 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLinlin Li
High-resolution tomographic reconstruction of optical absorbance through scattering media using neural fields
Apr 04, 2023




Light scattering imposes a major obstacle for imaging objects seated deeply in turbid media, such as biological tissues and foggy air. Diffuse optical tomography (DOT) tackles scattering by volumetrically recovering the optical absorbance and has shown significance in medical imaging, remote sensing and autonomous driving. A conventional DOT reconstruction paradigm necessitates discretizing the object volume into voxels at a pre-determined resolution for modelling diffuse light propagation and the resulting spatial resolution of the reconstruction is generally limited. We propose NeuDOT, a novel DOT scheme based on neural fields (NF) to continuously encode the optical absorbance within the volume and subsequently bridge the gap between model accuracy and high resolution. Comprehensive experiments demonstrate that NeuDOT achieves submillimetre lateral resolution and resolves complex 3D objects at 14 mm-depth, outperforming the state-of-the-art methods. NeuDOT is a non-invasive, high-resolution and computationally efficient tomographic method, and unlocks further applications of NF involving light scattering.
Efficient Image Captioning for Edge Devices
Dec 18, 2022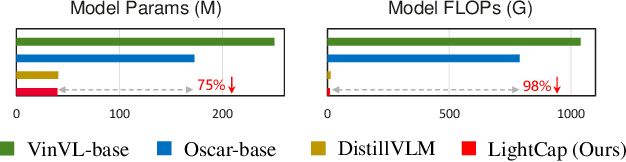
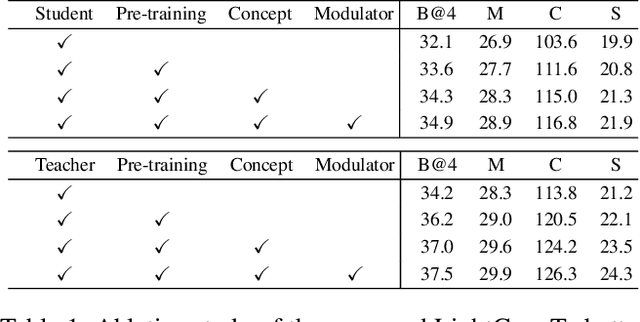
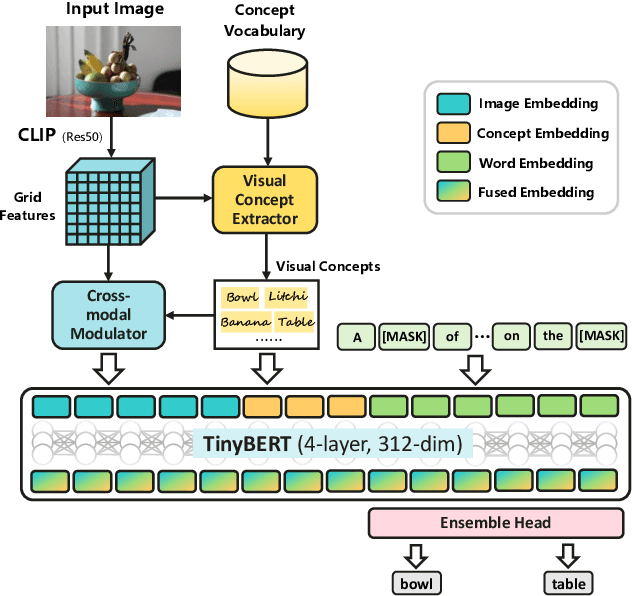
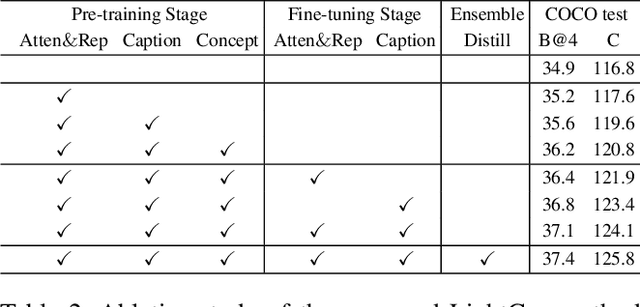
Recent years have witnessed the rapid progress of image captioning. However, the demands for large memory storage and heavy computational burden prevent these captioning models from being deployed on mobile devices. The main obstacles lie in the heavyweight visual feature extractors (i.e., object detectors) and complicated cross-modal fusion networks. To this end, we propose LightCap, a lightweight image captioner for resource-limited devices. The core design is built on the recent CLIP model for efficient image captioning. To be specific, on the one hand, we leverage the CLIP model to extract the compact grid features without relying on the time-consuming object detectors. On the other hand, we transfer the image-text retrieval design of CLIP to image captioning scenarios by devising a novel visual concept extractor and a cross-modal modulator. We further optimize the cross-modal fusion model and parallel prediction heads via sequential and ensemble distillations. With the carefully designed architecture, our model merely contains 40M parameters, saving the model size by more than 75% and the FLOPs by more than 98% in comparison with the current state-of-the-art methods. In spite of the low capacity, our model still exhibits state-of-the-art performance on prevalent datasets, e.g., 136.6 CIDEr on COCO Karpathy test split. Testing on the smartphone with only a single CPU, the proposed LightCap exhibits a fast inference speed of 188ms per image, which is ready for practical applications.
Controllable Image Captioning via Prompting
Dec 04, 2022



Despite the remarkable progress of image captioning, existing captioners typically lack the controllable capability to generate desired image captions, e.g., describing the image in a rough or detailed manner, in a factual or emotional view, etc. In this paper, we show that a unified model is qualified to perform well in diverse domains and freely switch among multiple styles. Such a controllable capability is achieved by embedding the prompt learning into the image captioning framework. To be specific, we design a set of prompts to fine-tune the pre-trained image captioner. These prompts allow the model to absorb stylized data from different domains for joint training, without performance degradation in each domain. Furthermore, we optimize the prompts with learnable vectors in the continuous word embedding space, avoiding the heuristic prompt engineering and meanwhile exhibiting superior performance. In the inference stage, our model is able to generate desired stylized captions by choosing the corresponding prompts. Extensive experiments verify the controllable capability of the proposed method. Notably, we achieve outstanding performance on two diverse image captioning benchmarks including COCO Karpathy split and TextCaps using a unified model.
PDE-constrained shape registration to characterize biological growth and morphogenesis from imaging data
Apr 05, 2022



We propose a PDE-constrained shape registration algorithm that captures the deformation and growth of biological tissue from imaging data. Shape registration is the process of evaluating optimum alignment between pairs of geometries through a spatial transformation function. We start from our previously reported work, which uses 3D tensor product B-spline basis functions to interpolate 3D space. Here, the movement of the B-spline control points, composed with an implicit function describing the shape of the tissue, yields the total deformation gradient field. The deformation gradient is then split into growth and elastic contributions. The growth tensor captures addition of mass, i.e. growth, and evolves according to a constitutive equation which is usually a function of the elastic deformation. Stress is generated in the material due to the elastic component of the deformation alone. The result of the registration is obtained by minimizing a total energy functional which includes: a distance measure reflecting similarity between the shapes, and the total elastic energy accounting for the growth of the tissue. We apply the proposed shape registration framework to study zebrafish embryo epiboly process and tissue expansion during skin reconstruction surgery. We anticipate that our PDE-constrained shape registration method will improve our understanding of biological and medical problems in which tissues undergo extreme deformations over time.
Text is no more Enough! A Benchmark for Profile-based Spoken Language Understanding
Jan 12, 2022



Current researches on spoken language understanding (SLU) heavily are limited to a simple setting: the plain text-based SLU that takes the user utterance as input and generates its corresponding semantic frames (e.g., intent and slots). Unfortunately, such a simple setting may fail to work in complex real-world scenarios when an utterance is semantically ambiguous, which cannot be achieved by the text-based SLU models. In this paper, we first introduce a new and important task, Profile-based Spoken Language Understanding (ProSLU), which requires the model that not only relies on the plain text but also the supporting profile information to predict the correct intents and slots. To this end, we further introduce a large-scale human-annotated Chinese dataset with over 5K utterances and their corresponding supporting profile information (Knowledge Graph (KG), User Profile (UP), Context Awareness (CA)). In addition, we evaluate several state-of-the-art baseline models and explore a multi-level knowledge adapter to effectively incorporate profile information. Experimental results reveal that all existing text-based SLU models fail to work when the utterances are semantically ambiguous and our proposed framework can effectively fuse the supporting information for sentence-level intent detection and token-level slot filling. Finally, we summarize key challenges and provide new points for future directions, which hopes to facilitate the research.
DyLex: Incorporating Dynamic Lexicons into BERT for Sequence Labeling
Sep 22, 2021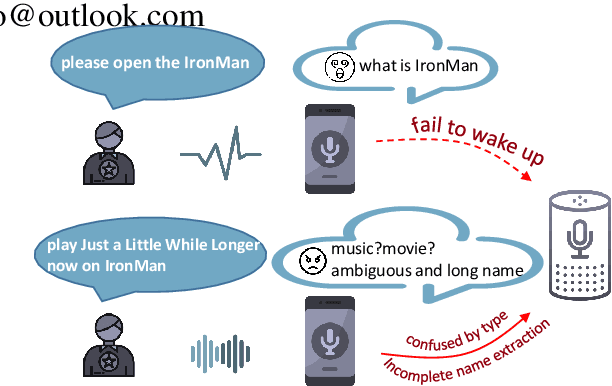

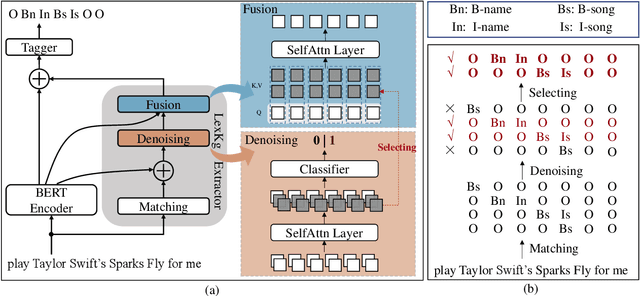
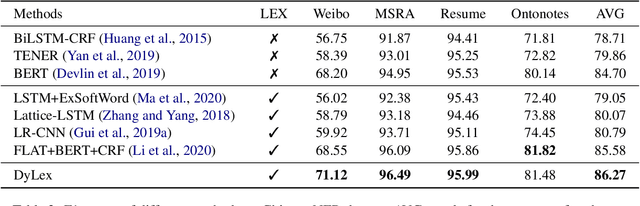
Incorporating lexical knowledge into deep learning models has been proved to be very effective for sequence labeling tasks. However, previous works commonly have difficulty dealing with large-scale dynamic lexicons which often cause excessive matching noise and problems of frequent updates. In this paper, we propose DyLex, a plug-in lexicon incorporation approach for BERT based sequence labeling tasks. Instead of leveraging embeddings of words in the lexicon as in conventional methods, we adopt word-agnostic tag embeddings to avoid re-training the representation while updating the lexicon. Moreover, we employ an effective supervised lexical knowledge denoising method to smooth out matching noise. Finally, we introduce a col-wise attention based knowledge fusion mechanism to guarantee the pluggability of the proposed framework. Experiments on ten datasets of three tasks show that the proposed framework achieves new SOTA, even with very large scale lexicons.
LightMBERT: A Simple Yet Effective Method for Multilingual BERT Distillation
Mar 11, 2021



The multilingual pre-trained language models (e.g, mBERT, XLM and XLM-R) have shown impressive performance on cross-lingual natural language understanding tasks. However, these models are computationally intensive and difficult to be deployed on resource-restricted devices. In this paper, we propose a simple yet effective distillation method (LightMBERT) for transferring the cross-lingual generalization ability of the multilingual BERT to a small student model. The experiment results empirically demonstrate the efficiency and effectiveness of LightMBERT, which is significantly better than the baselines and performs comparable to the teacher mBERT.
Improving Task-Agnostic BERT Distillation with Layer Mapping Search
Dec 11, 2020



Knowledge distillation (KD) which transfers the knowledge from a large teacher model to a small student model, has been widely used to compress the BERT model recently. Besides the supervision in the output in the original KD, recent works show that layer-level supervision is crucial to the performance of the student BERT model. However, previous works designed the layer mapping strategy heuristically (e.g., uniform or last-layer), which can lead to inferior performance. In this paper, we propose to use the genetic algorithm (GA) to search for the optimal layer mapping automatically. To accelerate the search process, we further propose a proxy setting where a small portion of the training corpus are sampled for distillation, and three representative tasks are chosen for evaluation. After obtaining the optimal layer mapping, we perform the task-agnostic BERT distillation with it on the whole corpus to build a compact student model, which can be directly fine-tuned on downstream tasks. Comprehensive experiments on the evaluation benchmarks demonstrate that 1) layer mapping strategy has a significant effect on task-agnostic BERT distillation and different layer mappings can result in quite different performances; 2) the optimal layer mapping strategy from the proposed search process consistently outperforms the other heuristic ones; 3) with the optimal layer mapping, our student model achieves state-of-the-art performance on the GLUE tasks.
TinyBERT: Distilling BERT for Natural Language Understanding
Sep 24, 2019



Language model pre-training, such as BERT, has significantly improved the performances of many natural language processing tasks. However, pre-trained language models are usually computationally expensive and memory intensive, so it is difficult to effectively execute them on some resource-restricted devices. To accelerate inference and reduce model size while maintaining accuracy, we firstly propose a novel transformer distillation method that is a specially designed knowledge distillation (KD) method for transformer-based models. By leveraging this new KD method, the plenty of knowledge encoded in a large teacher BERT can be well transferred to a small student TinyBERT. Moreover, we introduce a new two-stage learning framework for TinyBERT, which performs transformer distillation at both the pre-training and task-specific learning stages. This framework ensures that TinyBERT can capture both the general-domain and task-specific knowledge of the teacher BERT. TinyBERT is empirically effective and achieves comparable results with BERT in GLUE datasets, while being 7.5x smaller and 9.4x faster on inference. TinyBERT is also significantly better than state-of-the-art baselines, even with only about 28% parameters and 31% inference time of baselines.
Open Named Entity Modeling from Embedding Distribution
Aug 31, 2019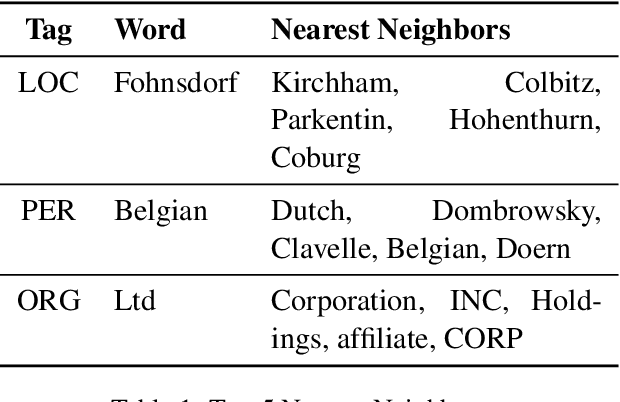
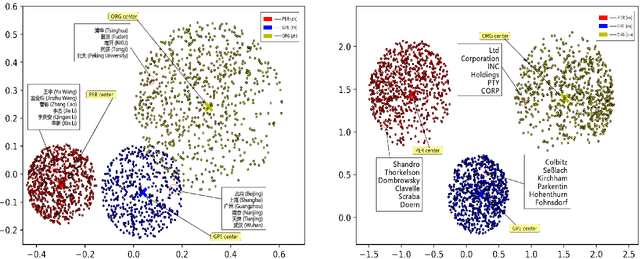

In this paper, we report our discovery on named entity distribution in general word embedding space, which helps an open definition on multilingual named entity definition rather than previous closed and constraint definition on named entities through a named entity dictionary, which is usually derived from huaman labor and replies on schedual update. Our initial visualization of monolingual word embeddings indicates named entities tend to gather together despite of named entity types and language difference, which enable us to model all named entities using a specific geometric structure inside embedding space,namely, the named entity hypersphere. For monolingual case, the proposed named entity model gives an open description on diverse named entity types and different languages. For cross-lingual case, mapping the proposed named entity model provides a novel way to build named entity dataset for resource-poor languages. At last, the proposed named entity model may be shown as a very useful clue to significantly enhance state-of-the-art named entity recognition systems generally.