 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLiqiang Zhang
Fine-Grained Extraction of Road Networks via Joint Learning of Connectivity and Segmentation
Dec 07, 2023
Road network extraction from satellite images is widely applicated in intelligent traffic management and autonomous driving fields. The high-resolution remote sensing images contain complex road areas and distracted background, which make it a challenge for road extraction. In this study, we present a stacked multitask network for end-to-end segmenting roads while preserving connectivity correctness. In the network, a global-aware module is introduced to enhance pixel-level road feature representation and eliminate background distraction from overhead images; a road-direction-related connectivity task is added to ensure that the network preserves the graph-level relationships of the road segments. We also develop a stacked multihead structure to jointly learn and effectively utilize the mutual information between connectivity learning and segmentation learning. We evaluate the performance of the proposed network on three public remote sensing datasets. The experimental results demonstrate that the network outperforms the state-of-the-art methods in terms of road segmentation accuracy and connectivity maintenance.
Deep Learning-based Inertial Odometry for Pedestrian Tracking using Attention Mechanism and Res2Net Module
May 20, 2022



Pedestrian dead reckoning is a challenging task due to the low-cost inertial sensor error accumulation. Recent research has shown that deep learning methods can achieve impressive performance in handling this issue. In this letter, we propose inertial odometry using a deep learning-based velocity estimation method. The deep neural network based on Res2Net modules and two convolutional block attention modules is leveraged to restore the potential connection between the horizontal velocity vector and raw inertial data from a smartphone. Our network is trained using only fifty percent of the public inertial odometry dataset (RoNIN) data. Then, it is validated on the RoNIN testing dataset and another public inertial odometry dataset (OXIOD). Compared with the traditional step-length and heading system-based algorithm, our approach decreases the absolute translation error (ATE) by 76%-86%. In addition, compared with the state-of-the-art deep learning method (RoNIN), our method improves its ATE by 6%-31.4%.
Pedestrian Dead Reckoning System using Quasi-static Magnetic Field Detection
Jan 25, 2022



Kalman filter-based Inertial Navigation System (INS) is a reliable and efficient method to estimate the position of a pedestrian indoors. Classical INS-based methodology which is called IEZ (INS-EKF-ZUPT) makes use of an Extended Kalman Filter (EKF), a Zero velocity UPdaTing (ZUPT) to calculate the position and attitude of a person. However, heading error which is a key factor of the whole Pedestrian Dead Reckoning (PDR) system is unobservable for IEZ-based PDR system. To minimize the error, Electronic Com-pass (EC) algorithm becomes a valid method. But magnetic disturbance may have a big negative effect on it. In this paper, the Quasi-static Magnetic field Detection (QMD) method is proposed to detect the pure magnetic field and then selects EC algorithm or Heuristic heading Drift Reduction algorithm (HDR) according to the detection result, which implements the complementation of the two methods. Meanwhile, the QMD, EC, and HDR algorithms are integrated into the IEZ framework to form a new PDR solution which is named Advanced IEZ (AIEZ).
Ghost-dil-NetVLAD: A Lightweight Neural Network for Visual Place Recognition
Dec 22, 2021



Visual place recognition (VPR) is a challenging task with the unbalance between enormous computational cost and high recognition performance. Thanks to the practical feature extraction ability of the lightweight convolution neural networks (CNNs) and the train-ability of the vector of locally aggregated descriptors (VLAD) layer, we propose a lightweight weakly supervised end-to-end neural network consisting of a front-ended perception model called GhostCNN and a learnable VLAD layer as a back-end. GhostCNN is based on Ghost modules that are lightweight CNN-based architectures. They can generate redundant feature maps using linear operations instead of the traditional convolution process, making a good trade-off between computation resources and recognition accuracy. To enhance our proposed lightweight model further, we add dilated convolutions to the Ghost module to get features containing more spatial semantic information, improving accuracy. Finally, rich experiments conducted on a commonly used public benchmark and our private dataset validate that the proposed neural network reduces the FLOPs and parameters of VGG16-NetVLAD by 99.04% and 80.16%, respectively. Besides, both models achieve similar accuracy.
DML-GANR: Deep Metric Learning With Generative Adversarial Network Regularization for High Spatial Resolution Remote Sensing Image Retrieval
Oct 07, 2020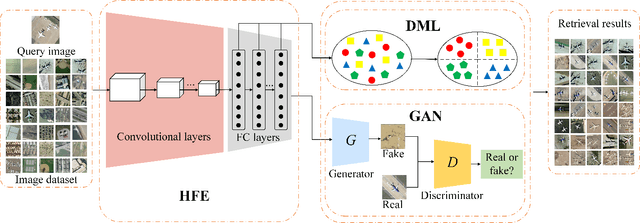


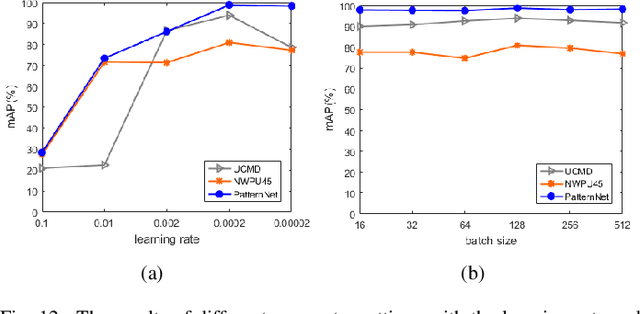
With a small number of labeled samples for training, it can save considerable manpower and material resources, especially when the amount of high spatial resolution remote sensing images (HSR-RSIs) increases considerably. However, many deep models face the problem of overfitting when using a small number of labeled samples. This might degrade HSRRSI retrieval accuracy. Aiming at obtaining more accurate HSR-RSI retrieval performance with small training samples, we develop a deep metric learning approach with generative adversarial network regularization (DML-GANR) for HSR-RSI retrieval. The DML-GANR starts from a high-level feature extraction (HFE) to extract high-level features, which includes convolutional layers and fully connected (FC) layers. Each of the FC layers is constructed by deep metric learning (DML) to maximize the interclass variations and minimize the intraclass variations. The generative adversarial network (GAN) is adopted to mitigate the overfitting problem and validate the qualities of extracted high-level features. DML-GANR is optimized through a customized approach, and the optimal parameters are obtained. The experimental results on the three data sets demonstrate the superior performance of DML-GANR over state-of-the-art techniques in HSR-RSI retrieval.
SLCRF: Subspace Learning with Conditional Random Field for Hyperspectral Image Classification
Oct 07, 2020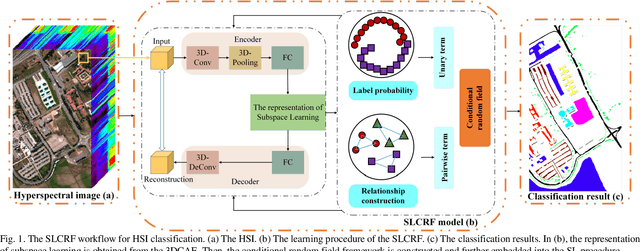

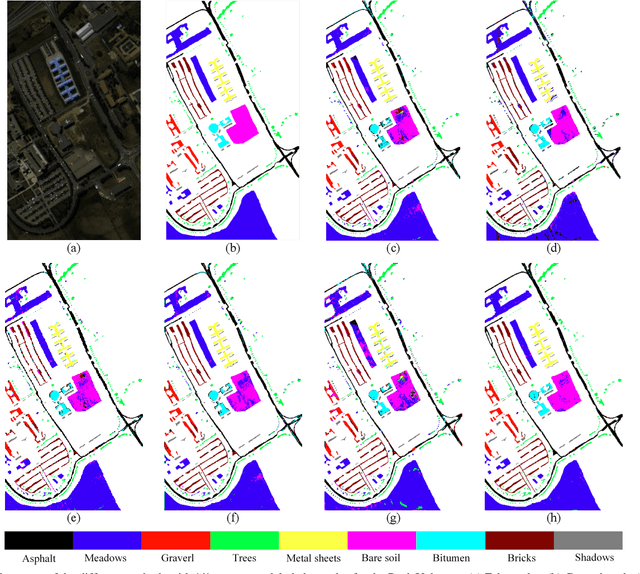
Subspace learning (SL) plays an important role in hyperspectral image (HSI) classification, since it can provide an effective solution to reduce the redundant information in the image pixels of HSIs. Previous works about SL aim to improve the accuracy of HSI recognition. Using a large number of labeled samples, related methods can train the parameters of the proposed solutions to obtain better representations of HSI pixels. However, the data instances may not be sufficient enough to learn a precise model for HSI classification in real applications. Moreover, it is well-known that it takes much time, labor and human expertise to label HSI images. To avoid the aforementioned problems, a novel SL method that includes the probability assumption called subspace learning with conditional random field (SLCRF) is developed. In SLCRF, first, the 3D convolutional autoencoder (3DCAE) is introduced to remove the redundant information in HSI pixels. In addition, the relationships are also constructed using the spectral-spatial information among the adjacent pixels. Then, the conditional random field (CRF) framework can be constructed and further embedded into the HSI SL procedure with the semi-supervised approach. Through the linearized alternating direction method termed LADMAP, the objective function of SLCRF is optimized using a defined iterative algorithm. The proposed method is comprehensively evaluated using the challenging public HSI datasets. We can achieve stateof-the-art performance using these HSI sets.
MLRSNet: A Multi-label High Spatial Resolution Remote Sensing Dataset for Semantic Scene Understanding
Oct 01, 2020



To better understand scene images in the field of remote sensing, multi-label annotation of scene images is necessary. Moreover, to enhance the performance of deep learning models for dealing with semantic scene understanding tasks, it is vital to train them on large-scale annotated data. However, most existing datasets are annotated by a single label, which cannot describe the complex remote sensing images well because scene images might have multiple land cover classes. Few multi-label high spatial resolution remote sensing datasets have been developed to train deep learning models for multi-label based tasks, such as scene classification and image retrieval. To address this issue, in this paper, we construct a multi-label high spatial resolution remote sensing dataset named MLRSNet for semantic scene understanding with deep learning from the overhead perspective. It is composed of high-resolution optical satellite or aerial images. MLRSNet contains a total of 109,161 samples within 46 scene categories, and each image has at least one of 60 predefined labels. We have designed visual recognition tasks, including multi-label based image classification and image retrieval, in which a wide variety of deep learning approaches are evaluated with MLRSNet. The experimental results demonstrate that MLRSNet is a significant benchmark for future research, and it complements the current widely used datasets such as ImageNet, which fills gaps in multi-label image research. Furthermore, we will continue to expand the MLRSNet. MLRSNet and all related materials have been made publicly available at https://data.mendeley.com/datasets/7j9bv9vwsx/2 and https://github.com/cugbrs/MLRSNet.git.
Peking Opera Synthesis via Duration Informed Attention Network
Aug 07, 2020



Peking Opera has been the most dominant form of Chinese performing art since around 200 years ago. A Peking Opera singer usually exhibits a very strong personal style via introducing improvisation and expressiveness on stage which leads the actual rhythm and pitch contour to deviate significantly from the original music score. This inconsistency poses a great challenge in Peking Opera singing voice synthesis from a music score. In this work, we propose to deal with this issue and synthesize expressive Peking Opera singing from the music score based on the Duration Informed Attention Network (DurIAN) framework. To tackle the rhythm mismatch, Lagrange multiplier is used to find the optimal output phoneme duration sequence with the constraint of the given note duration from music score. As for the pitch contour mismatch, instead of directly inferring from music score, we adopt a pseudo music score generated from the real singing and feed it as input during training. The experiments demonstrate that with the proposed system we can synthesize Peking Opera singing voice with high-quality timbre, pitch and expressiveness.
Synthesising Expressiveness in Peking Opera via Duration Informed Attention Network
Dec 27, 2019



This paper presents a method that generates expressive singing voice of Peking opera. The synthesis of expressive opera singing usually requires pitch contours to be extracted as the training data, which relies on techniques and is not able to be manually labeled. With the Duration Informed Attention Network (DurIAN), this paper makes use of musical note instead of pitch contours for expressive opera singing synthesis. The proposed method enables human annotation being combined with automatic extracted features to be used as training data thus the proposed method gives extra flexibility in data collection for Peking opera singing synthesis. Comparing with the expressive singing voice of Peking opera synthesised by pitch contour based system, the proposed musical note based system produces comparable singing voice in Peking opera with expressiveness in various aspects.
Learning Singing From Speech
Dec 20, 2019


We propose an algorithm that is capable of synthesizing high quality target speaker's singing voice given only their normal speech samples. The proposed algorithm first integrate speech and singing synthesis into a unified framework, and learns universal speaker embeddings that are shareable between speech and singing synthesis tasks. Specifically, the speaker embeddings learned from normal speech via the speech synthesis objective are shared with those learned from singing samples via the singing synthesis objective in the unified training framework. This makes the learned speaker embedding a transferable representation for both speaking and singing. We evaluate the proposed algorithm on singing voice conversion task where the content of original singing is covered with the timbre of another speaker's voice learned purely from their normal speech samples. Our experiments indicate that the proposed algorithm generates high-quality singing voices that sound highly similar to target speaker's voice given only his or her normal speech samples. We believe that proposed algorithm will open up new opportunities for singing synthesis and conversion for broader users and applications.