality into deep learning vulnerability detection. Our approach CausalVul consists of two phases. First, we designed novel perturbations to discover spurious features that the model may use to make predictions. Second, we applied the causal learning algorithms, specifically, do-calculus, on top of existing deep learning models to systematically remove the use of spurious features and thus promote causal based prediction. Our results show that CausalVul consistently improved the model accuracy, robustness and OOD performance for all the state-of-the-art models and datasets we experimented. To the best of our knowledge, this is the first work that introduces do calculus based causal learning to software engineering models and shows it's indeed useful for improving the model accuracy, robustness and generalization. Our replication package is located at https://figshare.com/s/0ffda320dcb96c249ef2.
Monitoring and Adapting ML Models on Mobile Devices
May 17, 2023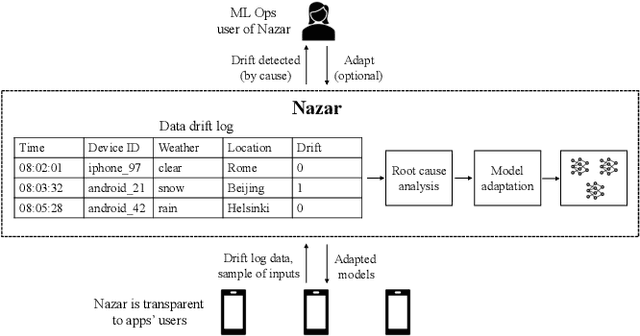

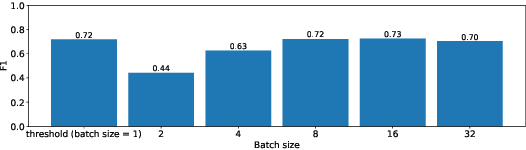
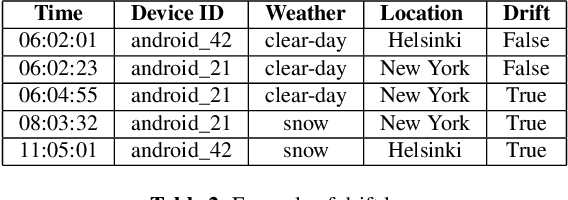
ML models are increasingly being pushed to mobile devices, for low-latency inference and offline operation. However, once the models are deployed, it is hard for ML operators to track their accuracy, which can degrade unpredictably (e.g., due to data drift). We design the first end-to-end system for continuously monitoring and adapting models on mobile devices without requiring feedback from users. Our key observation is that often model degradation is due to a specific root cause, which may affect a large group of devices. Therefore, once the system detects a consistent degradation across a large number of devices, it employs a root cause analysis to determine the origin of the problem and applies a cause-specific adaptation. We evaluate the system on two computer vision datasets, and show it consistently boosts accuracy compared to existing approaches. On a dataset containing photos collected from driving cars, our system improves the accuracy on average by 15%.
Test-time Detection and Repair of Adversarial Samples via Masked Autoencoder
Apr 02, 2023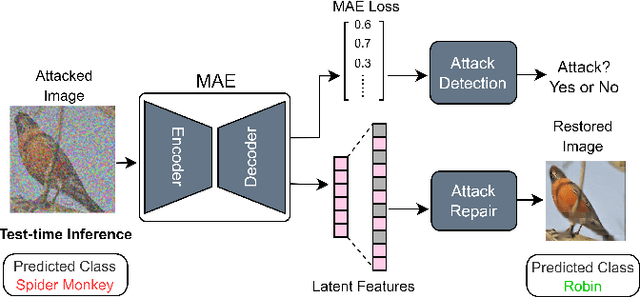
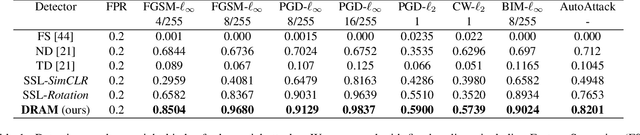
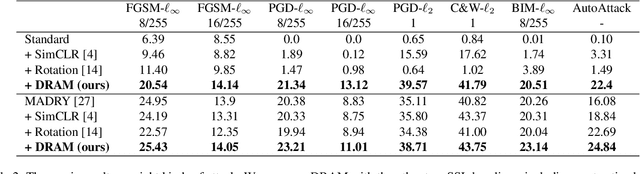
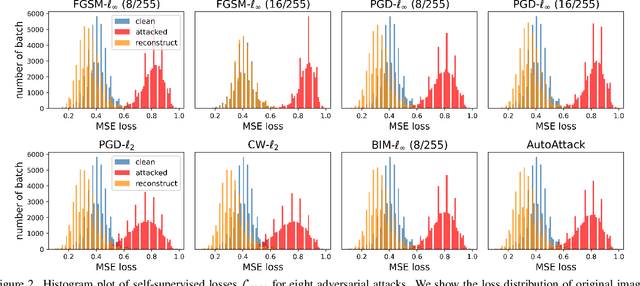
Training-time defenses, known as adversarial training, incur high training costs and do not generalize to unseen attacks. Test-time defenses solve these issues but most existing test-time defenses require adapting the model weights, therefore they do not work on frozen models and complicate model memory management. The only test-time defense that does not adapt model weights aims to adapt the input with self-supervision tasks. However, we empirically found these self-supervision tasks are not sensitive enough to detect adversarial attacks accurately. In this paper, we propose DRAM, a novel defense method to detect and repair adversarial samples at test time via Masked autoencoder (MAE). We demonstrate how to use MAE losses to build a Kolmogorov-Smirnov test to detect adversarial samples. Moreover, we use the MAE losses to calculate input reversal vectors that repair adversarial samples resulting from previously unseen attacks. Results on large-scale ImageNet dataset show that, compared to all detection baselines evaluated, DRAM achieves the best detection rate (82% on average) on all eight adversarial attacks evaluated. For attack repair, DRAM improves the robust accuracy by 6% ~ 41% for standard ResNet50 and 3% ~ 8% for robust ResNet50 compared with the baselines that use contrastive learning and rotation prediction.
Self-Supervised Convolutional Visual Prompts
Mar 01, 2023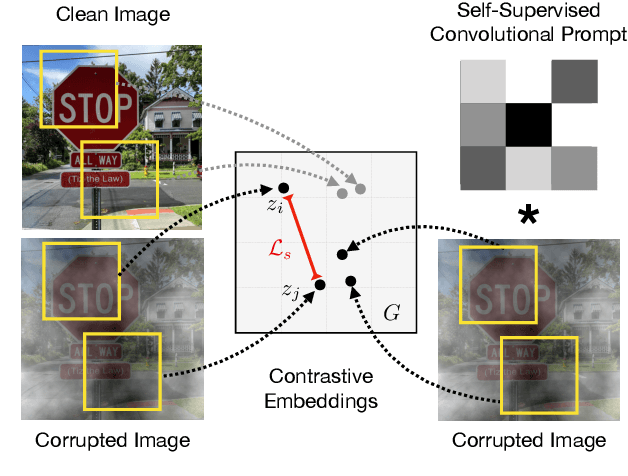
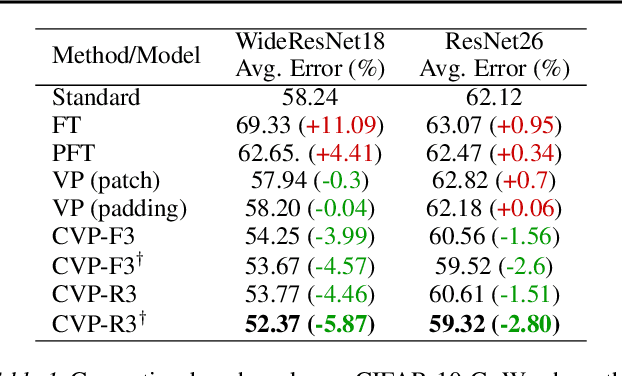
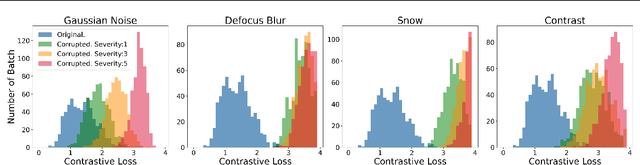
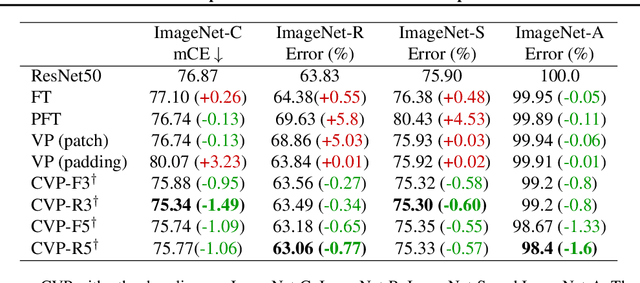
Machine learning models often fail on out-of-distribution (OOD) samples. Visual prompts emerge as a light-weight adaptation method in input space for large-scale vision models. Existing vision prompts optimize a high-dimensional additive vector and require labeled data on training. However, we find this paradigm fails on test-time adaptation when labeled data is unavailable, where the high-dimensional visual prompt overfits to the self-supervised objective. We present convolutional visual prompts for test-time adaptation without labels. Our convolutional prompt is structured and requires fewer trainable parameters (less than 1 % parameters of standard visual prompts). Extensive experiments on a wide variety of OOD recognition tasks show that our approach is effective, improving robustness by up to 5.87 % over a number of large-scale model architectures.
Understanding Zero-Shot Adversarial Robustness for Large-Scale Models
Dec 14, 2022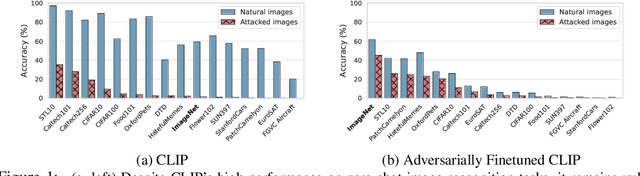
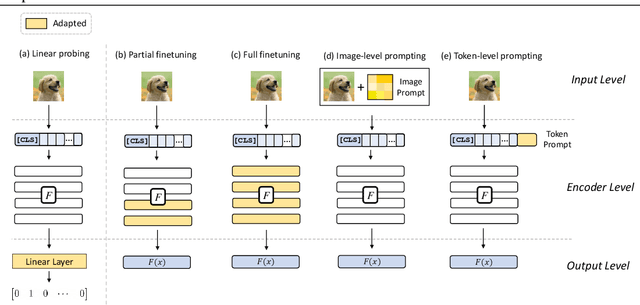
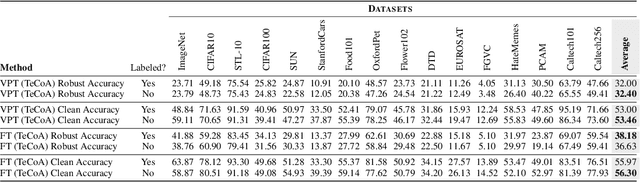
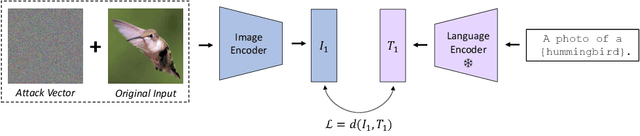
Pretrained large-scale vision-language models like CLIP have exhibited strong generalization over unseen tasks. Yet imperceptible adversarial perturbations can significantly reduce CLIP's performance on new tasks. In this work, we identify and explore the problem of \emph{adapting large-scale models for zero-shot adversarial robustness}. We first identify two key factors during model adaption -- training losses and adaptation methods -- that affect the model's zero-shot adversarial robustness. We then propose a text-guided contrastive adversarial training loss, which aligns the text embeddings and the adversarial visual features with contrastive learning on a small set of training data. We apply this training loss to two adaption methods, model finetuning and visual prompt tuning. We find that visual prompt tuning is more effective in the absence of texts, while finetuning wins in the existence of text guidance. Overall, our approach significantly improves the zero-shot adversarial robustness over CLIP, seeing an average improvement of over 31 points over ImageNet and 15 zero-shot datasets. We hope this work can shed light on understanding the zero-shot adversarial robustness of large-scale models.