 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLingyun Xu
Task-Oriented Hybrid Beamforming for OFDM-DFRC Systems with Flexibly Controlled Space-Frequency Spectra
Mar 18, 2024
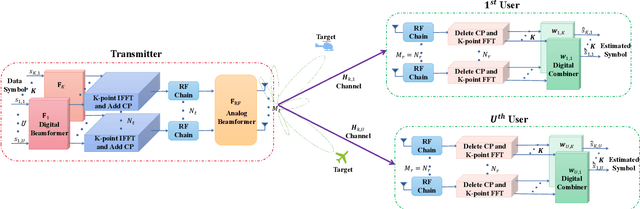
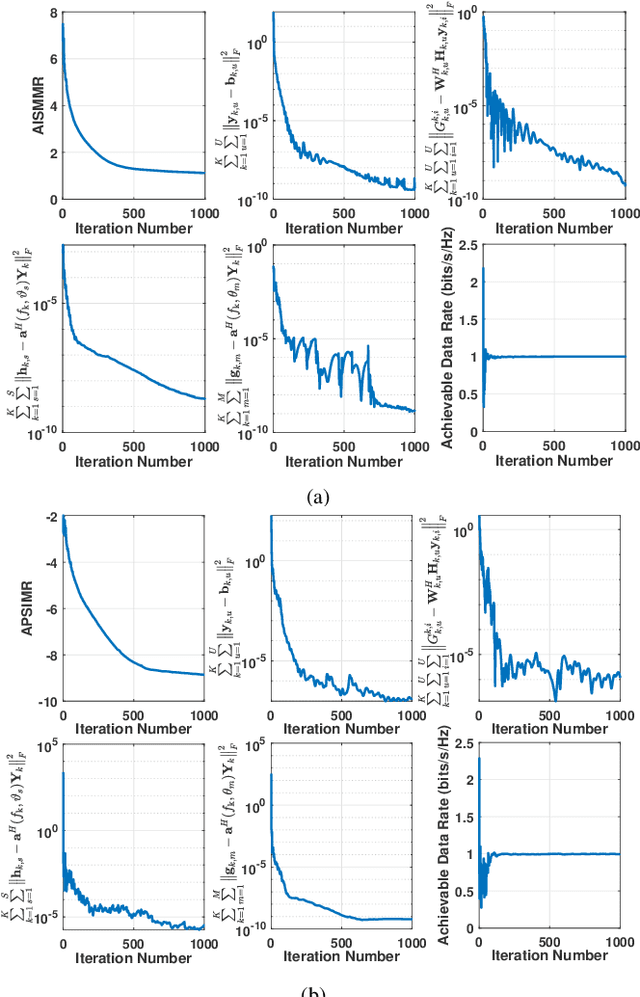
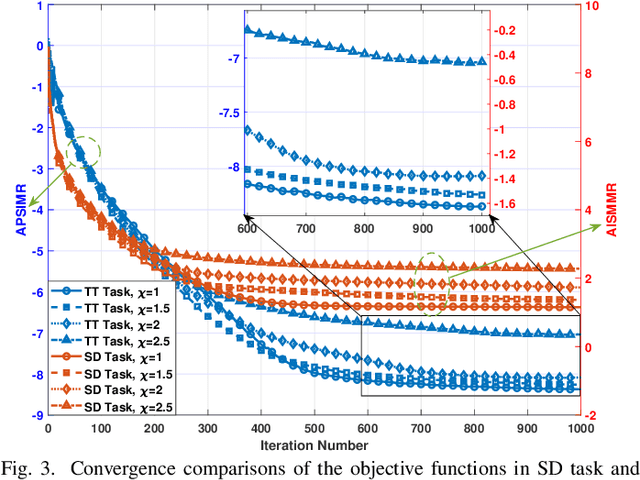
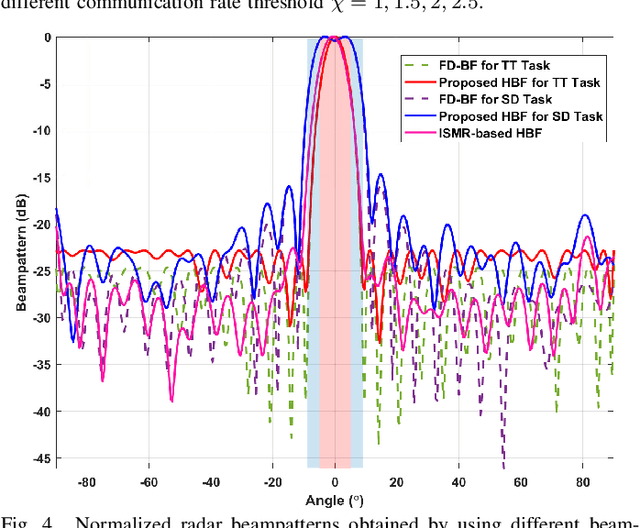
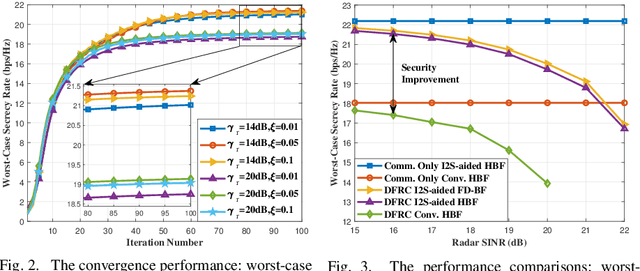
This paper investigates the issues of the hybrid beamforming design for the orthogonal frequency division multiplexing dual-function radar-communication (DFRC) system in multiple task scenarios involving the radar scanning and detection task and the target tracking task. To meet different task requirements of the DFRC system, we introduce two novel radar beampattern metrics, the average integrated sidelobe to minimum mainlobe ratio (AISMMR) and average peak sidelobe to integrated mainlobe ratio (APSIMR), to characterize the space-frequency spectra in different scenarios. Then, two HBF design problems are formulated for two task scenarios by minimizing the AISMMR and APSIMR respectively subject to the constraints of communication quality-of-service (QoS), power budget, and hardware. Due to the non-linearity and close coupling between the analog and digital beamformers in both the objective functions and QoS constraint, the resultant formulated problems are challenging to solve. Towards that end, a unified optimization algorithm based on a consensus alternating direction method of multipliers (CADMM) is proposed to solve these two problems. Moreover, under the unified CADMM framework, the closed-form solutions of primal variables in the original two problems are obtained with low complexity. Numerical simulations are provided to demonstrate the feasibility and effectiveness of the proposed algorithm.
Enhancing Physical Layer Security in Dual-Function Radar-Communication Systems with Hybrid Beamforming Architecture
Mar 12, 2024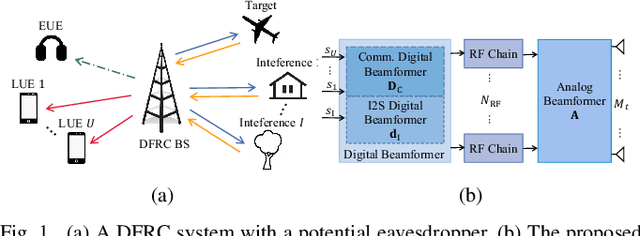

In this letter, we investigate enhancing the physical layer security (PLS) for the dual-function radar-communication (DFRC) system with hybrid beamforming (HBF) architecture, where the base station (BS) achieves downlink communication and radar target detection simultaneously. We consider an eavesdropper intercepting the information transmitted from the BS to the downlink communication users with imperfectly known channel state information. Additionally, the location of the radar target is also imperfectly known by the BS. To enhance PLS in the considered DFRC system, we propose a novel HBF architecture, which introduces a new integrated sensing and security (I2S) symbol. The secure HBF design problem for DFRC is formulated by maximizing the minimum legitimate user communication rate subject to radar interference-plus-noise ratio, eavesdropping rate, hardware and power constraints. To solve this non-convex problem, we propose an alternating optimization based method to jointly optimize transmit and receive beamformers. Numerical simulation results validate the effectiveness of the proposed algorithm and show the superiority of the proposed I2S-aided HBF architecture for achieving DFRC and enhancing PLS.
Temporal Point Cloud Completion with Pose Disturbance
Feb 07, 2022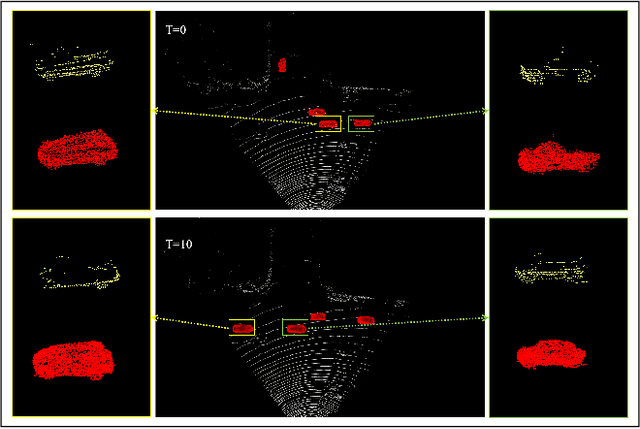

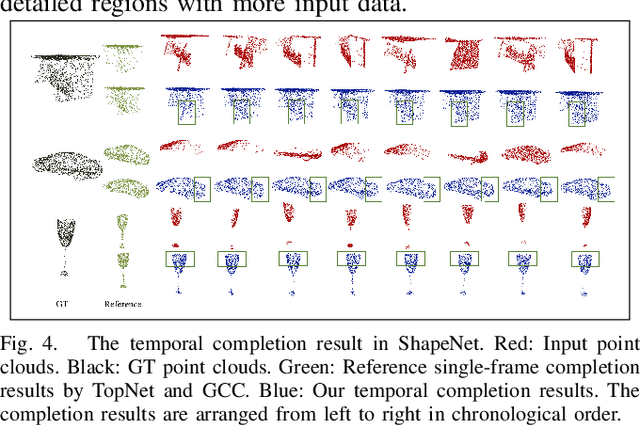
Point clouds collected by real-world sensors are always unaligned and sparse, which makes it hard to reconstruct the complete shape of object from a single frame of data. In this work, we manage to provide complete point clouds from sparse input with pose disturbance by limited translation and rotation. We also use temporal information to enhance the completion model, refining the output with a sequence of inputs. With the help of gated recovery units(GRU) and attention mechanisms as temporal units, we propose a point cloud completion framework that accepts a sequence of unaligned and sparse inputs, and outputs consistent and aligned point clouds. Our network performs in an online manner and presents a refined point cloud for each frame, which enables it to be integrated into any SLAM or reconstruction pipeline. As far as we know, our framework is the first to utilize temporal information and ensure temporal consistency with limited transformation. Through experiments in ShapeNet and KITTI, we prove that our framework is effective in both synthetic and real-world datasets.
Graph-Guided Deformation for Point Cloud Completion
Nov 11, 2021
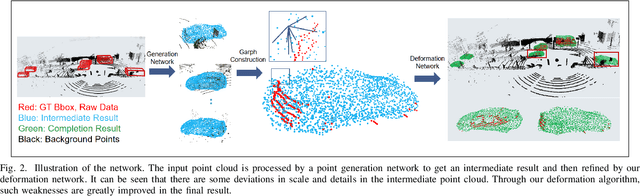
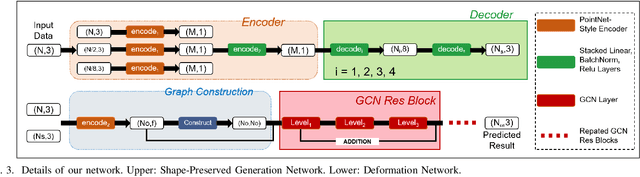

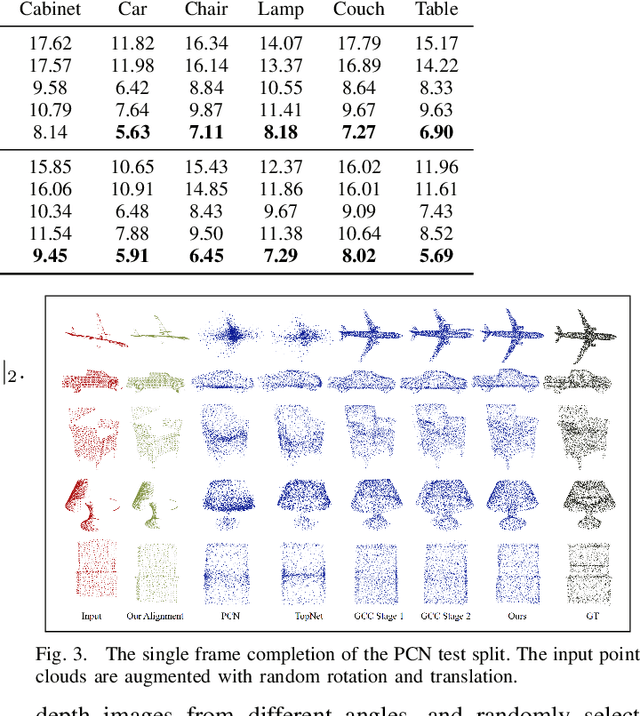
For a long time, the point cloud completion task has been regarded as a pure generation task. After obtaining the global shape code through the encoder, a complete point cloud is generated using the shape priorly learnt by the networks. However, such models are undesirably biased towards prior average objects and inherently limited to fit geometry details. In this paper, we propose a Graph-Guided Deformation Network, which respectively regards the input data and intermediate generation as controlling and supporting points, and models the optimization guided by a graph convolutional network(GCN) for the point cloud completion task. Our key insight is to simulate the least square Laplacian deformation process via mesh deformation methods, which brings adaptivity for modeling variation in geometry details. By this means, we also reduce the gap between the completion task and the mesh deformation algorithms. As far as we know, we are the first to refine the point cloud completion task by mimicing traditional graphics algorithms with GCN-guided deformation. We have conducted extensive experiments on both the simulated indoor dataset ShapeNet, outdoor dataset KITTI, and our self-collected autonomous driving dataset Pandar40. The results show that our method outperforms the existing state-of-the-art algorithms in the 3D point cloud completion task.
PSE-Match: A Viewpoint-free Place Recognition Method with Parallel Semantic Embedding
Aug 01, 2021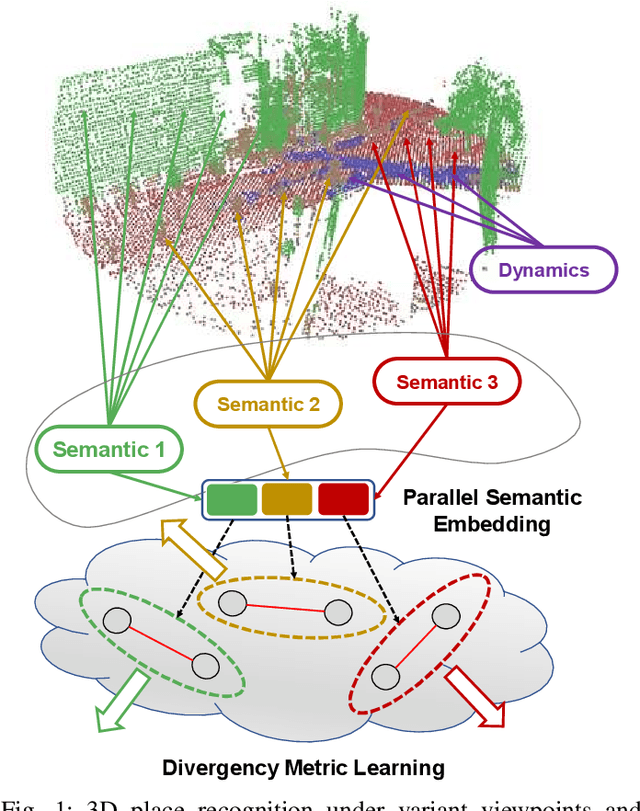
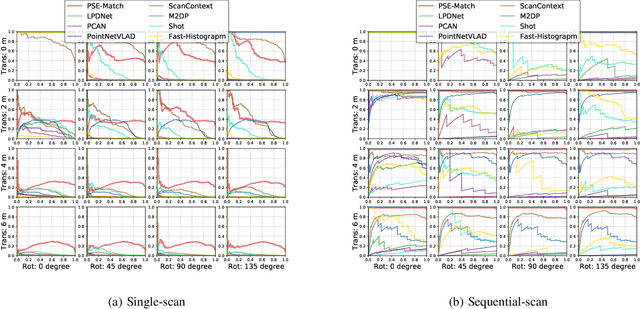
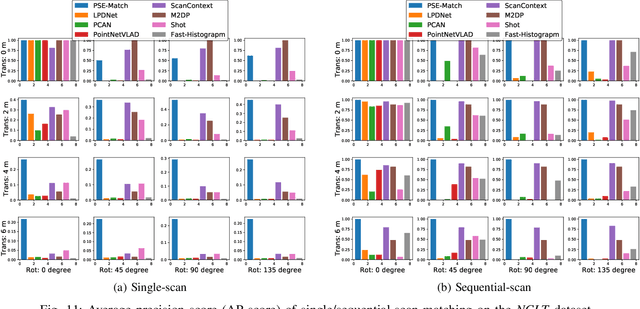
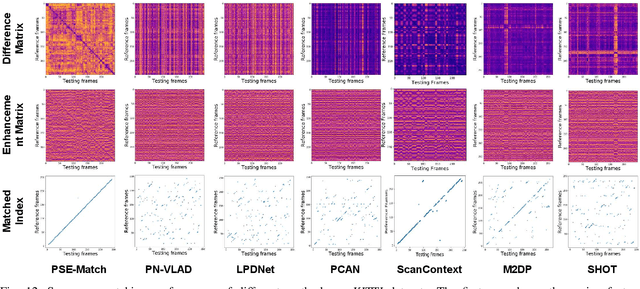
Accurate localization on autonomous driving cars is essential for autonomy and driving safety, especially for complex urban streets and search-and-rescue subterranean environments where high-accurate GPS is not available. However current odometry estimation may introduce the drifting problems in long-term navigation without robust global localization. The main challenges involve scene divergence under the interference of dynamic environments and effective perception of observation and object layout variance from different viewpoints. To tackle these challenges, we present PSE-Match, a viewpoint-free place recognition method based on parallel semantic analysis of isolated semantic attributes from 3D point-cloud models. Compared with the original point cloud, the observed variance of semantic attributes is smaller. PSE-Match incorporates a divergence place learning network to capture different semantic attributes parallelly through the spherical harmonics domain. Using both existing benchmark datasets and two in-field collected datasets, our experiments show that the proposed method achieves above 70% average recall with top one retrieval and above 95% average recall with top ten retrieval cases. And PSE-Match has also demonstrated an obvious generalization ability with a limited training dataset.
3D Segmentation Learning from Sparse Annotations and Hierarchical Descriptors
Jun 06, 2021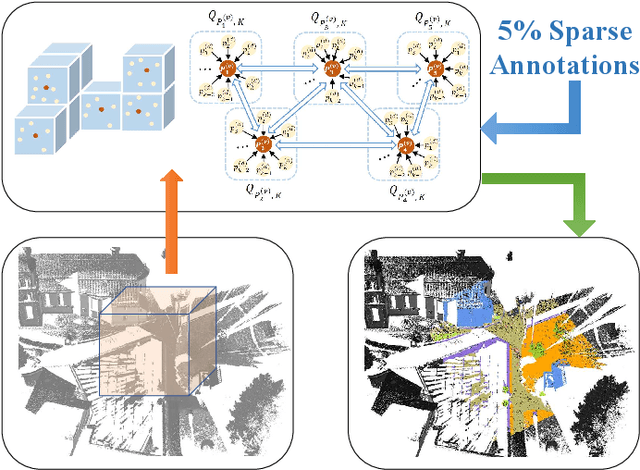

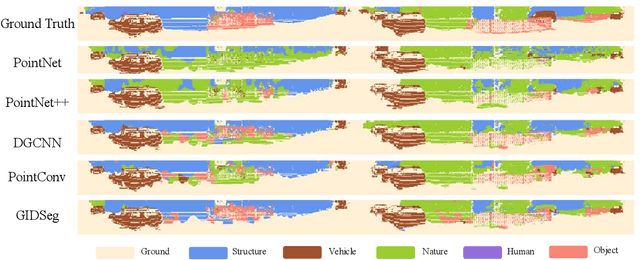
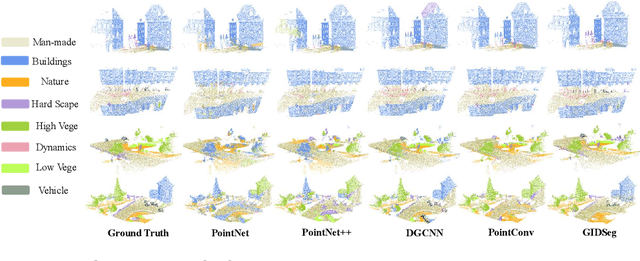
One of the main obstacles to 3D semantic segmentation is the significant amount of endeavor required to generate expensive point-wise annotations for fully supervised training. To alleviate manual efforts, we propose GIDSeg, a novel approach that can simultaneously learn segmentation from sparse annotations via reasoning global-regional structures and individual-vicinal properties. GIDSeg depicts global- and individual- relation via a dynamic edge convolution network coupled with a kernelized identity descriptor. The ensemble effects are obtained by endowing a fine-grained receptive field to a low-resolution voxelized map. In our GIDSeg, an adversarial learning module is also designed to further enhance the conditional constraint of identity descriptors within the joint feature distribution. Despite the apparent simplicity, our proposed approach achieves superior performance over state-of-the-art for inferencing 3D dense segmentation with only sparse annotations. Particularly, with $5\%$ annotations of raw data, GIDSeg outperforms other 3D segmentation methods.
i3dLoc: Image-to-range Cross-domain Localization Robust to Inconsistent Environmental Conditions
Jun 06, 2021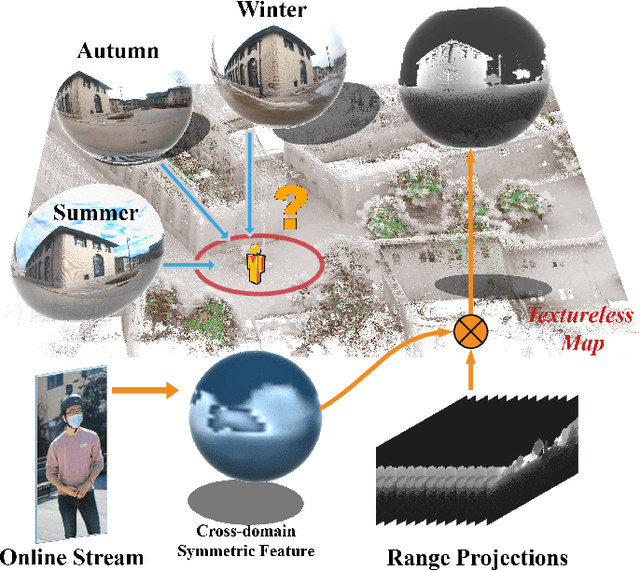

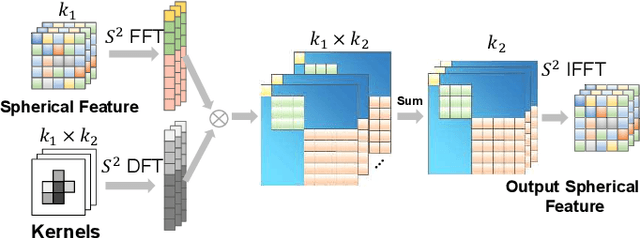
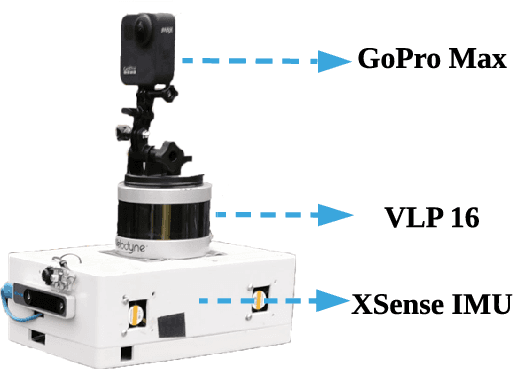
We present a method for localizing a single camera with respect to a point cloud map in indoor and outdoor scenes. The problem is challenging because correspondences of local invariant features are inconsistent across the domains between image and 3D. The problem is even more challenging as the method must handle various environmental conditions such as illumination, weather, and seasonal changes. Our method can match equirectangular images to the 3D range projections by extracting cross-domain symmetric place descriptors. Our key insight is to retain condition-invariant 3D geometry features from limited data samples while eliminating the condition-related features by a designed Generative Adversarial Network. Based on such features, we further design a spherical convolution network to learn viewpoint-invariant symmetric place descriptors. We evaluate our method on extensive self-collected datasets, which involve \textit{Long-term} (variant appearance conditions), \textit{Large-scale} (up to $2km$ structure/unstructured environment), and \textit{Multistory} (four-floor confined space). Our method surpasses other current state-of-the-arts by achieving around $3$ times higher place retrievals to inconsistent environments, and above $3$ times accuracy on online localization. To highlight our method's generalization capabilities, we also evaluate the recognition across different datasets. With a single trained model, i3dLoc can demonstrate reliable visual localization in random conditions.
* 8 Pages, 8 Figures, Accepted Robotics: Science and Systems 2021 paper
MRS-VPR: a multi-resolution sampling based global visual place recognition method
Feb 26, 2019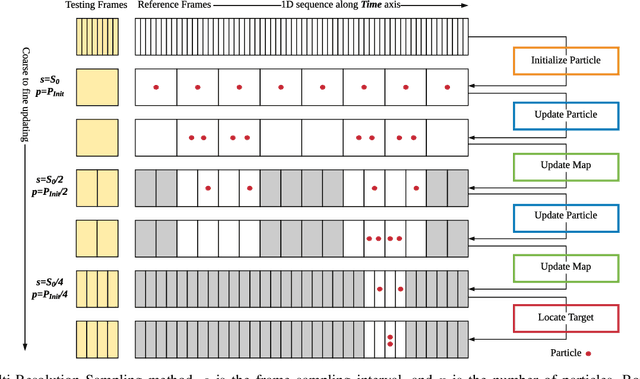
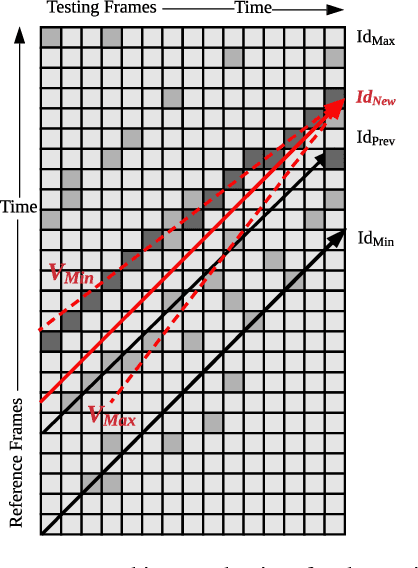
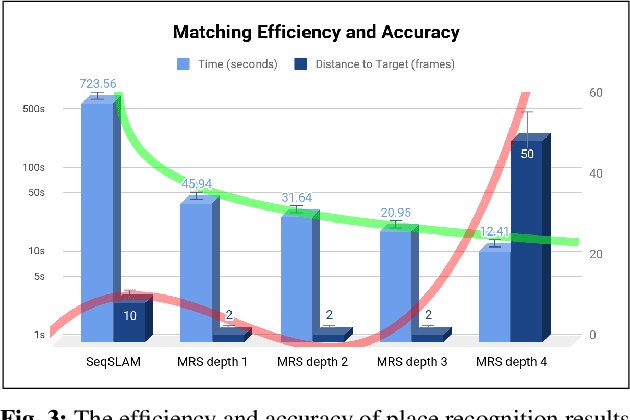
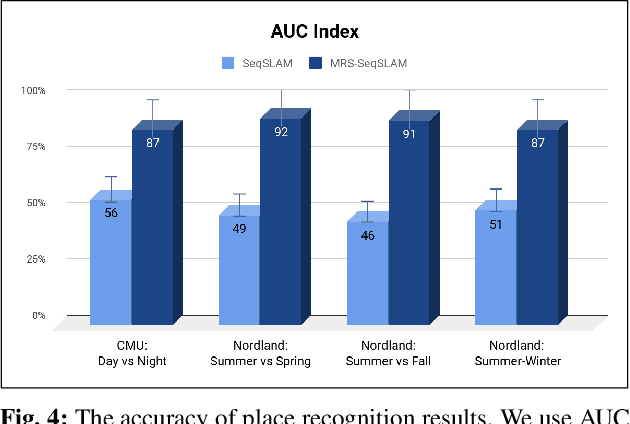
Place recognition and loop closure detection are challenging for long-term visual navigation tasks. SeqSLAM is considered to be one of the most successful approaches to achieving long-term localization under varying environmental conditions and changing viewpoints. It depends on a brute-force, time-consuming sequential matching method. We propose MRS-VPR, a multi-resolution, sampling-based place recognition method, which can significantly improve the matching efficiency and accuracy in sequential matching. The novelty of this method lies in the coarse-to-fine searching pipeline and a particle filter-based global sampling scheme, that can balance the matching efficiency and accuracy in the long-term navigation task. Moreover, our model works much better than SeqSLAM when the testing sequence has a much smaller scale than the reference sequence. Our experiments demonstrate that the proposed method is efficient in locating short temporary trajectories within long-term reference ones without losing accuracy compared to SeqSLAM.
A Multi-Domain Feature Learning Method for Visual Place Recognition
Feb 26, 2019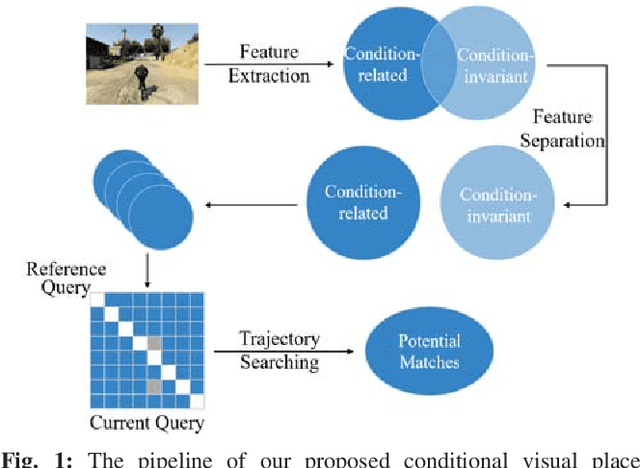
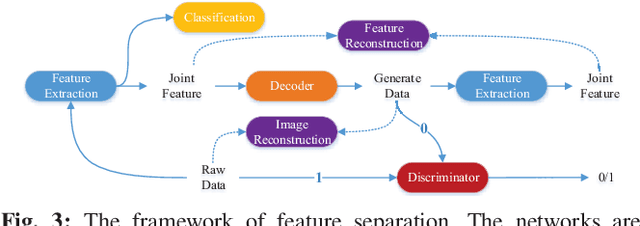
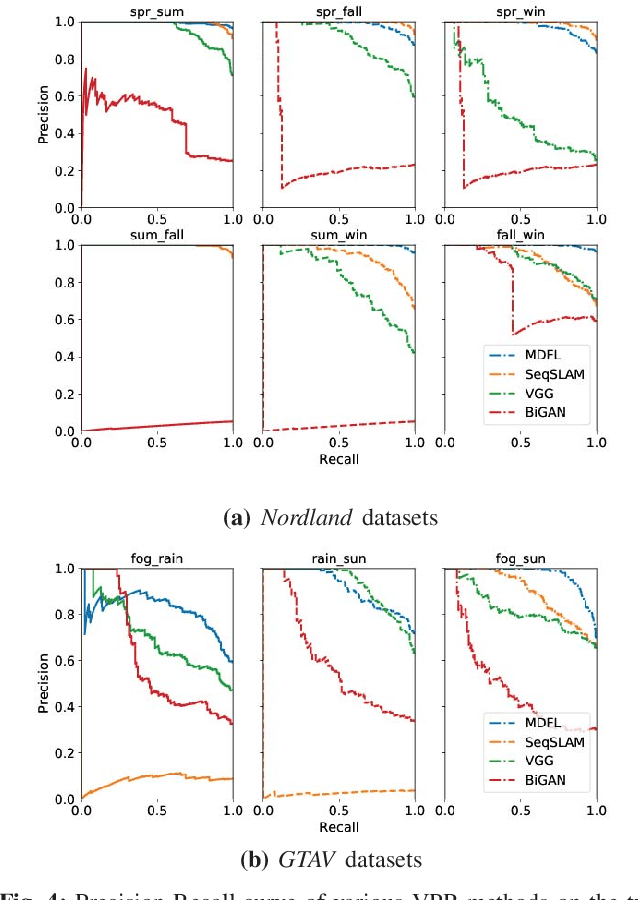
Visual Place Recognition (VPR) is an important component in both computer vision and robotics applications, thanks to its ability to determine whether a place has been visited and where specifically. A major challenge in VPR is to handle changes of environmental conditions including weather, season and illumination. Most VPR methods try to improve the place recognition performance by ignoring the environmental factors, leading to decreased accuracy decreases when environmental conditions change significantly, such as day versus night. To this end, we propose an end-to-end conditional visual place recognition method. Specifically, we introduce the multi-domain feature learning method (MDFL) to capture multiple attribute-descriptions for a given place, and then use a feature detaching module to separate the environmental condition-related features from those that are not. The only label required within this feature learning pipeline is the environmental condition. Evaluation of the proposed method is conducted on the multi-season \textit{NORDLAND} dataset, and the multi-weather \textit{GTAV} dataset. Experimental results show that our method improves the feature robustness against variant environmental conditions.
Synchronous Adversarial Feature Learning for LiDAR based Loop Closure Detection
Apr 05, 2018
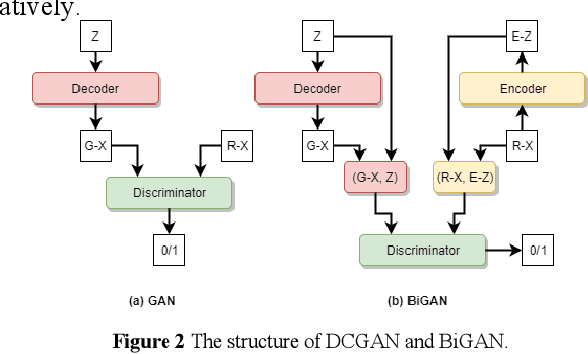
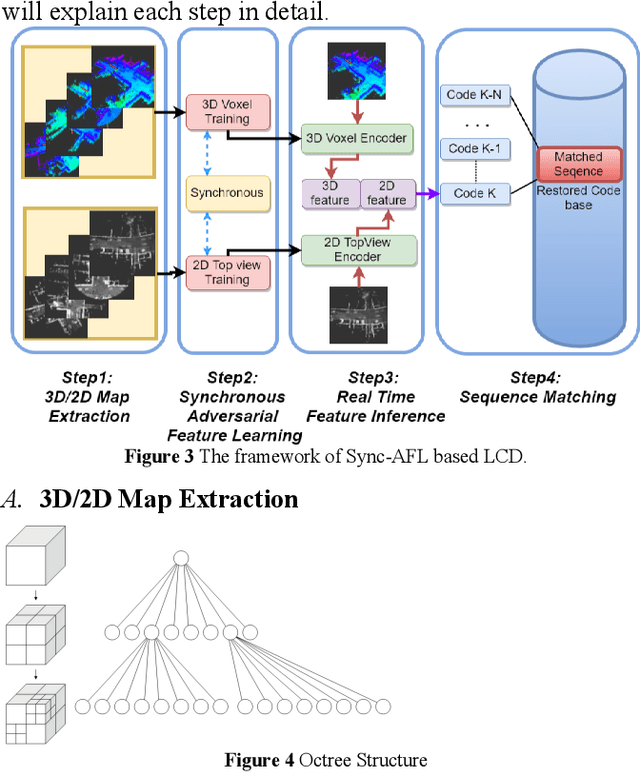
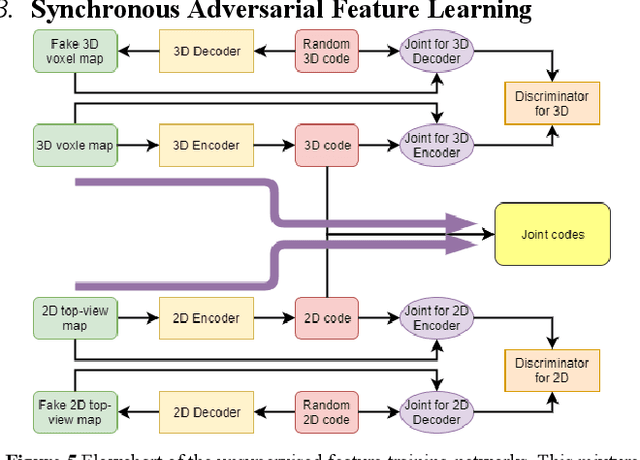
Loop Closure Detection (LCD) is the essential module in the simultaneous localization and mapping (SLAM) task. In the current appearance-based SLAM methods, the visual inputs are usually affected by illumination, appearance and viewpoints changes. Comparing to the visual inputs, with the active property, light detection and ranging (LiDAR) based point-cloud inputs are invariant to the illumination and appearance changes. In this paper, we extract 3D voxel maps and 2D top view maps from LiDAR inputs, and the former could capture the local geometry into a simplified 3D voxel format, the later could capture the local road structure into a 2D image format. However, the most challenge problem is to obtain efficient features from 3D and 2D maps to against the viewpoints difference. In this paper, we proposed a synchronous adversarial feature learning method for the LCD task, which could learn the higher level abstract features from different domains without any label data. To the best of our knowledge, this work is the first to extract multi-domain adversarial features for the LCD task in real time. To investigate the performance, we test the proposed method on the KITTI odometry dataset. The extensive experiments results show that, the proposed method could largely improve LCD accuracy even under huge viewpoints differences.