 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChenshuang Zhang
Towards Understanding Dual BN In Hybrid Adversarial Training
Mar 28, 2024
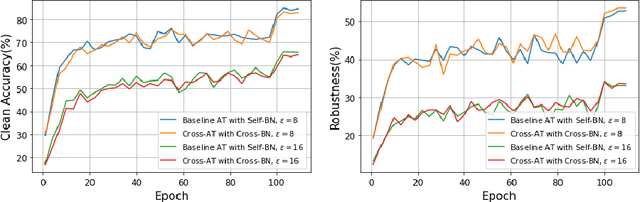

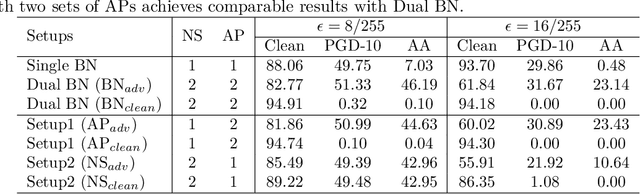
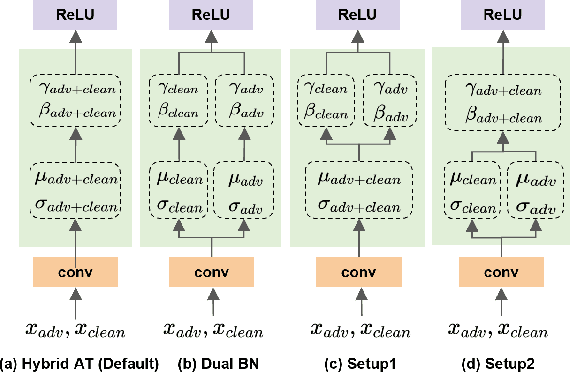
There is a growing concern about applying batch normalization (BN) in adversarial training (AT), especially when the model is trained on both adversarial samples and clean samples (termed Hybrid-AT). With the assumption that adversarial and clean samples are from two different domains, a common practice in prior works is to adopt Dual BN, where BN and BN are used for adversarial and clean branches, respectively. A popular belief for motivating Dual BN is that estimating normalization statistics of this mixture distribution is challenging and thus disentangling it for normalization achieves stronger robustness. In contrast to this belief, we reveal that disentangling statistics plays a less role than disentangling affine parameters in model training. This finding aligns with prior work (Rebuffi et al., 2023), and we build upon their research for further investigations. We demonstrate that the domain gap between adversarial and clean samples is not very large, which is counter-intuitive considering the significant influence of adversarial perturbation on the model accuracy. We further propose a two-task hypothesis which serves as the empirical foundation and a unified framework for Hybrid-AT improvement. We also investigate Dual BN in test-time and reveal that affine parameters characterize the robustness during inference. Overall, our work sheds new light on understanding the mechanism of Dual BN in Hybrid-AT and its underlying justification.
ImageNet-D: Benchmarking Neural Network Robustness on Diffusion Synthetic Object
Mar 27, 2024



We establish rigorous benchmarks for visual perception robustness. Synthetic images such as ImageNet-C, ImageNet-9, and Stylized ImageNet provide specific type of evaluation over synthetic corruptions, backgrounds, and textures, yet those robustness benchmarks are restricted in specified variations and have low synthetic quality. In this work, we introduce generative model as a data source for synthesizing hard images that benchmark deep models' robustness. Leveraging diffusion models, we are able to generate images with more diversified backgrounds, textures, and materials than any prior work, where we term this benchmark as ImageNet-D. Experimental results show that ImageNet-D results in a significant accuracy drop to a range of vision models, from the standard ResNet visual classifier to the latest foundation models like CLIP and MiniGPT-4, significantly reducing their accuracy by up to 60\%. Our work suggests that diffusion models can be an effective source to test vision models. The code and dataset are available at https://github.com/chenshuang-zhang/imagenet_d.
Robustness of SAM: Segment Anything Under Corruptions and Beyond
Jun 13, 2023
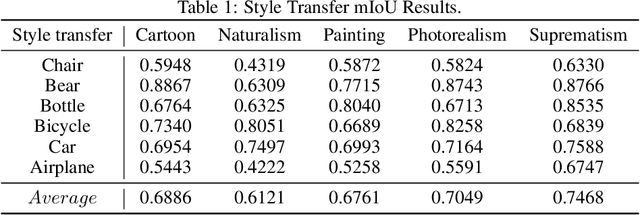

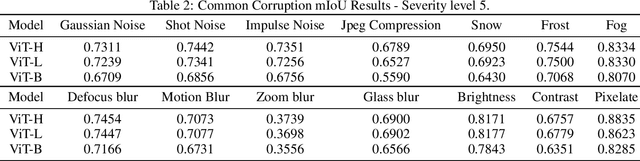
Segment anything model (SAM), as the name suggests, is claimed to be capable of cutting out any object. SAM is a vision foundation model which demonstrates impressive zero-shot transfer performance with the guidance of a prompt. However, there is currently a lack of comprehensive evaluation of its robustness performance under various types of corruptions. Prior works show that SAM is biased towards texture (style) rather than shape, motivated by which we start by investigating SAM's robustness against style transfer, which is synthetic corruption. With the effect of corruptions interpreted as a style change, we further evaluate its robustness on 15 common corruptions with 5 severity levels for each real-world corruption. Beyond the corruptions, we further evaluate the SAM robustness on local occlusion and adversarial perturbations. Overall, this work provides a comprehensive empirical study on the robustness of the SAM under corruptions and beyond.
Attack-SAM: Towards Attacking Segment Anything Model With Adversarial Examples
May 08, 2023



Segment Anything Model (SAM) has attracted significant attention recently, due to its impressive performance on various downstream tasks in a zero-short manner. Computer vision (CV) area might follow the natural language processing (NLP) area to embark on a path from task-specific vision models toward foundation models. However, deep vision models are widely recognized as vulnerable to adversarial examples, which fool the model to make wrong predictions with imperceptible perturbation. Such vulnerability to adversarial attacks causes serious concerns when applying deep models to security-sensitive applications. Therefore, it is critical to know whether the vision foundation model SAM can also be fooled by adversarial attacks. To the best of our knowledge, our work is the first of its kind to conduct a comprehensive investigation on how to attack SAM with adversarial examples. With the basic attack goal set to mask removal, we investigate the adversarial robustness of SAM in the full white-box setting and transfer-based black-box settings. Beyond the basic goal of mask removal, we further investigate and find that it is possible to generate any desired mask by the adversarial attack.
One Small Step for Generative AI, One Giant Leap for AGI: A Complete Survey on ChatGPT in AIGC Era
Apr 04, 2023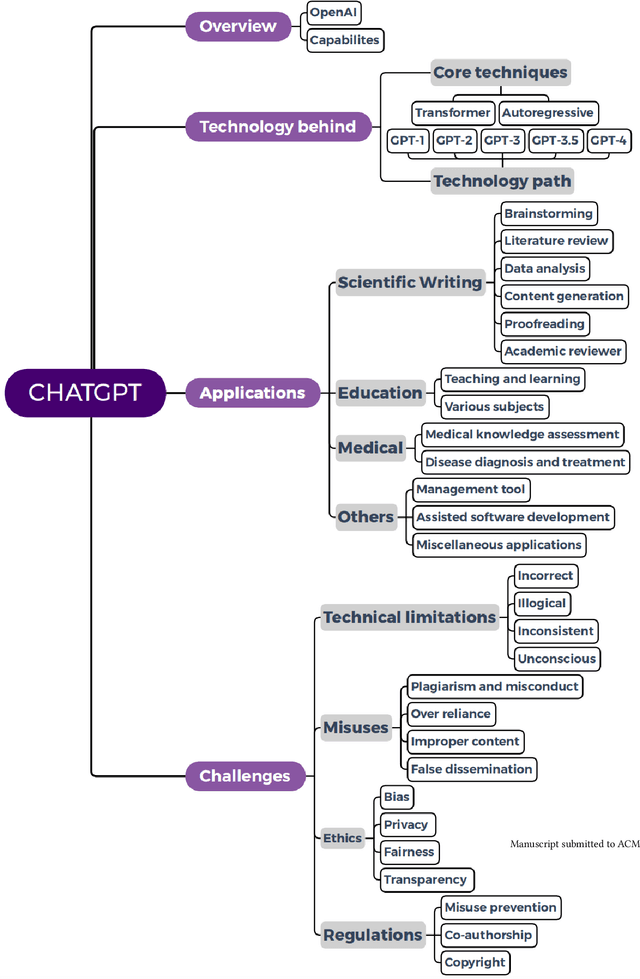

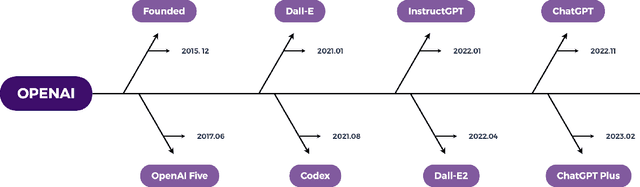

OpenAI has recently released GPT-4 (a.k.a. ChatGPT plus), which is demonstrated to be one small step for generative AI (GAI), but one giant leap for artificial general intelligence (AGI). Since its official release in November 2022, ChatGPT has quickly attracted numerous users with extensive media coverage. Such unprecedented attention has also motivated numerous researchers to investigate ChatGPT from various aspects. According to Google scholar, there are more than 500 articles with ChatGPT in their titles or mentioning it in their abstracts. Considering this, a review is urgently needed, and our work fills this gap. Overall, this work is the first to survey ChatGPT with a comprehensive review of its underlying technology, applications, and challenges. Moreover, we present an outlook on how ChatGPT might evolve to realize general-purpose AIGC (a.k.a. AI-generated content), which will be a significant milestone for the development of AGI.
A Survey on Graph Diffusion Models: Generative AI in Science for Molecule, Protein and Material
Apr 04, 2023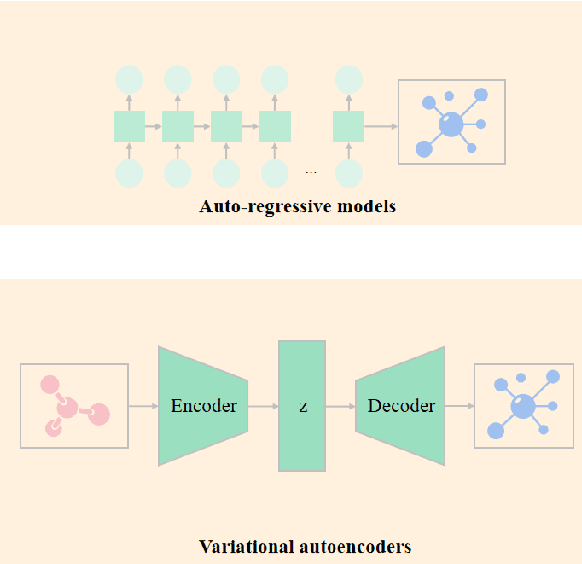
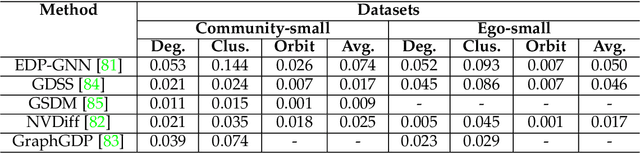
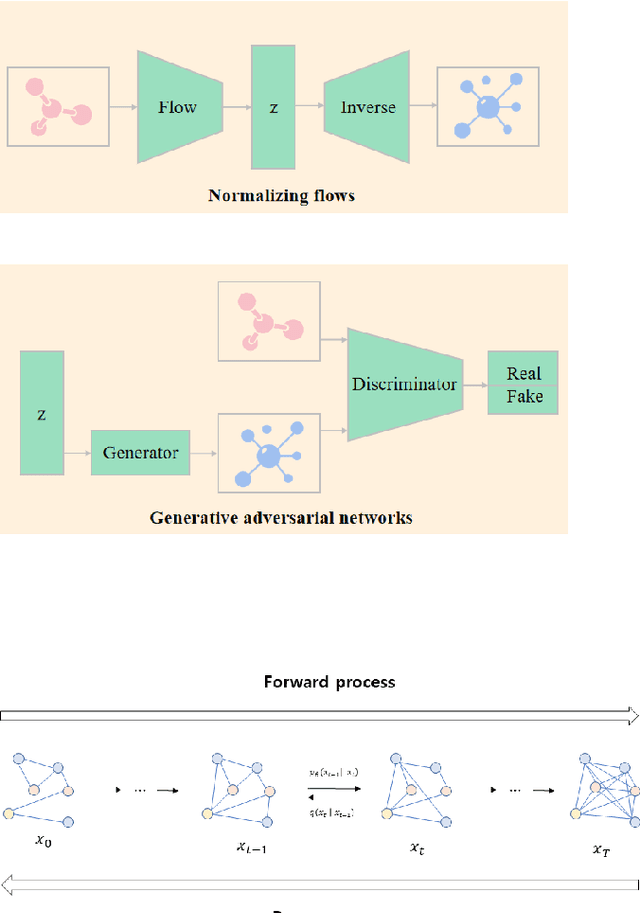
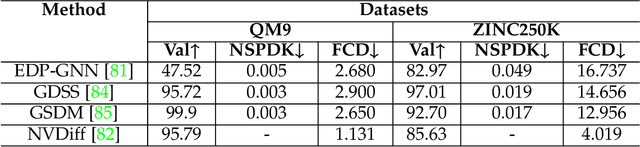
Diffusion models have become a new SOTA generative modeling method in various fields, for which there are multiple survey works that provide an overall survey. With the number of articles on diffusion models increasing exponentially in the past few years, there is an increasing need for surveys of diffusion models on specific fields. In this work, we are committed to conducting a survey on the graph diffusion models. Even though our focus is to cover the progress of diffusion models in graphs, we first briefly summarize how other generative modeling methods are used for graphs. After that, we introduce the mechanism of diffusion models in various forms, which facilitates the discussion on the graph diffusion models. The applications of graph diffusion models mainly fall into the category of AI-generated content (AIGC) in science, for which we mainly focus on how graph diffusion models are utilized for generating molecules and proteins but also cover other cases, including materials design. Moreover, we discuss the issue of evaluating diffusion models in the graph domain and the existing challenges.
A Survey on Audio Diffusion Models: Text To Speech Synthesis and Enhancement in Generative AI
Apr 02, 2023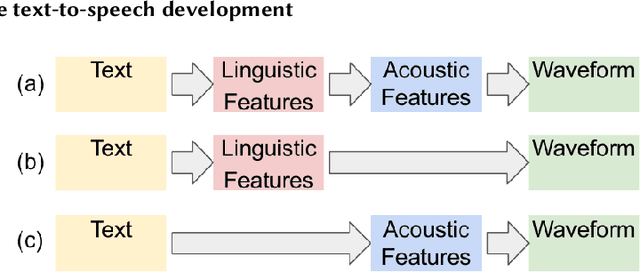
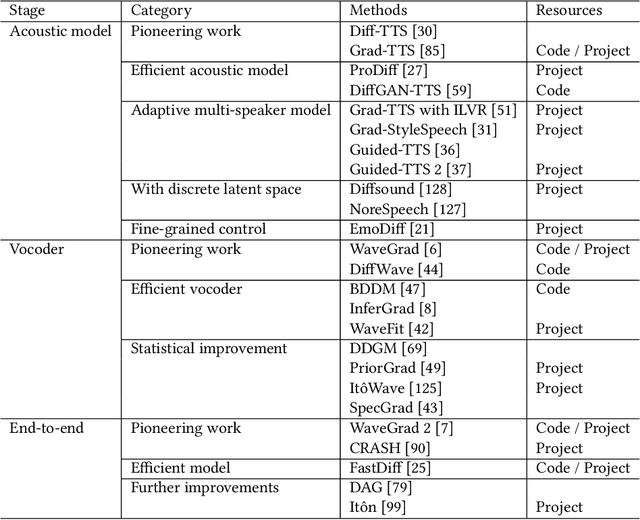
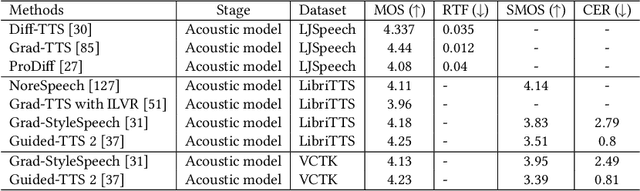
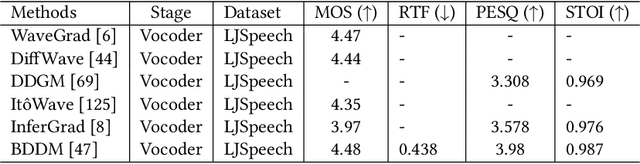
Generative AI has demonstrated impressive performance in various fields, among which speech synthesis is an interesting direction. With the diffusion model as the most popular generative model, numerous works have attempted two active tasks: text to speech and speech enhancement. This work conducts a survey on audio diffusion model, which is complementary to existing surveys that either lack the recent progress of diffusion-based speech synthesis or highlight an overall picture of applying diffusion model in multiple fields. Specifically, this work first briefly introduces the background of audio and diffusion model. As for the text-to-speech task, we divide the methods into three categories based on the stage where diffusion model is adopted: acoustic model, vocoder and end-to-end framework. Moreover, we categorize various speech enhancement tasks by either certain signals are removed or added into the input speech. Comparisons of experimental results and discussions are also covered in this survey.
Text-to-image Diffusion Models in Generative AI: A Survey
Apr 02, 2023


This survey reviews text-to-image diffusion models in the context that diffusion models have emerged to be popular for a wide range of generative tasks. As a self-contained work, this survey starts with a brief introduction of how a basic diffusion model works for image synthesis, followed by how condition or guidance improves learning. Based on that, we present a review of state-of-the-art methods on text-conditioned image synthesis, i.e., text-to-image. We further summarize applications beyond text-to-image generation: text-guided creative generation and text-guided image editing. Beyond the progress made so far, we discuss existing challenges and promising future directions.
A Complete Survey on Generative AI (AIGC): Is ChatGPT from GPT-4 to GPT-5 All You Need?
Mar 21, 2023
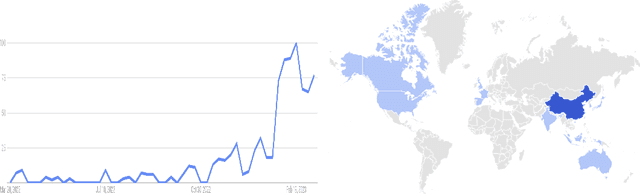
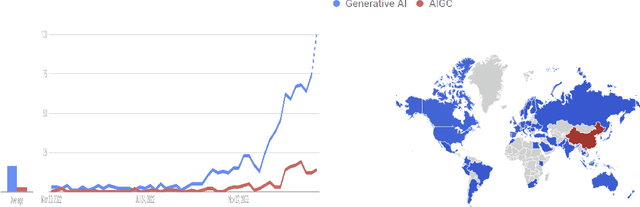
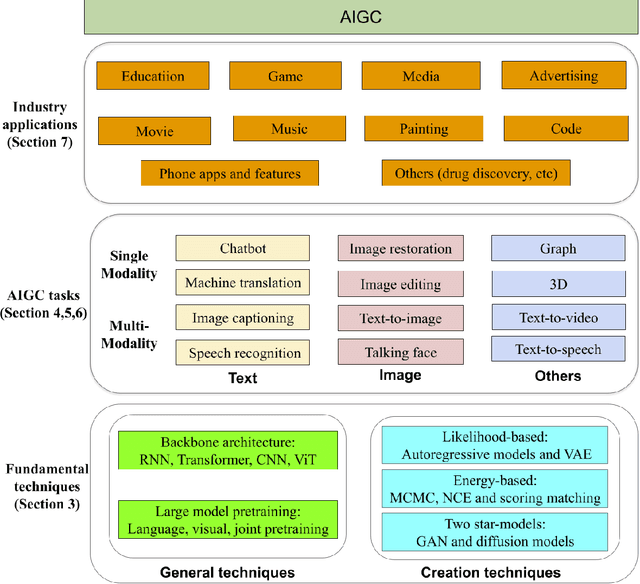
As ChatGPT goes viral, generative AI (AIGC, a.k.a AI-generated content) has made headlines everywhere because of its ability to analyze and create text, images, and beyond. With such overwhelming media coverage, it is almost impossible for us to miss the opportunity to glimpse AIGC from a certain angle. In the era of AI transitioning from pure analysis to creation, it is worth noting that ChatGPT, with its most recent language model GPT-4, is just a tool out of numerous AIGC tasks. Impressed by the capability of the ChatGPT, many people are wondering about its limits: can GPT-5 (or other future GPT variants) help ChatGPT unify all AIGC tasks for diversified content creation? Toward answering this question, a comprehensive review of existing AIGC tasks is needed. As such, our work comes to fill this gap promptly by offering a first look at AIGC, ranging from its techniques to applications. Modern generative AI relies on various technical foundations, ranging from model architecture and self-supervised pretraining to generative modeling methods (like GAN and diffusion models). After introducing the fundamental techniques, this work focuses on the technological development of various AIGC tasks based on their output type, including text, images, videos, 3D content, etc., which depicts the full potential of ChatGPT's future. Moreover, we summarize their significant applications in some mainstream industries, such as education and creativity content. Finally, we discuss the challenges currently faced and present an outlook on how generative AI might evolve in the near future.
A Survey on Masked Autoencoder for Self-supervised Learning in Vision and Beyond
Jul 30, 2022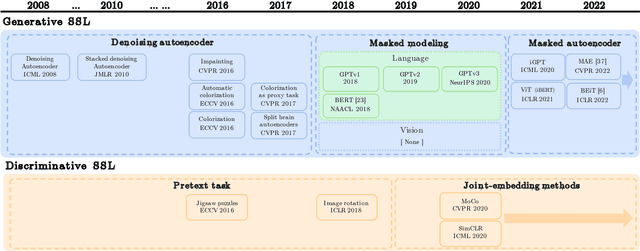

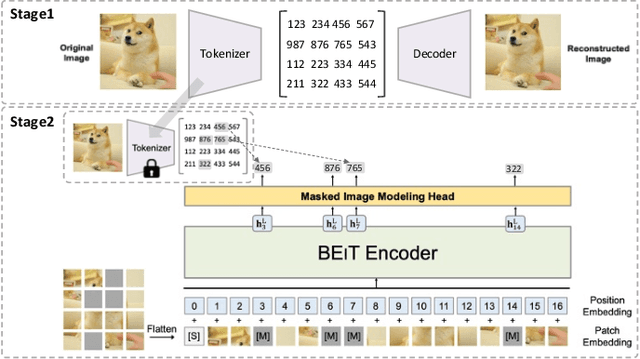
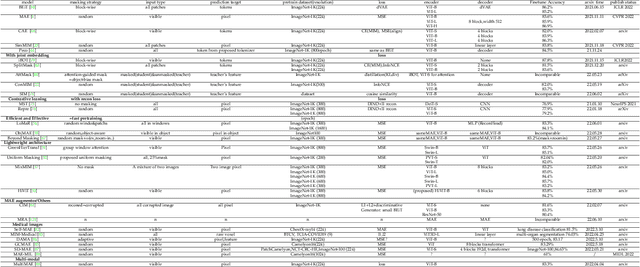
Masked autoencoders are scalable vision learners, as the title of MAE \cite{he2022masked}, which suggests that self-supervised learning (SSL) in vision might undertake a similar trajectory as in NLP. Specifically, generative pretext tasks with the masked prediction (e.g., BERT) have become a de facto standard SSL practice in NLP. By contrast, early attempts at generative methods in vision have been buried by their discriminative counterparts (like contrastive learning); however, the success of mask image modeling has revived the masking autoencoder (often termed denoising autoencoder in the past). As a milestone to bridge the gap with BERT in NLP, masked autoencoder has attracted unprecedented attention for SSL in vision and beyond. This work conducts a comprehensive survey of masked autoencoders to shed insight on a promising direction of SSL. As the first to review SSL with masked autoencoders, this work focuses on its application in vision by discussing its historical developments, recent progress, and implications for diverse applications.